 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Underestimates the Readiness of Multi-lingual Dialogue Agents
May 28, 2024



Creating multilingual task-oriented dialogue (TOD) agents is challenging due to the high cost of training data acquisition. Following the research trend of improving training data efficiency, we show for the first time, that in-context learning is sufficient to tackle multilingual TOD. To handle the challenging dialogue state tracking (DST) subtask, we break it down to simpler steps that are more compatible with in-context learning where only a handful of few-shot examples are used. We test our approach on the multilingual TOD dataset X-RiSAWOZ, which has 12 domains in Chinese, English, French, Korean, Hindi, and code-mixed Hindi-English. Our turn-by-turn DST accuracy on the 6 languages range from 55.6% to 80.3%, seemingly worse than the SOTA results from fine-tuned models that achieve from 60.7% to 82.8%; our BLEU scores in the response generation (RG) subtask are also significantly lower than SOTA. However, after manual evaluation of the validation set, we find that by correcting gold label errors and improving dataset annotation schema, GPT-4 with our prompts can achieve (1) 89.6%-96.8% accuracy in DST, and (2) more than 99% correct response generation across different languages. This leads us to conclude that current automatic metrics heavily underestimate the effectiveness of in-context learning.
From Human Judgements to Predictive Models: Unravelling Acceptability in Code-Mixed Sentences
May 09, 2024



Current computational approaches for analysing or generating code-mixed sentences do not explicitly model "naturalness" or "acceptability" of code-mixed sentences, but rely on training corpora to reflect distribution of acceptable code-mixed sentences. Modelling human judgement for the acceptability of code-mixed text can help in distinguishing natural code-mixed text and enable quality-controlled generation of code-mixed text. To this end, we construct Cline - a dataset containing human acceptability judgements for English-Hindi (en-hi) code-mixed text. Cline is the largest of its kind with 16,642 sentences, consisting of samples sourced from two sources: synthetically generated code-mixed text and samples collected from online social media. Our analysis establishes that popular code-mixing metrics such as CMI, Number of Switch Points, Burstines, which are used to filter/curate/compare code-mixed corpora have low correlation with human acceptability judgements, underlining the necessity of our dataset. Experiments using Cline demonstrate that simple Multilayer Perceptron (MLP) models trained solely on code-mixing metrics are outperformed by fine-tuned pre-trained Multilingual Large Language Models (MLLMs). Specifically, XLM-Roberta and Bernice outperform IndicBERT across different configurations in challenging data settings. Comparison with ChatGPT's zero and fewshot capabilities shows that MLLMs fine-tuned on larger data outperform ChatGPT, providing scope for improvement in code-mixed tasks. Zero-shot transfer from English-Hindi to English-Telugu acceptability judgments using our model checkpoints proves superior to random baselines, enabling application to other code-mixed language pairs and providing further avenues of research. We publicly release our human-annotated dataset, trained checkpoints, code-mix corpus, and code for data generation and model training.
X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents
Jun 30, 2023



Task-oriented dialogue research has mainly focused on a few popular languages like English and Chinese, due to the high dataset creation cost for a new language. To reduce the cost, we apply manual editing to automatically translated data. We create a new multilingual benchmark, X-RiSAWOZ, by translating the Chinese RiSAWOZ to 4 languages: English, French, Hindi, Korean; and a code-mixed English-Hindi language. X-RiSAWOZ has more than 18,000 human-verified dialogue utterances for each language, and unlike most multilingual prior work, is an end-to-end dataset for building fully-functioning agents. The many difficulties we encountered in creating X-RiSAWOZ led us to develop a toolset to accelerate the post-editing of a new language dataset after translation. This toolset improves machine translation with a hybrid entity alignment technique that combines neural with dictionary-based methods, along with many automated and semi-automated validation checks. We establish strong baselines for X-RiSAWOZ by training dialogue agents in the zero- and few-shot settings where limited gold data is available in the target language. Our results suggest that our translation and post-editing methodology and toolset can be used to create new high-quality multilingual dialogue agents cost-effectively. Our dataset, code, and toolkit are released open-source.
PreCogIIITH at HinglishEval : Leveraging Code-Mixing Metrics & Language Model Embeddings To Estimate Code-Mix Quality
Jun 16, 2022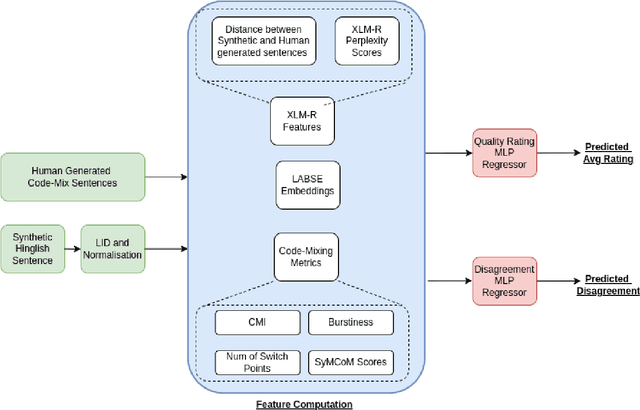

Code-Mixing is a phenomenon of mixing two or more languages in a speech event and is prevalent in multilingual societies. Given the low-resource nature of Code-Mixing, machine generation of code-mixed text is a prevalent approach for data augmentation. However, evaluating the quality of such machine generated code-mixed text is an open problem. In our submission to HinglishEval, a shared-task collocated with INLG2022, we attempt to build models factors that impact the quality of synthetically generated code-mix text by predicting ratings for code-mix quality.
HashSet -- A Dataset For Hashtag Segmentation
Jan 18, 2022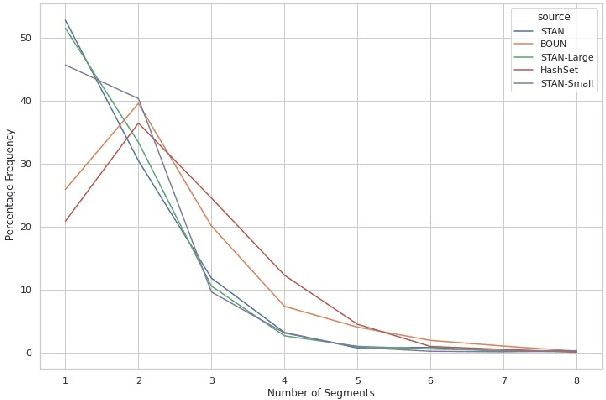
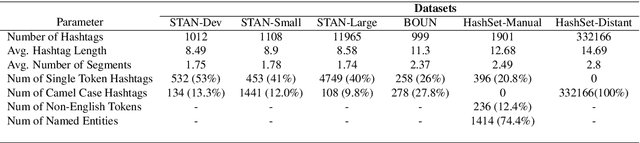
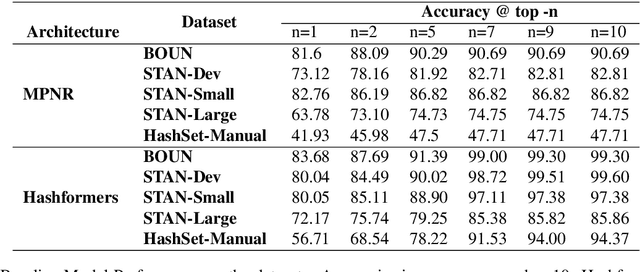

Hashtag segmentation is the task of breaking a hashtag into its constituent tokens. Hashtags often encode the essence of user-generated posts, along with information like topic and sentiment, which are useful in downstream tasks. Hashtags prioritize brevity and are written in unique ways -- transliterating and mixing languages, spelling variations, creative named entities. Benchmark datasets used for the hashtag segmentation task -- STAN, BOUN -- are small in size and extracted from a single set of tweets. However, datasets should reflect the variations in writing styles of hashtags and also account for domain and language specificity, failing which the results will misrepresent model performance. We argue that model performance should be assessed on a wider variety of hashtags, and datasets should be carefully curated. To this end, we propose HashSet, a dataset comprising of: a) 1.9k manually annotated dataset; b) 3.3M loosely supervised dataset. HashSet dataset is sampled from a different set of tweets when compared to existing datasets and provides an alternate distribution of hashtags to build and validate hashtag segmentation models. We show that the performance of SOTA models for Hashtag Segmentation drops substantially on proposed dataset, indicating that the proposed dataset provides an alternate set of hashtags to train and assess models.
Battling Hateful Content in Indic Languages HASOC '21
Nov 05, 2021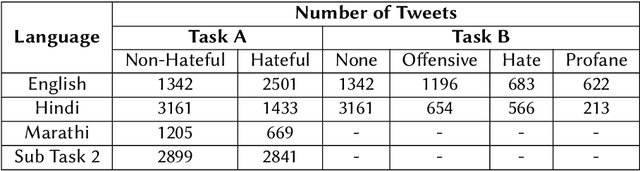
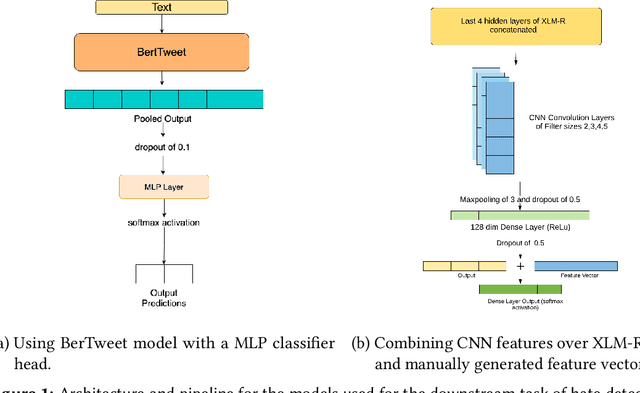
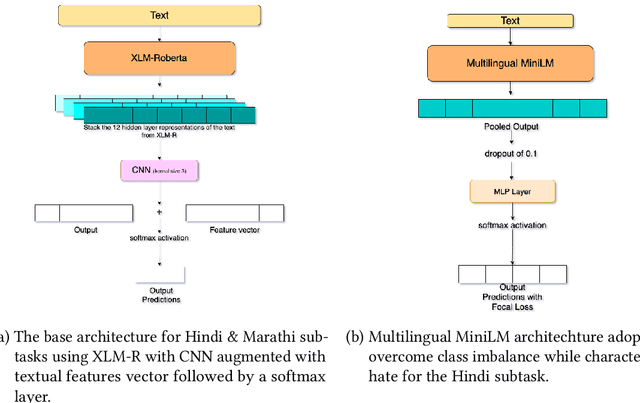
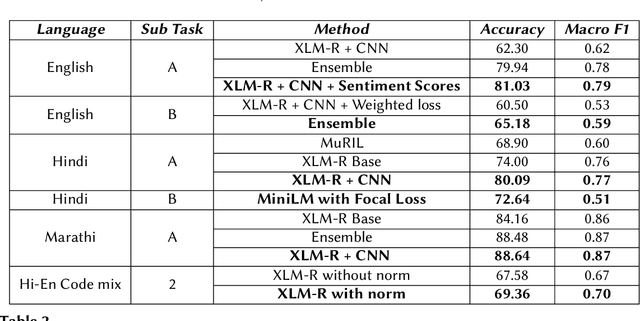
The extensive rise in consumption of online social media (OSMs) by a large number of people poses a critical problem of curbing the spread of hateful content on these platforms. With the growing usage of OSMs in multiple languages, the task of detecting and characterizing hate becomes more complex. The subtle variations of code-mixed texts along with switching scripts only add to the complexity. This paper presents a solution for the HASOC 2021 Multilingual Twitter Hate-Speech Detection challenge by team PreCog IIIT Hyderabad. We adopt a multilingual transformer based approach and describe our architecture for all 6 subtasks as part of the challenge. Out of the 6 teams that participated in all the subtasks, our submissions rank 3rd overall.