 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow DDAIR you? Disambiguated Data Augmentation for Intent Recognition
Jan 16, 2026Large Language Models (LLMs) are effective for data augmentation in classification tasks like intent detection. In some cases, they inadvertently produce examples that are ambiguous with regard to untargeted classes. We present DDAIR (Disambiguated Data Augmentation for Intent Recognition) to mitigate this problem. We use Sentence Transformers to detect ambiguous class-guided augmented examples generated by LLMs for intent recognition in low-resource scenarios. We identify synthetic examples that are semantically more similar to another intent than to their target one. We also provide an iterative re-generation method to mitigate such ambiguities. Our findings show that sentence embeddings effectively help to (re)generate less ambiguous examples, and suggest promising potential to improve classification performance in scenarios where intents are loosely or broadly defined.
Intent Recognition and Out-of-Scope Detection using LLMs in Multi-party Conversations
Jul 29, 2025Intent recognition is a fundamental component in task-oriented dialogue systems (TODS). Determining user intents and detecting whether an intent is Out-of-Scope (OOS) is crucial for TODS to provide reliable responses. However, traditional TODS require large amount of annotated data. In this work we propose a hybrid approach to combine BERT and LLMs in zero and few-shot settings to recognize intents and detect OOS utterances. Our approach leverages LLMs generalization power and BERT's computational efficiency in such scenarios. We evaluate our method on multi-party conversation corpora and observe that sharing information from BERT outputs to LLMs leads to system performance improvement.
From LIMA to DeepLIMA: following a new path of interoperability
Sep 10, 2024In this article, we describe the architecture of the LIMA (Libre Multilingual Analyzer) framework and its recent evolution with the addition of new text analysis modules based on deep neural networks. We extended the functionality of LIMA in terms of the number of supported languages while preserving existing configurable architecture and the availability of previously developed rule-based and statistical analysis components. Models were trained for more than 60 languages on the Universal Dependencies 2.5 corpora, WikiNer corpora, and CoNLL-03 dataset. Universal Dependencies allowed us to increase the number of supported languages and to generate models that could be integrated into other platforms. This integration of ubiquitous Deep Learning Natural Language Processing models and the use of standard annotated collections using Universal Dependencies can be viewed as a new path of interoperability, through the normalization of models and data, that are complementary to a more standard technical interoperability, implemented in LIMA through services available in Docker containers on Docker Hub.
Benchmark Underestimates the Readiness of Multi-lingual Dialogue Agents
May 28, 2024



Creating multilingual task-oriented dialogue (TOD) agents is challenging due to the high cost of training data acquisition. Following the research trend of improving training data efficiency, we show for the first time, that in-context learning is sufficient to tackle multilingual TOD. To handle the challenging dialogue state tracking (DST) subtask, we break it down to simpler steps that are more compatible with in-context learning where only a handful of few-shot examples are used. We test our approach on the multilingual TOD dataset X-RiSAWOZ, which has 12 domains in Chinese, English, French, Korean, Hindi, and code-mixed Hindi-English. Our turn-by-turn DST accuracy on the 6 languages range from 55.6% to 80.3%, seemingly worse than the SOTA results from fine-tuned models that achieve from 60.7% to 82.8%; our BLEU scores in the response generation (RG) subtask are also significantly lower than SOTA. However, after manual evaluation of the validation set, we find that by correcting gold label errors and improving dataset annotation schema, GPT-4 with our prompts can achieve (1) 89.6%-96.8% accuracy in DST, and (2) more than 99% correct response generation across different languages. This leads us to conclude that current automatic metrics heavily underestimate the effectiveness of in-context learning.
X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents
Jun 30, 2023



Task-oriented dialogue research has mainly focused on a few popular languages like English and Chinese, due to the high dataset creation cost for a new language. To reduce the cost, we apply manual editing to automatically translated data. We create a new multilingual benchmark, X-RiSAWOZ, by translating the Chinese RiSAWOZ to 4 languages: English, French, Hindi, Korean; and a code-mixed English-Hindi language. X-RiSAWOZ has more than 18,000 human-verified dialogue utterances for each language, and unlike most multilingual prior work, is an end-to-end dataset for building fully-functioning agents. The many difficulties we encountered in creating X-RiSAWOZ led us to develop a toolset to accelerate the post-editing of a new language dataset after translation. This toolset improves machine translation with a hybrid entity alignment technique that combines neural with dictionary-based methods, along with many automated and semi-automated validation checks. We establish strong baselines for X-RiSAWOZ by training dialogue agents in the zero- and few-shot settings where limited gold data is available in the target language. Our results suggest that our translation and post-editing methodology and toolset can be used to create new high-quality multilingual dialogue agents cost-effectively. Our dataset, code, and toolkit are released open-source.
Neural Supervised Domain Adaptation by Augmenting Pre-trained Models with Random Units
Jun 09, 2021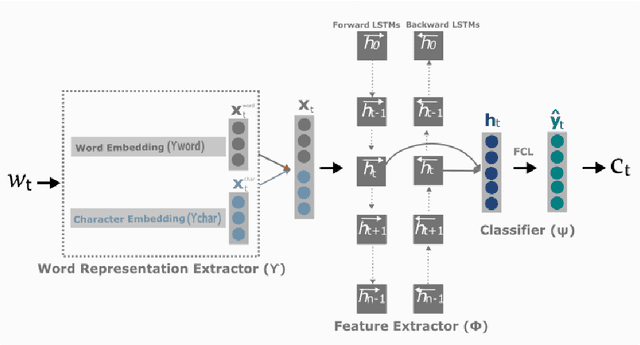
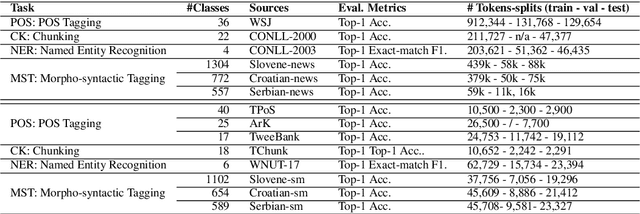
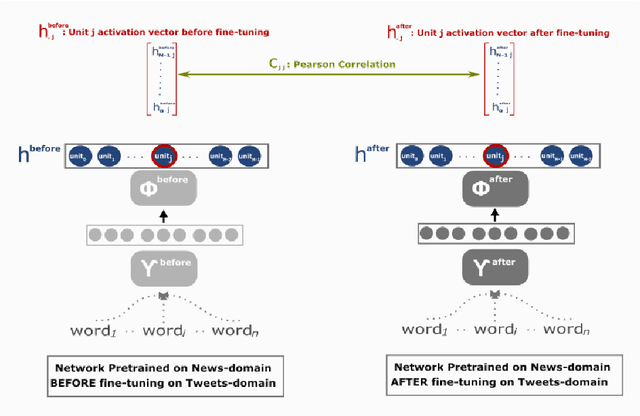

Neural Transfer Learning (TL) is becoming ubiquitous in Natural Language Processing (NLP), thanks to its high performance on many tasks, especially in low-resourced scenarios. Notably, TL is widely used for neural domain adaptation to transfer valuable knowledge from high-resource to low-resource domains. In the standard fine-tuning scheme of TL, a model is initially pre-trained on a source domain and subsequently fine-tuned on a target domain and, therefore, source and target domains are trained using the same architecture. In this paper, we show through interpretation methods that such scheme, despite its efficiency, is suffering from a main limitation. Indeed, although capable of adapting to new domains, pre-trained neurons struggle with learning certain patterns that are specific to the target domain. Moreover, we shed light on the hidden negative transfer occurring despite the high relatedness between source and target domains, which may mitigate the final gain brought by transfer learning. To address these problems, we propose to augment the pre-trained model with normalised, weighted and randomly initialised units that foster a better adaptation while maintaining the valuable source knowledge. We show that our approach exhibits significant improvements to the standard fine-tuning scheme for neural domain adaptation from the news domain to the social media domain on four NLP tasks: part-of-speech tagging, chunking, named entity recognition and morphosyntactic tagging.
Joint Learning of Pre-Trained and Random Units for Domain Adaptation in Part-of-Speech Tagging
Apr 07, 2019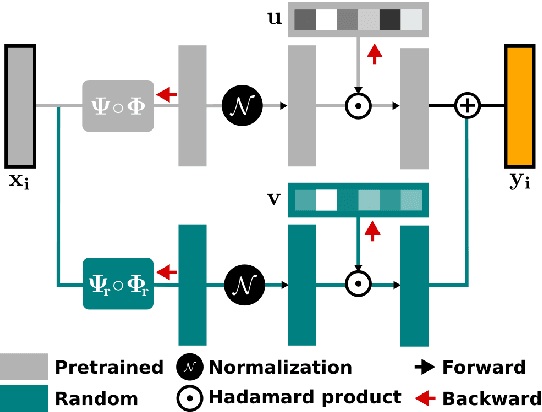
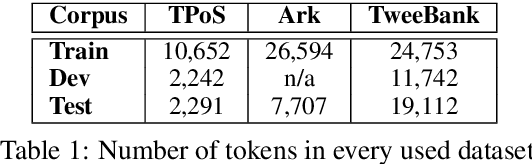
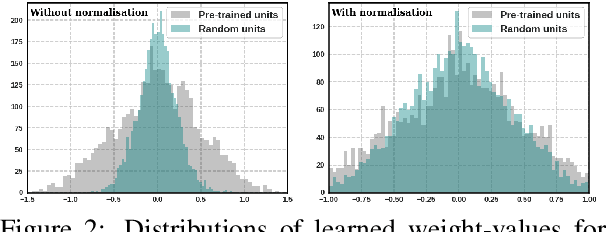
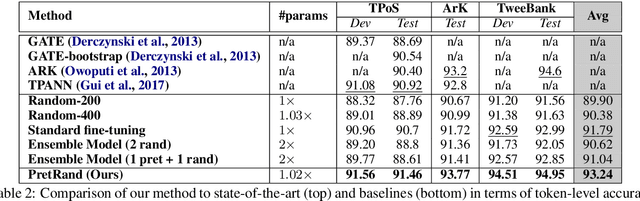
Fine-tuning neural networks is widely used to transfer valuable knowledge from high-resource to low-resource domains. In a standard fine-tuning scheme, source and target problems are trained using the same architecture. Although capable of adapting to new domains, pre-trained units struggle with learning uncommon target-specific patterns. In this paper, we propose to augment the target-network with normalised, weighted and randomly initialised units that beget a better adaptation while maintaining the valuable source knowledge. Our experiments on POS tagging of social media texts (Tweets domain) demonstrate that our method achieves state-of-the-art performances on 3 commonly used datasets.
Inducing Multilingual Text Analysis Tools Using Bidirectional Recurrent Neural Networks
Sep 29, 2016

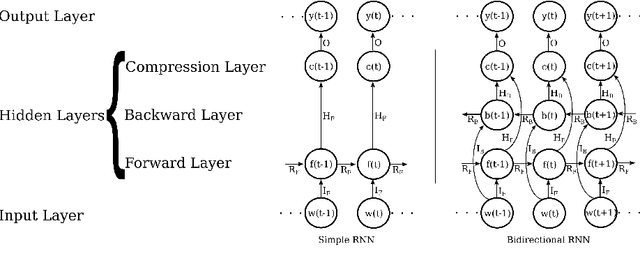

This work focuses on the rapid development of linguistic annotation tools for resource-poor languages. We experiment several cross-lingual annotation projection methods using Recurrent Neural Networks (RNN) models. The distinctive feature of our approach is that our multilingual word representation requires only a parallel corpus between the source and target language. More precisely, our method has the following characteristics: (a) it does not use word alignment information, (b) it does not assume any knowledge about foreign languages, which makes it applicable to a wide range of resource-poor languages, (c) it provides truly multilingual taggers. We investigate both uni- and bi-directional RNN models and propose a method to include external information (for instance low level information from POS) in the RNN to train higher level taggers (for instance, super sense taggers). We demonstrate the validity and genericity of our model by using parallel corpora (obtained by manual or automatic translation). Our experiments are conducted to induce cross-lingual POS and super sense taggers.