 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Transformer-Based Reverse Dictionary Model for Quality Estimation of Definitions
Nov 08, 2023In the last years, several variants of transformers have emerged. In this paper, we compare different transformer-based models for solving the reverse dictionary task and explore their use in the context of a serious game called The Dictionary Game.
Automatic Spell Checker and Correction for Under-represented Spoken Languages: Case Study on Wolof
May 22, 2023This paper presents a spell checker and correction tool specifically designed for Wolof, an under-represented spoken language in Africa. The proposed spell checker leverages a combination of a trie data structure, dynamic programming, and the weighted Levenshtein distance to generate suggestions for misspelled words. We created novel linguistic resources for Wolof, such as a lexicon and a corpus of misspelled words, using a semi-automatic approach that combines manual and automatic annotation methods. Despite the limited data available for the Wolof language, the spell checker's performance showed a predictive accuracy of 98.31% and a suggestion accuracy of 93.33%. Our primary focus remains the revitalization and preservation of Wolof as an Indigenous and spoken language in Africa, providing our efforts to develop novel linguistic resources. This work represents a valuable contribution to the growth of computational tools and resources for the Wolof language and provides a strong foundation for future studies in the automatic spell checking and correction field.
Neural Supervised Domain Adaptation by Augmenting Pre-trained Models with Random Units
Jun 09, 2021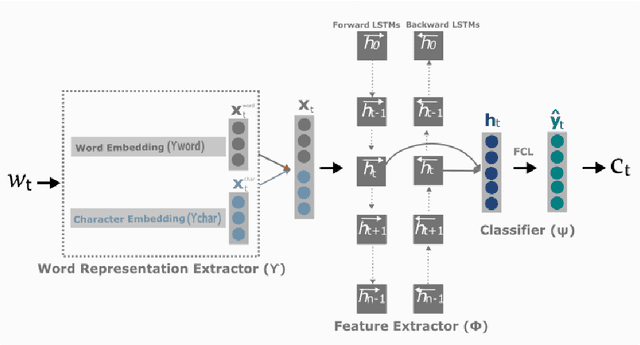
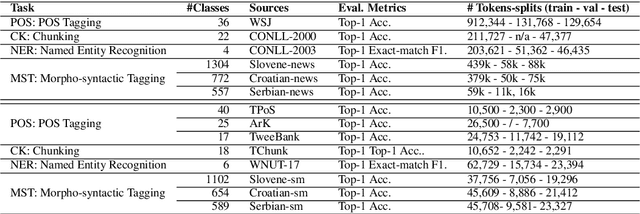
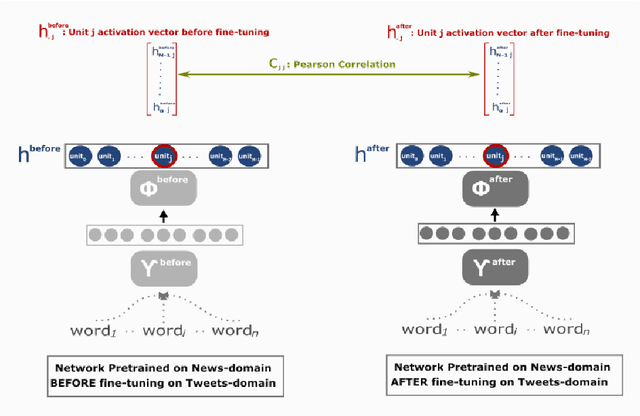

Neural Transfer Learning (TL) is becoming ubiquitous in Natural Language Processing (NLP), thanks to its high performance on many tasks, especially in low-resourced scenarios. Notably, TL is widely used for neural domain adaptation to transfer valuable knowledge from high-resource to low-resource domains. In the standard fine-tuning scheme of TL, a model is initially pre-trained on a source domain and subsequently fine-tuned on a target domain and, therefore, source and target domains are trained using the same architecture. In this paper, we show through interpretation methods that such scheme, despite its efficiency, is suffering from a main limitation. Indeed, although capable of adapting to new domains, pre-trained neurons struggle with learning certain patterns that are specific to the target domain. Moreover, we shed light on the hidden negative transfer occurring despite the high relatedness between source and target domains, which may mitigate the final gain brought by transfer learning. To address these problems, we propose to augment the pre-trained model with normalised, weighted and randomly initialised units that foster a better adaptation while maintaining the valuable source knowledge. We show that our approach exhibits significant improvements to the standard fine-tuning scheme for neural domain adaptation from the news domain to the social media domain on four NLP tasks: part-of-speech tagging, chunking, named entity recognition and morphosyntactic tagging.
Joint Learning of Pre-Trained and Random Units for Domain Adaptation in Part-of-Speech Tagging
Apr 07, 2019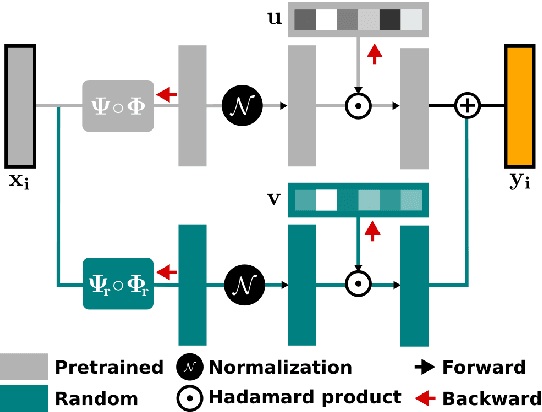
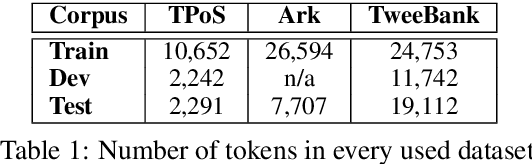
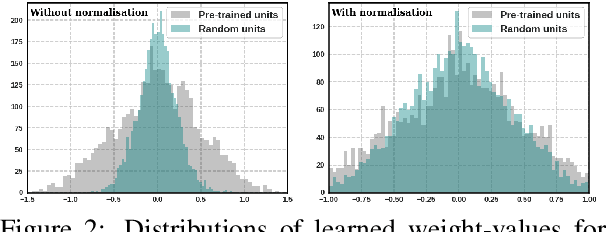
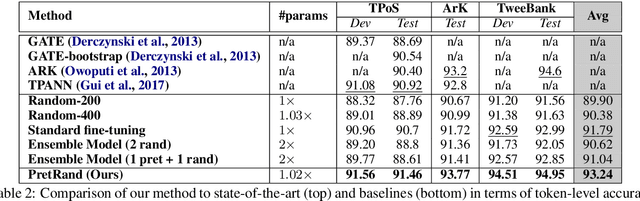
Fine-tuning neural networks is widely used to transfer valuable knowledge from high-resource to low-resource domains. In a standard fine-tuning scheme, source and target problems are trained using the same architecture. Although capable of adapting to new domains, pre-trained units struggle with learning uncommon target-specific patterns. In this paper, we propose to augment the target-network with normalised, weighted and randomly initialised units that beget a better adaptation while maintaining the valuable source knowledge. Our experiments on POS tagging of social media texts (Tweets domain) demonstrate that our method achieves state-of-the-art performances on 3 commonly used datasets.
Sequence to Sequence Learning for Query Expansion
Dec 25, 2018

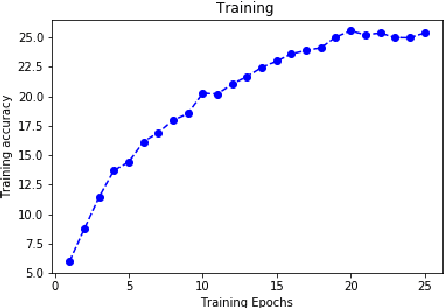

Using sequence to sequence algorithms for query expansion has not been explored yet in Information Retrieval literature nor in Question-Answering's. We tried to fill this gap in the literature with a custom Query Expansion engine trained and tested on open datasets. Starting from open datasets, we built a Query Expansion training set using sentence-embeddings-based Keyword Extraction. We therefore assessed the ability of the Sequence to Sequence neural networks to capture expanding relations in the words embeddings' space.