 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Multi-View Approach to Short-Term Load Forecasting
Feb 09, 2026Time series forecasting is a critical task across domains such as energy, finance, and meteorology, where accurate predictions enable informed decision-making. While transformer-based and large-parameter models have recently achieved state-of-the-art results, their complexity can lead to overfitting and unstable forecasts, especially when older data points become less relevant. In this paper, we propose a lightweight multi-view approach to short-term load forecasting that leverages single-value embeddings and a scaled time-range input to capture temporally relevant features efficiently. We introduce an embedding dropout mechanism to prevent over-reliance on specific features and enhance interpretability. Our method achieves competitive performance with significantly fewer parameters, demonstrating robustness across multiple datasets, including scenarios with noisy or sparse data, and provides insights into the contributions of individual features to the forecast.
Accelerating Quasi-Static Time Series Simulations with Foundation Models
Nov 13, 2024Quasi-static time series (QSTS) simulations have great potential for evaluating the grid's ability to accommodate the large-scale integration of distributed energy resources. However, as grids expand and operate closer to their limits, iterative power flow solvers, central to QSTS simulations, become computationally prohibitive and face increasing convergence issues. Neural power flow solvers provide a promising alternative, speeding up power flow computations by 3 to 4 orders of magnitude, though they are costly to train. In this paper, we envision how recently introduced grid foundation models could improve the economic viability of neural power flow solvers. Conceptually, these models amortize training costs by serving as a foundation for a range of grid operation and planning tasks beyond power flow solving, with only minimal fine-tuning required. We call for collaboration between the AI and power grid communities to develop and open-source these models, enabling all operators, even those with limited resources, to benefit from AI without building solutions from scratch.
A Perspective on Foundation Models for the Electric Power Grid
Jul 12, 2024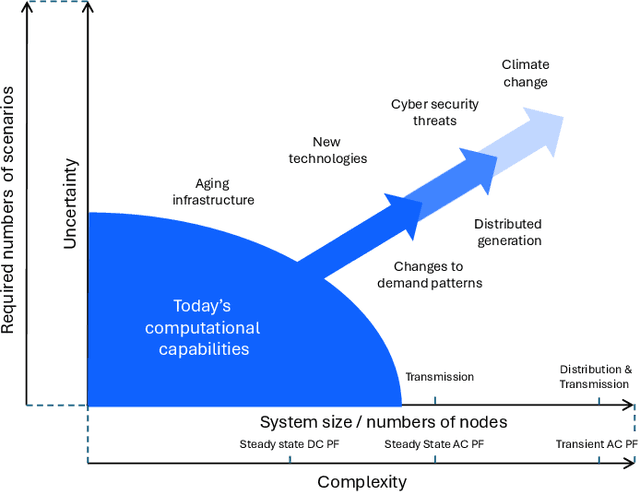
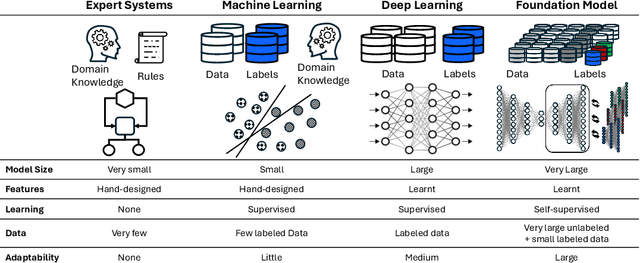
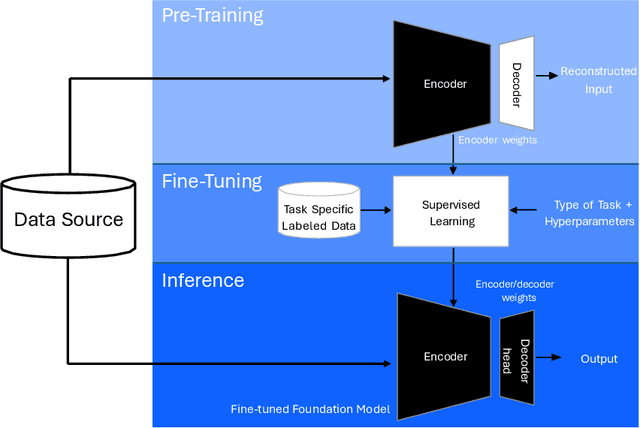
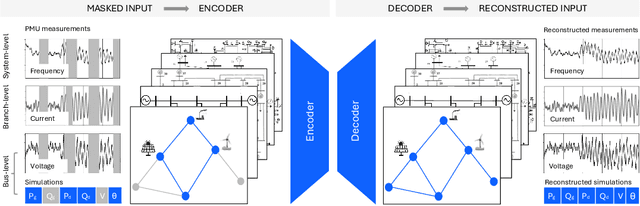
Foundation models (FMs) currently dominate news headlines. They employ advanced deep learning architectures to extract structural information autonomously from vast datasets through self-supervision. The resulting rich representations of complex systems and dynamics can be applied to many downstream applications. Therefore, FMs can find uses in electric power grids, challenged by the energy transition and climate change. In this paper, we call for the development of, and state why we believe in, the potential of FMs for electric grids. We highlight their strengths and weaknesses amidst the challenges of a changing grid. We argue that an FM learning from diverse grid data and topologies could unlock transformative capabilities, pioneering a new approach in leveraging AI to redefine how we manage complexity and uncertainty in the electric grid. Finally, we discuss a power grid FM concept, namely GridFM, based on graph neural networks and show how different downstream tasks benefit.
Towards a Transformer-Based Reverse Dictionary Model for Quality Estimation of Definitions
Nov 08, 2023In the last years, several variants of transformers have emerged. In this paper, we compare different transformer-based models for solving the reverse dictionary task and explore their use in the context of a serious game called The Dictionary Game.
The Latent Structure of Dictionaries
Jan 22, 2016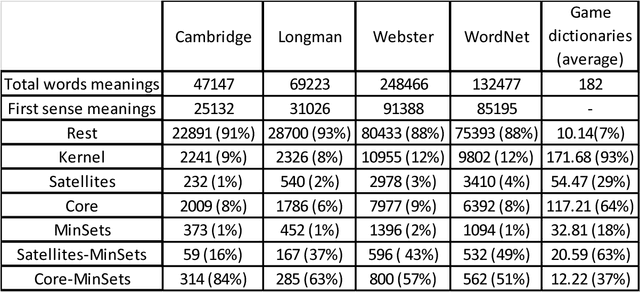
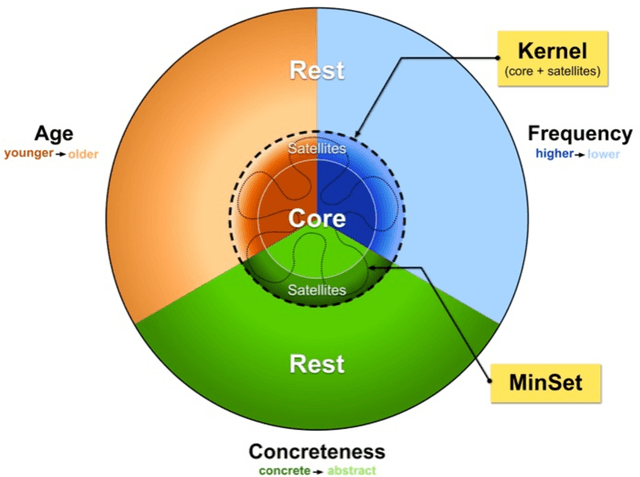
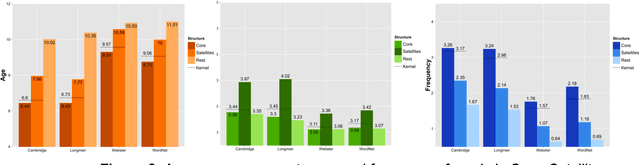
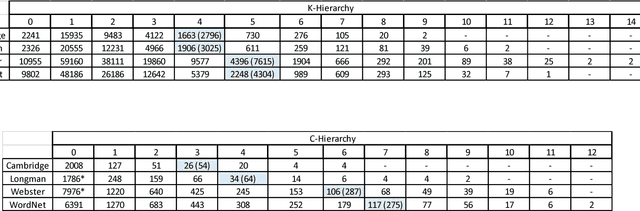
How many words (and which ones) are sufficient to define all other words? When dictionaries are analyzed as directed graphs with links from defining words to defined words, they reveal a latent structure. Recursively removing all words that are reachable by definition but that do not define any further words reduces the dictionary to a Kernel of about 10%. This is still not the smallest number of words that can define all the rest. About 75% of the Kernel turns out to be its Core, a Strongly Connected Subset of words with a definitional path to and from any pair of its words and no word's definition depending on a word outside the set. But the Core cannot define all the rest of the dictionary. The 25% of the Kernel surrounding the Core consists of small strongly connected subsets of words: the Satellites. The size of the smallest set of words that can define all the rest (the graph's Minimum Feedback Vertex Set or MinSet) is about 1% of the dictionary, 15% of the Kernel, and half-Core, half-Satellite. But every dictionary has a huge number of MinSets. The Core words are learned earlier, more frequent, and less concrete than the Satellites, which in turn are learned earlier and more frequent but more concrete than the rest of the Dictionary. In principle, only one MinSet's words would need to be grounded through the sensorimotor capacity to recognize and categorize their referents. In a dual-code sensorimotor-symbolic model of the mental lexicon, the symbolic code could do all the rest via re-combinatory definition.