 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTolerance Principle and Small Language Model Learning
Jan 17, 2026Modern language models like GPT-3, BERT, and LLaMA require massive training data, yet with sufficient training they reliably learn to distinguish grammatical from ungrammatical sentences. Children aged as young as 14 months already have the capacity to learn abstract grammar rules from very few exemplars, even in the presence of non-rule-following exceptions. Yang's (2016) Tolerance Principle defines a precise threshold for how many exceptions a rule can tolerate and still be learnable. The present study explored the minimal amount and quality of training data necessary for rules to be generalized by a transformer-based language model to test the predictions of the Tolerance Principle. We trained BabyBERTa (Huebner et al. 2021), a transformer model optimized for small datasets, on artificial grammars. The training sets varied in size, number of unique sentence types, and proportion of rule-following versus exception exemplars. We found that, unlike human infants, BabyBERTa's learning dynamics do not align with the Tolerance Principle.
Language Writ Large: LLMs, ChatGPT, Grounding, Meaning and Understanding
Feb 03, 2024Apart from what (little) OpenAI may be concealing from us, we all know (roughly) how ChatGPT works (its huge text database, its statistics, its vector representations, and their huge number of parameters, its next-word training, and so on). But none of us can say (hand on heart) that we are not surprised by what ChatGPT has proved to be able to do with these resources. This has even driven some of us to conclude that ChatGPT actually understands. It is not true that it understands. But it is also not true that we understand how it can do what it can do. I will suggest some hunches about benign biases: convergent constraints that emerge at LLM scale that may be helping ChatGPT do so much better than we would have expected. These biases are inherent in the nature of language itself, at LLM scale, and they are closely linked to what it is that ChatGPT lacks, which is direct sensorimotor grounding to connect its words to their referents and its propositions to their meanings. These convergent biases are related to (1) the parasitism of indirect verbal grounding on direct sensorimotor grounding, (2) the circularity of verbal definition, (3) the mirroring of language production and comprehension, (4) iconicity in propositions at LLM scale, (5) computational counterparts of human categorical perception in category learning by neural nets, and perhaps also (6) a conjecture by Chomsky about the laws of thought. The exposition will be in the form of a dialogue with ChatGPT-4.
Learning-induced categorical perception in a neural network model
May 11, 2018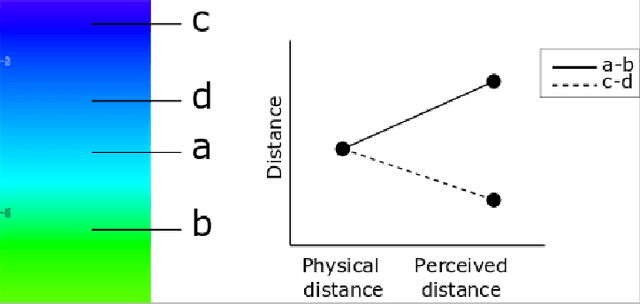
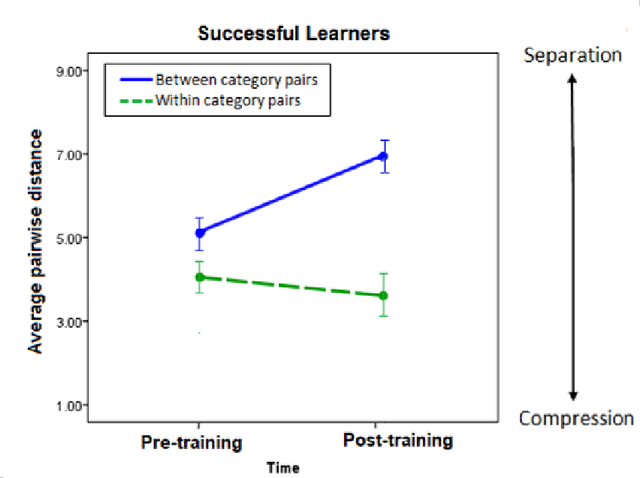
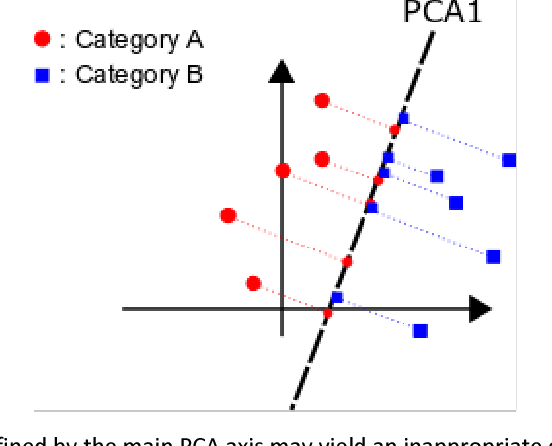
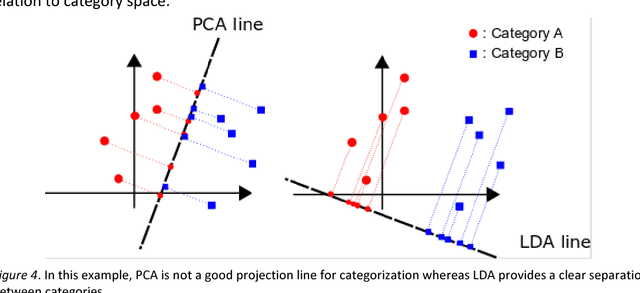
In human cognition, the expansion of perceived between-category distances and compression of within-category distances is known as categorical perception (CP). There are several hypotheses about the causes of CP (e.g., language, learning, evolution) but no functional model. Whether CP is essential to categorisation or simply a by-product of it is not yet clear, but evidence is accumulating that CP can be induced by category learning. We provide a model for learning-induced CP as expansion and compression of distances in hidden-unit space in neural nets. Basic conditions from which the current model predicts CP are described, and clues as to how these conditions might generalize to more complex kinds of categorization begin to emerge.
The Latent Structure of Dictionaries
Jan 22, 2016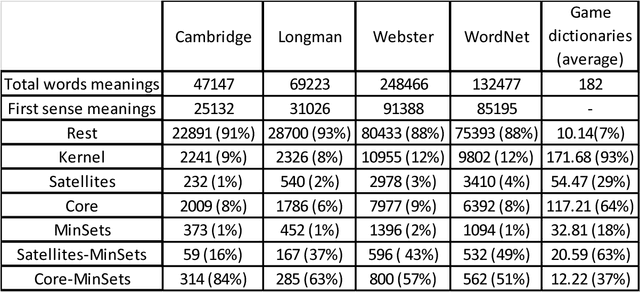
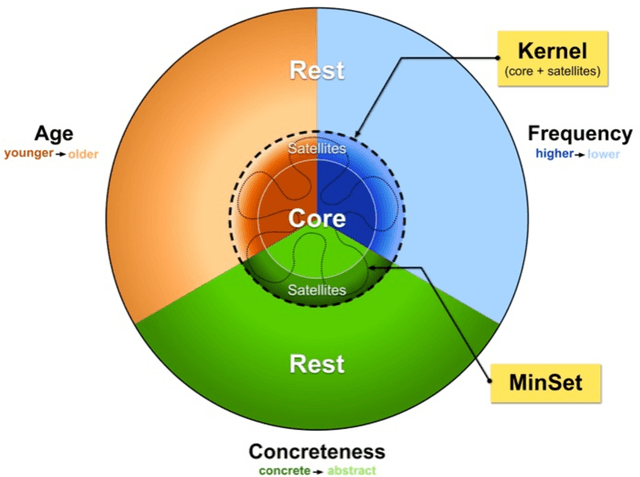
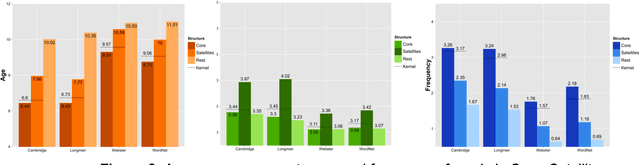
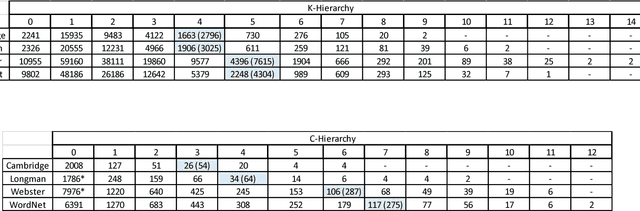
How many words (and which ones) are sufficient to define all other words? When dictionaries are analyzed as directed graphs with links from defining words to defined words, they reveal a latent structure. Recursively removing all words that are reachable by definition but that do not define any further words reduces the dictionary to a Kernel of about 10%. This is still not the smallest number of words that can define all the rest. About 75% of the Kernel turns out to be its Core, a Strongly Connected Subset of words with a definitional path to and from any pair of its words and no word's definition depending on a word outside the set. But the Core cannot define all the rest of the dictionary. The 25% of the Kernel surrounding the Core consists of small strongly connected subsets of words: the Satellites. The size of the smallest set of words that can define all the rest (the graph's Minimum Feedback Vertex Set or MinSet) is about 1% of the dictionary, 15% of the Kernel, and half-Core, half-Satellite. But every dictionary has a huge number of MinSets. The Core words are learned earlier, more frequent, and less concrete than the Satellites, which in turn are learned earlier and more frequent but more concrete than the rest of the Dictionary. In principle, only one MinSet's words would need to be grounded through the sensorimotor capacity to recognize and categorize their referents. In a dual-code sensorimotor-symbolic model of the mental lexicon, the symbolic code could do all the rest via re-combinatory definition.
Hidden Structure and Function in the Lexicon
Sep 16, 2013
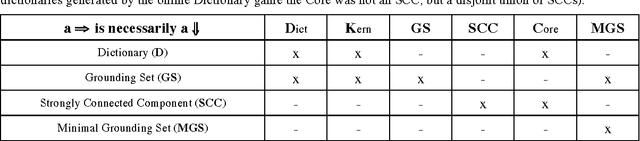

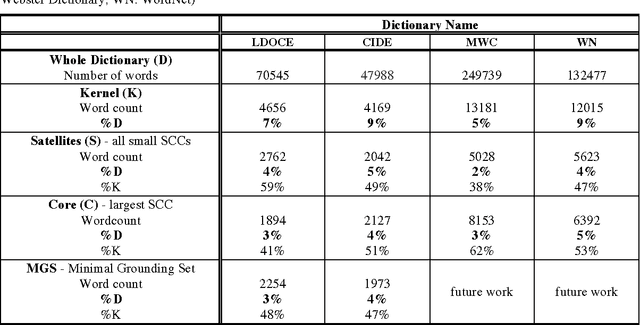
How many words are needed to define all the words in a dictionary? Graph-theoretic analysis reveals that about 10% of a dictionary is a unique Kernel of words that define one another and all the rest, but this is not the smallest such subset. The Kernel consists of one huge strongly connected component (SCC), about half its size, the Core, surrounded by many small SCCs, the Satellites. Core words can define one another but not the rest of the dictionary. The Kernel also contains many overlapping Minimal Grounding Sets (MGSs), each about the same size as the Core, each part-Core, part-Satellite. MGS words can define all the rest of the dictionary. They are learned earlier, more concrete and more frequent than the rest of the dictionary. Satellite words, not correlated with age or frequency, are less concrete (more abstract) words that are also needed for full lexical power.
* 11 pages, 5 figures, 2 tables
Alan Turing and the "Hard" and "Easy" Problem of Cognition: Doing and Feeling
Jun 16, 2012The "easy" problem of cognitive science is explaining how and why we can do what we can do. The "hard" problem is explaining how and why we feel. Turing's methodology for cognitive science (the Turing Test) is based on doing: Design a model that can do anything a human can do, indistinguishably from a human, to a human, and you have explained cognition. Searle has shown that the successful model cannot be solely computational. Sensory-motor robotic capacities are necessary to ground some, at least, of the model's words, in what the robot can do with the things in the world that the words are about. But even grounding is not enough to guarantee that -- nor to explain how and why -- the model feels (if it does). That problem is much harder to solve (and perhaps insoluble).
The Causal Topography of Cognition
Jun 04, 2012The causal structure of cognition can be simulated but not implemented computationally, just as the causal structure of a comet can be simulated but not implemented computationally. The only thing that allows us even to imagine otherwise is that cognition, unlike a comet, is invisible (to all but the cognizer).
Hierarchies in Dictionary Definition Space
Nov 30, 2009



A dictionary defines words in terms of other words. Definitions can tell you the meanings of words you don't know, but only if you know the meanings of the defining words. How many words do you need to know (and which ones) in order to be able to learn all the rest from definitions? We reduced dictionaries to their "grounding kernels" (GKs), about 10% of the dictionary, from which all the other words could be defined. The GK words turned out to have psycholinguistic correlates: they were learned at an earlier age and more concrete than the rest of the dictionary. But one can compress still more: the GK turns out to have internal structure, with a strongly connected "kernel core" (KC) and a surrounding layer, from which a hierarchy of definitional distances can be derived, all the way out to the periphery of the full dictionary. These definitional distances, too, are correlated with psycholinguistic variables (age of acquisition, concreteness, imageability, oral and written frequency) and hence perhaps with the "mental lexicon" in each of our heads.
On Fodor on Darwin on Evolution
Apr 13, 2009Jerry Fodor argues that Darwin was wrong about "natural selection" because (1) it is only a tautology rather than a scientific law that can support counterfactuals ("If X had happened, Y would have happened") and because (2) only minds can select. Hence Darwin's analogy with "artificial selection" by animal breeders was misleading and evolutionary explanation is nothing but post-hoc historical narrative. I argue that Darwin was right on all counts.
Offloading Cognition onto Cognitive Technology
Sep 01, 2008"Cognizing" (e.g., thinking, understanding, and knowing) is a mental state. Systems without mental states, such as cognitive technology, can sometimes contribute to human cognition, but that does not make them cognizers. Cognizers can offload some of their cognitive functions onto cognitive technology, thereby extending their performance capacity beyond the limits of their own brain power. Language itself is a form of cognitive technology that allows cognizers to offload some of their cognitive functions onto the brains of other cognizers. Language also extends cognizers' individual and joint performance powers, distributing the load through interactive and collaborative cognition. Reading, writing, print, telecommunications and computing further extend cognizers' capacities. And now the web, with its network of cognizers, digital databases and software agents, all accessible anytime, anywhere, has become our 'Cognitive Commons,' in which distributed cognizers and cognitive technology can interoperate globally with a speed, scope and degree of interactivity inconceivable through local individual cognition alone. And as with language, the cognitive tool par excellence, such technological changes are not merely instrumental and quantitative: they can have profound effects on how we think and encode information, on how we communicate with one another, on our mental states, and on our very nature.