 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Reproducibility in Machine Learning Research (A Report from the NeurIPS 2019 Reproducibility Program)
Apr 02, 2020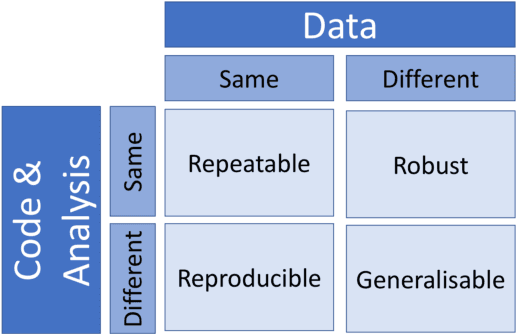
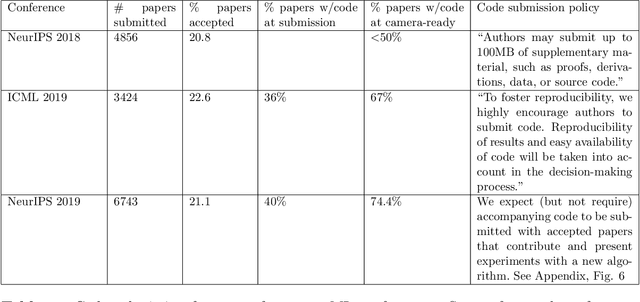
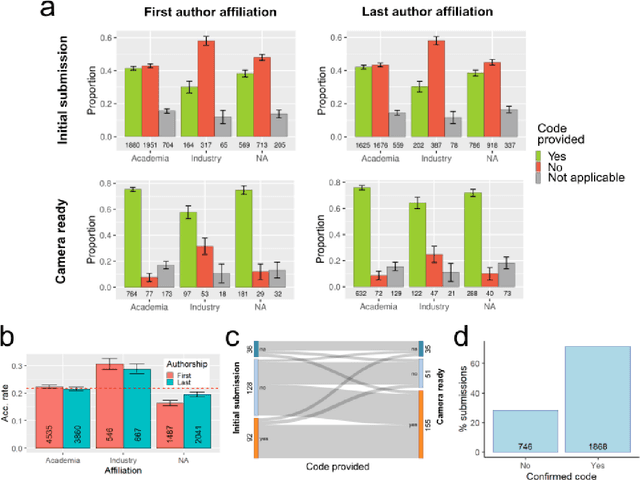
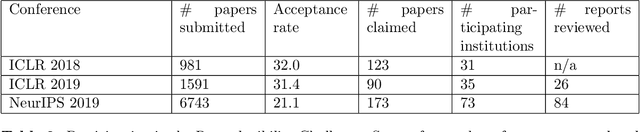
One of the challenges in machine learning research is to ensure that presented and published results are sound and reliable. Reproducibility, that is obtaining similar results as presented in a paper or talk, using the same code and data (when available), is a necessary step to verify the reliability of research findings. Reproducibility is also an important step to promote open and accessible research, thereby allowing the scientific community to quickly integrate new findings and convert ideas to practice. Reproducibility also promotes the use of robust experimental workflows, which potentially reduce unintentional errors. In 2019, the Neural Information Processing Systems (NeurIPS) conference, the premier international conference for research in machine learning, introduced a reproducibility program, designed to improve the standards across the community for how we conduct, communicate, and evaluate machine learning research. The program contained three components: a code submission policy, a community-wide reproducibility challenge, and the inclusion of the Machine Learning Reproducibility checklist as part of the paper submission process. In this paper, we describe each of these components, how it was deployed, as well as what we were able to learn from this initiative.
Content and linguistic biases in the peer review process of artificial intelligence conferences
Oct 21, 2019
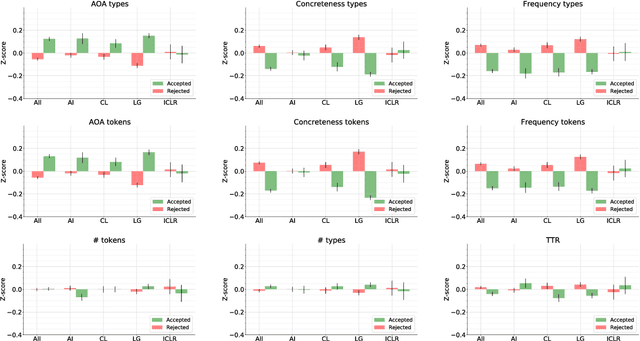
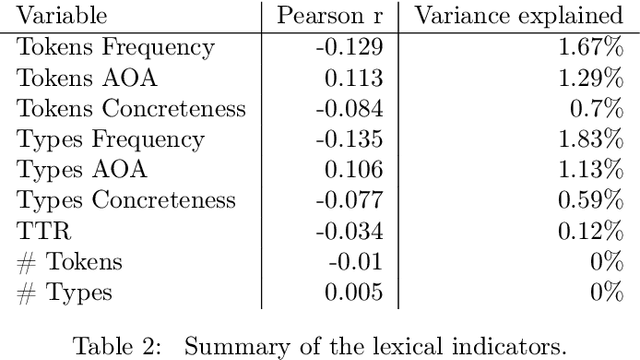
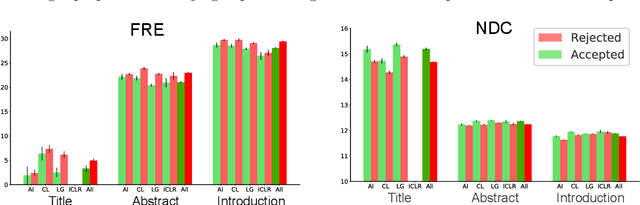
We analysed a recently released dataset of scientific manuscripts that were either rejected or accepted from various conferences in artificial intelligence. We used a combination of semantic, lexical and psycholinguistic analyses of the full text of the manuscripts to compare them based on the outcome of the peer review process. We found that accepted manuscripts were written with words that are less frequent, that are acquired at an older age, and that are more abstract than rejected manuscripts. We also found that accepted manuscripts scored lower on two indicators of readability than rejected manuscripts, and that they also used more artificial intelligence jargon. An analysis of the references included in the manuscripts revealed that the subset of accepted submissions were more likely to cite the same publications. This finding was echoed by pairwise comparisons of the word content of the manuscripts (i.e. an indicator or semantic similarity), which was higher in the accepted manuscripts. Finally, we predicted the peer review outcome of manuscripts with their word content, with words related to machine learning and neural networks positively related with acceptance, whereas words related to logic, symbolic processing and knowledge-based systems negatively related with acceptance.
The Latent Structure of Dictionaries
Jan 22, 2016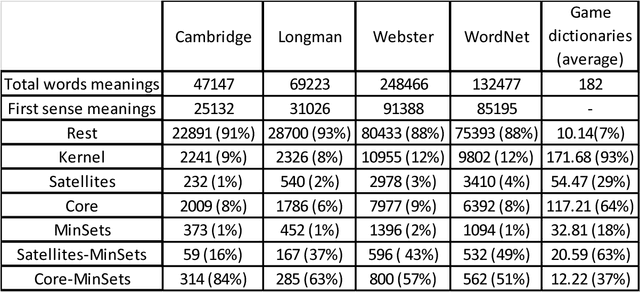
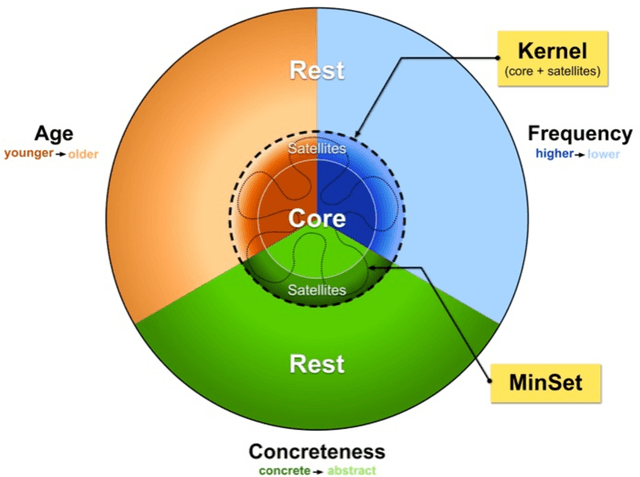
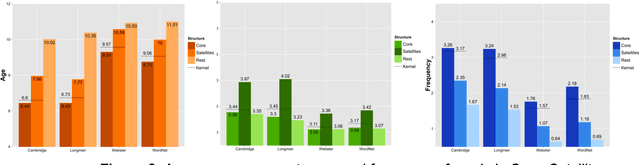
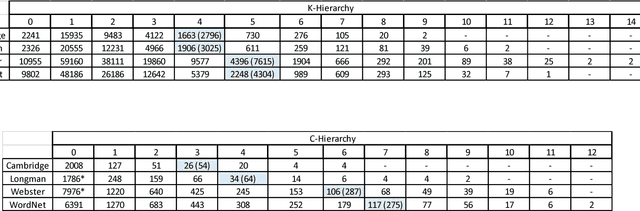
How many words (and which ones) are sufficient to define all other words? When dictionaries are analyzed as directed graphs with links from defining words to defined words, they reveal a latent structure. Recursively removing all words that are reachable by definition but that do not define any further words reduces the dictionary to a Kernel of about 10%. This is still not the smallest number of words that can define all the rest. About 75% of the Kernel turns out to be its Core, a Strongly Connected Subset of words with a definitional path to and from any pair of its words and no word's definition depending on a word outside the set. But the Core cannot define all the rest of the dictionary. The 25% of the Kernel surrounding the Core consists of small strongly connected subsets of words: the Satellites. The size of the smallest set of words that can define all the rest (the graph's Minimum Feedback Vertex Set or MinSet) is about 1% of the dictionary, 15% of the Kernel, and half-Core, half-Satellite. But every dictionary has a huge number of MinSets. The Core words are learned earlier, more frequent, and less concrete than the Satellites, which in turn are learned earlier and more frequent but more concrete than the rest of the Dictionary. In principle, only one MinSet's words would need to be grounded through the sensorimotor capacity to recognize and categorize their referents. In a dual-code sensorimotor-symbolic model of the mental lexicon, the symbolic code could do all the rest via re-combinatory definition.