 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHas the Machine Learning Review Process Become More Arbitrary as the Field Has Grown? The NeurIPS 2021 Consistency Experiment
Jun 05, 2023
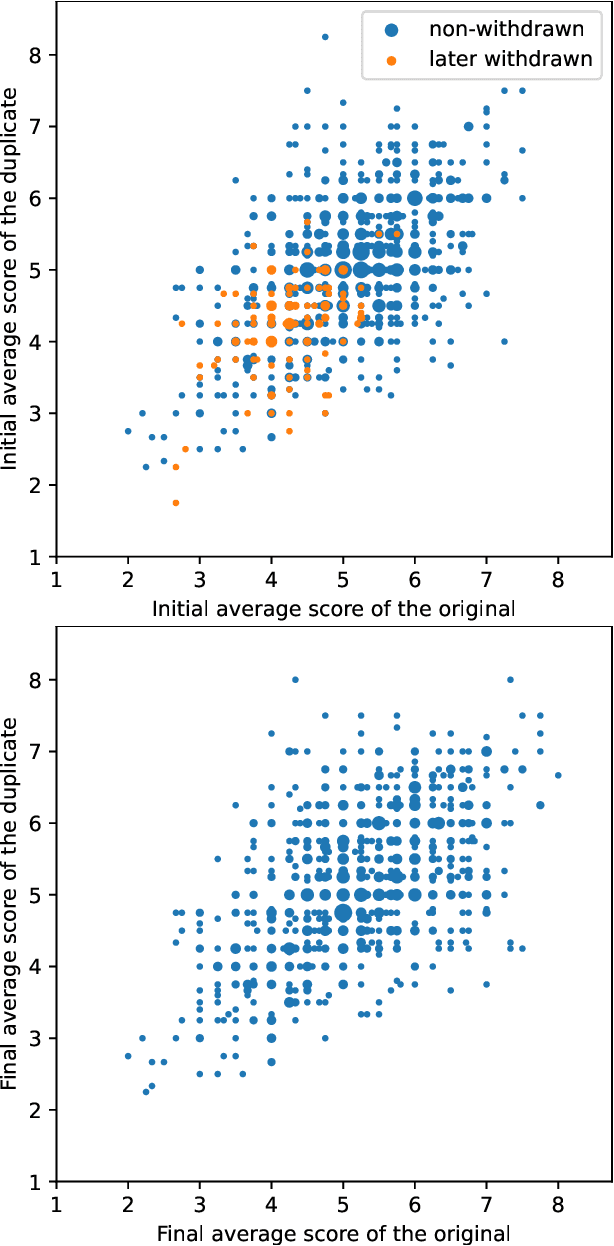
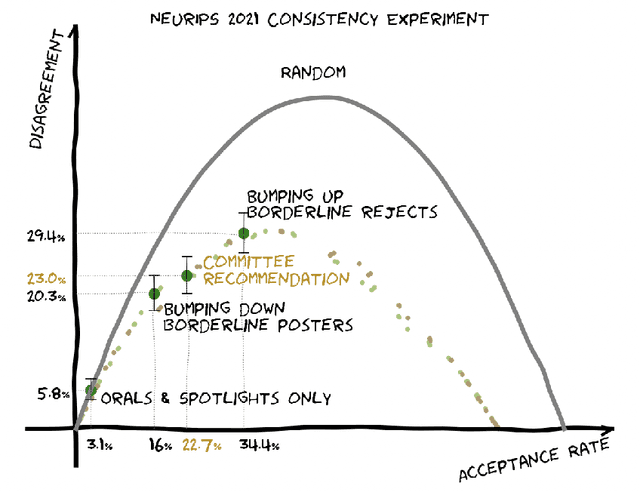
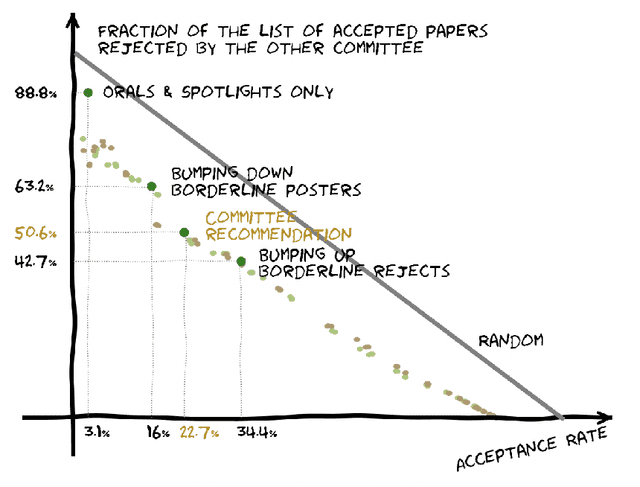
We present the NeurIPS 2021 consistency experiment, a larger-scale variant of the 2014 NeurIPS experiment in which 10% of conference submissions were reviewed by two independent committees to quantify the randomness in the review process. We observe that the two committees disagree on their accept/reject recommendations for 23% of the papers and that, consistent with the results from 2014, approximately half of the list of accepted papers would change if the review process were randomly rerun. Our analysis suggests that making the conference more selective would increase the arbitrariness of the process. Taken together with previous research, our results highlight the inherent difficulty of objectively measuring the quality of research, and suggest that authors should not be excessively discouraged by rejected work.
How do Authors' Perceptions of their Papers Compare with Co-authors' Perceptions and Peer-review Decisions?
Nov 22, 2022



How do author perceptions match up to the outcomes of the peer-review process and perceptions of others? In a top-tier computer science conference (NeurIPS 2021) with more than 23,000 submitting authors and 9,000 submitted papers, we survey the authors on three questions: (i) their predicted probability of acceptance for each of their papers, (ii) their perceived ranking of their own papers based on scientific contribution, and (iii) the change in their perception about their own papers after seeing the reviews. The salient results are: (1) Authors have roughly a three-fold overestimate of the acceptance probability of their papers: The median prediction is 70% for an approximately 25% acceptance rate. (2) Female authors exhibit a marginally higher (statistically significant) miscalibration than male authors; predictions of authors invited to serve as meta-reviewers or reviewers are similarly calibrated, but better than authors who were not invited to review. (3) Authors' relative ranking of scientific contribution of two submissions they made generally agree (93%) with their predicted acceptance probabilities, but there is a notable 7% responses where authors think their better paper will face a worse outcome. (4) The author-provided rankings disagreed with the peer-review decisions about a third of the time; when co-authors ranked their jointly authored papers, co-authors disagreed at a similar rate -- about a third of the time. (5) At least 30% of respondents of both accepted and rejected papers said that their perception of their own paper improved after the review process. The stakeholders in peer review should take these findings into account in setting their expectations from peer review.
Improving Reproducibility in Machine Learning Research (A Report from the NeurIPS 2019 Reproducibility Program)
Apr 02, 2020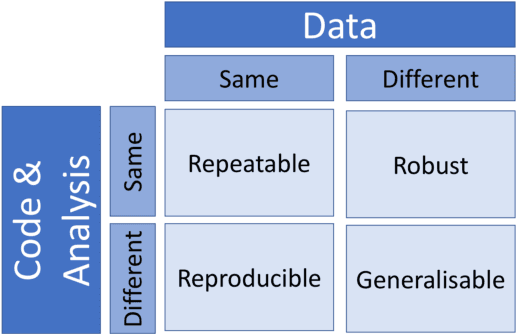
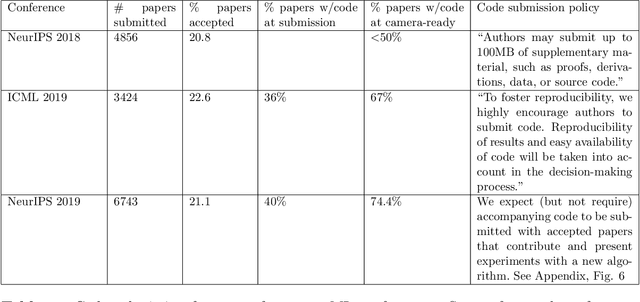
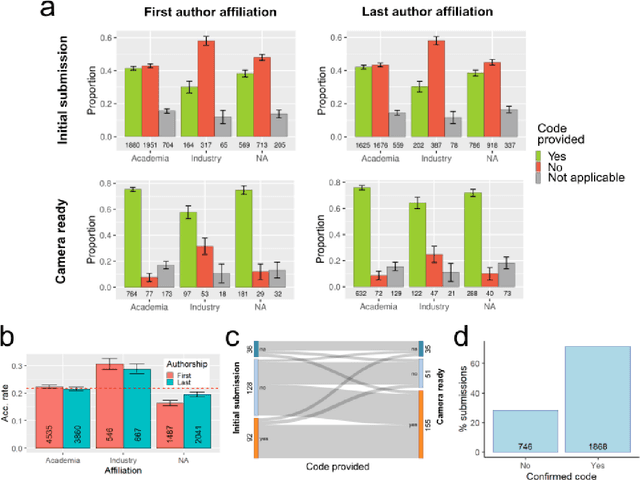
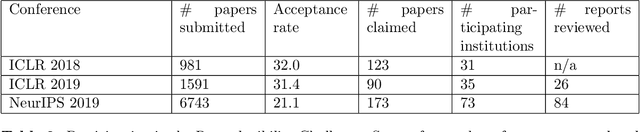
One of the challenges in machine learning research is to ensure that presented and published results are sound and reliable. Reproducibility, that is obtaining similar results as presented in a paper or talk, using the same code and data (when available), is a necessary step to verify the reliability of research findings. Reproducibility is also an important step to promote open and accessible research, thereby allowing the scientific community to quickly integrate new findings and convert ideas to practice. Reproducibility also promotes the use of robust experimental workflows, which potentially reduce unintentional errors. In 2019, the Neural Information Processing Systems (NeurIPS) conference, the premier international conference for research in machine learning, introduced a reproducibility program, designed to improve the standards across the community for how we conduct, communicate, and evaluate machine learning research. The program contained three components: a code submission policy, a community-wide reproducibility challenge, and the inclusion of the Machine Learning Reproducibility checklist as part of the paper submission process. In this paper, we describe each of these components, how it was deployed, as well as what we were able to learn from this initiative.
Bandit Multiclass Linear Classification: Efficient Algorithms for the Separable Case
Feb 06, 2019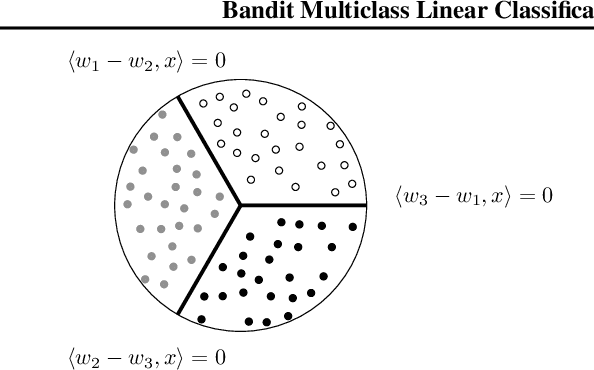
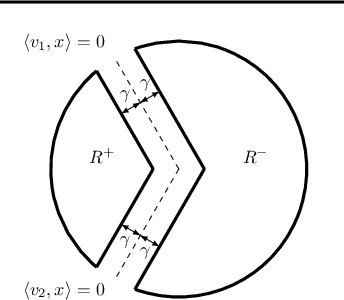

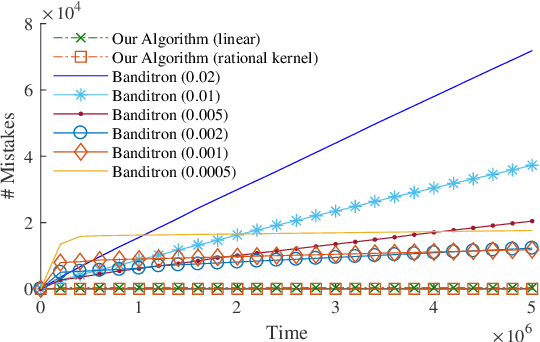
We study the problem of efficient online multiclass linear classification with bandit feedback, where all examples belong to one of $K$ classes and lie in the $d$-dimensional Euclidean space. Previous works have left open the challenge of designing efficient algorithms with finite mistake bounds when the data is linearly separable by a margin $\gamma$. In this work, we take a first step towards this problem. We consider two notions of linear separability, \emph{strong} and \emph{weak}. 1. Under the strong linear separability condition, we design an efficient algorithm that achieves a near-optimal mistake bound of $O\left( K/\gamma^2 \right)$. 2. Under the more challenging weak linear separability condition, we design an efficient algorithm with a mistake bound of $\min (2^{\widetilde{O}(K \log^2 (1/\gamma))}, 2^{\widetilde{O}(\sqrt{1/\gamma} \log K)})$. Our algorithm is based on kernel Perceptron, which is inspired by the work of \citet{Klivans-Servedio-2008} on improperly learning intersection of halfspaces.
Contextual Memory Trees
Jul 17, 2018



We design and study a Contextual Memory Tree (CMT), a learning memory controller that inserts new memories into an experience store of unbounded size. It is designed to efficiently query for memories from that store, supporting logarithmic time insertion and retrieval operations. Hence CMT can be integrated into existing statistical learning algorithms as an augmented memory unit without substantially increasing training and inference computation. We demonstrate the efficacy of CMT by augmenting existing multi-class and multi-label classification algorithms with CMT and observe statistical improvement. We also test CMT learning on several image-captioning tasks to demonstrate that it performs computationally better than a simple nearest neighbors memory system while benefitting from reward learning.
A Reductions Approach to Fair Classification
Jul 16, 2018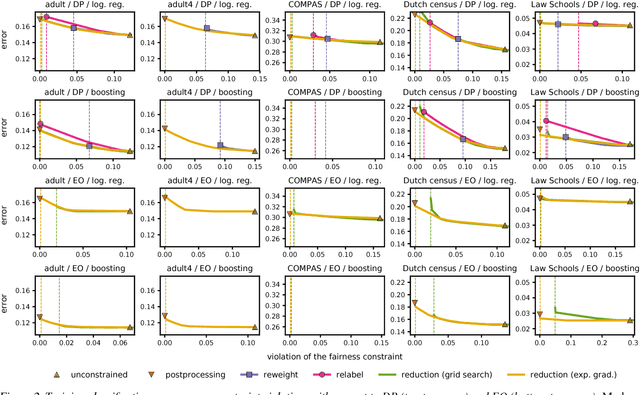
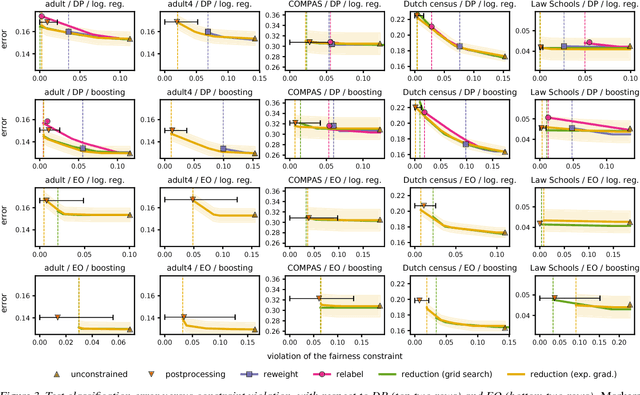
We present a systematic approach for achieving fairness in a binary classification setting. While we focus on two well-known quantitative definitions of fairness, our approach encompasses many other previously studied definitions as special cases. The key idea is to reduce fair classification to a sequence of cost-sensitive classification problems, whose solutions yield a randomized classifier with the lowest (empirical) error subject to the desired constraints. We introduce two reductions that work for any representation of the cost-sensitive classifier and compare favorably to prior baselines on a variety of data sets, while overcoming several of their disadvantages.
Efficient Online Bandit Multiclass Learning with $\tilde{O}(\sqrt{T})$ Regret
Jan 17, 2018
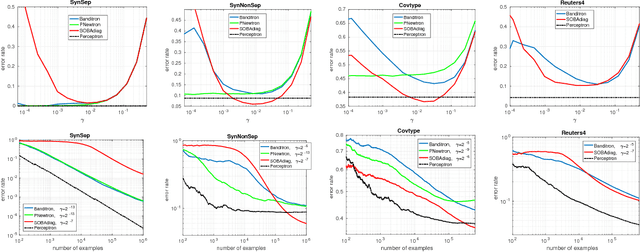
We present an efficient second-order algorithm with $\tilde{O}(\frac{1}{\eta}\sqrt{T})$ regret for the bandit online multiclass problem. The regret bound holds simultaneously with respect to a family of loss functions parameterized by $\eta$, for a range of $\eta$ restricted by the norm of the competitor. The family of loss functions ranges from hinge loss ($\eta=0$) to squared hinge loss ($\eta=1$). This provides a solution to the open problem of (J. Abernethy and A. Rakhlin. An efficient bandit algorithm for $\sqrt{T}$-regret in online multiclass prediction? In COLT, 2009). We test our algorithm experimentally, showing that it also performs favorably against earlier algorithms.
Search Improves Label for Active Learning
Oct 24, 2016We investigate active learning with access to two distinct oracles: Label (which is standard) and Search (which is not). The Search oracle models the situation where a human searches a database to seed or counterexample an existing solution. Search is stronger than Label while being natural to implement in many situations. We show that an algorithm using both oracles can provide exponentially large problem-dependent improvements over Label alone.
The Offset Tree for Learning with Partial Labels
Apr 03, 2016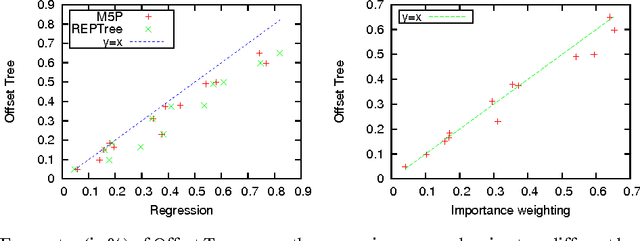
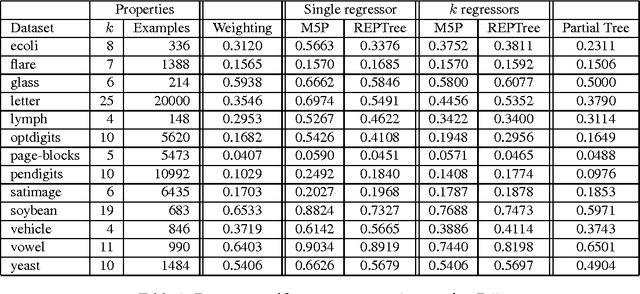
We present an algorithm, called the Offset Tree, for learning to make decisions in situations where the payoff of only one choice is observed, rather than all choices. The algorithm reduces this setting to binary classification, allowing one to reuse of any existing, fully supervised binary classification algorithm in this partial information setting. We show that the Offset Tree is an optimal reduction to binary classification. In particular, it has regret at most $(k-1)$ times the regret of the binary classifier it uses (where $k$ is the number of choices), and no reduction to binary classification can do better. This reduction is also computationally optimal, both at training and test time, requiring just $O(\log_2 k)$ work to train on an example or make a prediction. Experiments with the Offset Tree show that it generally performs better than several alternative approaches.
Online Gradient Boosting
Oct 30, 2015We extend the theory of boosting for regression problems to the online learning setting. Generalizing from the batch setting for boosting, the notion of a weak learning algorithm is modeled as an online learning algorithm with linear loss functions that competes with a base class of regression functions, while a strong learning algorithm is an online learning algorithm with convex loss functions that competes with a larger class of regression functions. Our main result is an online gradient boosting algorithm which converts a weak online learning algorithm into a strong one where the larger class of functions is the linear span of the base class. We also give a simpler boosting algorithm that converts a weak online learning algorithm into a strong one where the larger class of functions is the convex hull of the base class, and prove its optimality.