 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming the Monster Every Context: Complexity Measure and Unified Framework for Offline-Oracle Efficient Contextual Bandits
Feb 10, 2026We propose an algorithmic framework, Offline Estimation to Decisions (OE2D), that reduces contextual bandit learning with general reward function approximation to offline regression. The framework allows near-optimal regret for contextual bandits with large action spaces with $O(log(T))$ calls to an offline regression oracle over $T$ rounds, and makes $O(loglog(T))$ calls when $T$ is known. The design of OE2D algorithm generalizes Falcon~\citep{simchi2022bypassing} and its linear reward version~\citep[][Section 4]{xu2020upper} in that it chooses an action distribution that we term ``exploitative F-design'' that simultaneously guarantees low regret and good coverage that trades off exploration and exploitation. Central to our regret analysis is a new complexity measure, the Decision-Offline Estimation Coefficient (DOEC), which we show is bounded in bounded Eluder dimension per-context and smoothed regret settings. We also establish a relationship between DOEC and Decision Estimation Coefficient (DEC)~\citep{foster2021statistical}, bridging the design principles of offline- and online-oracle efficient contextual bandit algorithms for the first time.
Improving the Data-efficiency of Reinforcement Learning by Warm-starting with LLM
May 16, 2025We investigate the usage of Large Language Model (LLM) in collecting high-quality data to warm-start Reinforcement Learning (RL) algorithms for learning in some classical Markov Decision Process (MDP) environments. In this work, we focus on using LLM to generate an off-policy dataset that sufficiently covers state-actions visited by optimal policies, then later using an RL algorithm to explore the environment and improve the policy suggested by the LLM. Our algorithm, LORO, can both converge to an optimal policy and have a high sample efficiency thanks to the LLM's good starting policy. On multiple OpenAI Gym environments, such as CartPole and Pendulum, we empirically demonstrate that LORO outperforms baseline algorithms such as pure LLM-based policies, pure RL, and a naive combination of the two, achieving up to $4 \times$ the cumulative rewards of the pure RL baseline.
Achieving adaptivity and optimality for multi-armed bandits using Exponential-Kullback Leiblier Maillard Sampling
Feb 20, 2025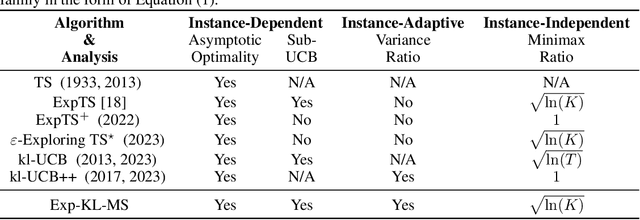

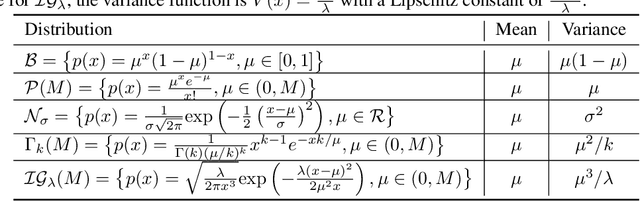

We study the problem of Multi-Armed Bandits (MAB) with reward distributions belonging to a One-Parameter Exponential Distribution (OPED) family. In the literature, several criteria have been proposed to evaluate the performance of such algorithms, including Asymptotic Optimality (A.O.), Minimax Optimality (M.O.), Sub-UCB, and variance-adaptive worst-case regret bound. Thompson Sampling (TS)-based and Upper Confidence Bound (UCB)-based algorithms have been employed to achieve some of these criteria. However, none of these algorithms simultaneously satisfy all the aforementioned criteria. In this paper, we design an algorithm, Exponential Kullback-Leibler Maillard Sampling (abbrev. \expklms), that can achieve multiple optimality criteria simultaneously, including A.O., M.O. with a logarithmic factor, Sub-UCB, and variance-adaptive worst-case regret bound.
A Note on Sample Complexity of Interactive Imitation Learning with Log Loss
Dec 09, 2024Imitation learning (IL) is a general paradigm for learning from experts in sequential decision-making problems. Recent advancements in IL have shown that offline imitation learning, specifically Behavior Cloning (BC) with log loss, is minimax optimal. Meanwhile, its interactive counterpart, DAgger, is shown to suffer from suboptimal sample complexity. In this note, we focus on realizable deterministic expert and revisit interactive imitation learning, particularly DAgger with log loss. We demonstrate: 1. A one-sample-per-round DAgger variant that outperforms BC in state-wise annotation. 2. Without recoverability assumption, DAgger with first-step mixture policies matches the performance of BC. Along the analysis, we introduce a new notion of decoupled Hellinger distance that separates state and action sequences, which can be of independent interest.
Efficient Low-Rank Matrix Estimation, Experimental Design, and Arm-Set-Dependent Low-Rank Bandits
Feb 17, 2024


We study low-rank matrix trace regression and the related problem of low-rank matrix bandits. Assuming access to the distribution of the covariates, we propose a novel low-rank matrix estimation method called LowPopArt and provide its recovery guarantee that depends on a novel quantity denoted by B(Q) that characterizes the hardness of the problem, where Q is the covariance matrix of the measurement distribution. We show that our method can provide tighter recovery guarantees than classical nuclear norm penalized least squares (Koltchinskii et al., 2011) in several problems. To perform efficient estimation with a limited number of measurements from an arbitrarily given measurement set A, we also propose a novel experimental design criterion that minimizes B(Q) with computational efficiency. We leverage our novel estimator and design of experiments to derive two low-rank linear bandit algorithms for general arm sets that enjoy improved regret upper bounds. This improves over previous works on low-rank bandits, which make somewhat restrictive assumptions that the arm set is the unit ball or that an efficient exploration distribution is given. To our knowledge, our experimental design criterion is the first one tailored to low-rank matrix estimation beyond the naive reduction to linear regression, which can be of independent interest.
Ensemble-based Interactive Imitation Learning
Dec 28, 2023We study interactive imitation learning, where a learner interactively queries a demonstrating expert for action annotations, aiming to learn a policy that has performance competitive with the expert, using as few annotations as possible. We give an algorithmic framework named Ensemble-based Interactive Imitation Learning (EIIL) that achieves this goal. Theoretically, we prove that an oracle-efficient version of EIIL achieves sharp regret guarantee, given access to samples from some ``explorative'' distribution over states. Empirically, EIIL notably surpasses online and offline imitation learning benchmarks in continuous control tasks. Our work opens up systematic investigations on the benefit of using model ensembles for interactive imitation learning.
Efficient Active Learning Halfspaces with Tsybakov Noise: A Non-convex Optimization Approach
Oct 23, 2023
We study the problem of computationally and label efficient PAC active learning $d$-dimensional halfspaces with Tsybakov Noise~\citep{tsybakov2004optimal} under structured unlabeled data distributions. Inspired by~\cite{diakonikolas2020learning}, we prove that any approximate first-order stationary point of a smooth nonconvex loss function yields a halfspace with a low excess error guarantee. In light of the above structural result, we design a nonconvex optimization-based algorithm with a label complexity of $\tilde{O}(d (\frac{1}{\epsilon})^{\frac{8-6\alpha}{3\alpha-1}})$\footnote{In the main body of this work, we use $\tilde{O}(\cdot), \tilde{\Theta}(\cdot)$ to hide factors of the form $\polylog(d, \frac{1}{\epsilon}, \frac{1}{\delta})$}, under the assumption that the Tsybakov noise parameter $\alpha \in (\frac13, 1]$, which narrows down the gap between the label complexities of the previously known efficient passive or active algorithms~\citep{diakonikolas2020polynomial,zhang2021improved} and the information-theoretic lower bound in this setting.
Kullback-Leibler Maillard Sampling for Multi-armed Bandits with Bounded Rewards
Apr 28, 2023We study $K$-armed bandit problems where the reward distributions of the arms are all supported on the $[0,1]$ interval. It has been a challenge to design regret-efficient randomized exploration algorithms in this setting. Maillard sampling~\cite{maillard13apprentissage}, an attractive alternative to Thompson sampling, has recently been shown to achieve competitive regret guarantees in the sub-Gaussian reward setting~\cite{bian2022maillard} while maintaining closed-form action probabilities, which is useful for offline policy evaluation. In this work, we propose the Kullback-Leibler Maillard Sampling (KL-MS) algorithm, a natural extension of Maillard sampling for achieving KL-style gap-dependent regret bound. We show that KL-MS enjoys the asymptotic optimality when the rewards are Bernoulli and has a worst-case regret bound of the form $O(\sqrt{\mu^*(1-\mu^*) K T \ln K} + K \ln T)$, where $\mu^*$ is the expected reward of the optimal arm, and $T$ is the time horizon length.
PopArt: Efficient Sparse Regression and Experimental Design for Optimal Sparse Linear Bandits
Oct 25, 2022

In sparse linear bandits, a learning agent sequentially selects an action and receive reward feedback, and the reward function depends linearly on a few coordinates of the covariates of the actions. This has applications in many real-world sequential decision making problems. In this paper, we propose a simple and computationally efficient sparse linear estimation method called PopArt that enjoys a tighter $\ell_1$ recovery guarantee compared to Lasso (Tibshirani, 1996) in many problems. Our bound naturally motivates an experimental design criterion that is convex and thus computationally efficient to solve. Based on our novel estimator and design criterion, we derive sparse linear bandit algorithms that enjoy improved regret upper bounds upon the state of the art (Hao et al., 2020), especially w.r.t. the geometry of the given action set. Finally, we prove a matching lower bound for sparse linear bandits in the data-poor regime, which closes the gap between upper and lower bounds in prior work.
On Efficient Online Imitation Learning via Classification
Sep 26, 2022

Imitation learning (IL) is a general learning paradigm for tackling sequential decision-making problems. Interactive imitation learning, where learners can interactively query for expert demonstrations, has been shown to achieve provably superior sample efficiency guarantees compared with its offline counterpart or reinforcement learning. In this work, we study classification-based online imitation learning (abbrev. $\textbf{COIL}$) and the fundamental feasibility to design oracle-efficient regret-minimization algorithms in this setting, with a focus on the general nonrealizable case. We make the following contributions: (1) we show that in the $\textbf{COIL}$ problem, any proper online learning algorithm cannot guarantee a sublinear regret in general; (2) we propose $\textbf{Logger}$, an improper online learning algorithmic framework, that reduces $\textbf{COIL}$ to online linear optimization, by utilizing a new definition of mixed policy class; (3) we design two oracle-efficient algorithms within the $\textbf{Logger}$ framework that enjoy different sample and interaction round complexity tradeoffs, and conduct finite-sample analyses to show their improvements over naive behavior cloning; (4) we show that under the standard complexity-theoretic assumptions, efficient dynamic regret minimization is infeasible in the $\textbf{Logger}$ framework. Our work puts classification-based online imitation learning, an important IL setup, into a firmer foundation.