 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Security is a Systems Problem
May 20, 2026We take the position that agent security must be approached as a systems problem: the AI model powering the agent must be treated as an untrusted component, and security invariants must be enforced at the system level. Through this lens, efforts to increase model robustness (the dominant viewpoint in the community) are insufficient on their own. Instead, we must complement existing efforts with techniques from the systems security domain. Based on our experience as cybersecurity researchers in operating systems, networks, formal methods, and adversarial machine learning, we articulate a set of core principles, grounded in decades of systems security research, that provide a foundation for designing agentic systems with predictable guarantees. As evidence, we analyze eleven representative real-world attacks on agents and discuss how systems principles, if realized, could have prevented these attacks. We also identify the research challenges that stand in the way of implementing these principles in agents.
How Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition
Mar 16, 2026LLM based agents are increasingly deployed in high stakes settings where they process external data sources such as emails, documents, and code repositories. This creates exposure to indirect prompt injection attacks, where adversarial instructions embedded in external content manipulate agent behavior without user awareness. A critical but underexplored dimension of this threat is concealment: since users tend to observe only an agent's final response, an attack can conceal its existence by presenting no clue of compromise in the final user facing response while successfully executing harmful actions. This leaves users unaware of the manipulation and likely to accept harmful outcomes as legitimate. We present findings from a large scale public red teaming competition evaluating this dual objective across three agent settings: tool calling, coding, and computer use. The competition attracted 464 participants who submitted 272000 attack attempts against 13 frontier models, yielding 8648 successful attacks across 41 scenarios. All models proved vulnerable, with attack success rates ranging from 0.5% (Claude Opus 4.5) to 8.5% (Gemini 2.5 Pro). We identify universal attack strategies that transfer across 21 of 41 behaviors and multiple model families, suggesting fundamental weaknesses in instruction following architectures. Capability and robustness showed weak correlation, with Gemini 2.5 Pro exhibiting both high capability and high vulnerability. To address benchmark saturation and obsoleteness, we will endeavor to deliver quarterly updates through continued red teaming competitions. We open source the competition environment for use in evaluations, along with 95 successful attacks against Qwen that did not transfer to any closed source model. We share model-specific attack data with respective frontier labs and the full dataset with the UK AISI and US CAISI to support robustness research.
Safety Alignment of LMs via Non-cooperative Games
Dec 23, 2025Ensuring the safety of language models (LMs) while maintaining their usefulness remains a critical challenge in AI alignment. Current approaches rely on sequential adversarial training: generating adversarial prompts and fine-tuning LMs to defend against them. We introduce a different paradigm: framing safety alignment as a non-zero-sum game between an Attacker LM and a Defender LM trained jointly via online reinforcement learning. Each LM continuously adapts to the other's evolving strategies, driving iterative improvement. Our method uses a preference-based reward signal derived from pairwise comparisons instead of point-wise scores, providing more robust supervision and potentially reducing reward hacking. Our RL recipe, AdvGame, shifts the Pareto frontier of safety and utility, yielding a Defender LM that is simultaneously more helpful and more resilient to adversarial attacks. In addition, the resulting Attacker LM converges into a strong, general-purpose red-teaming agent that can be directly deployed to probe arbitrary target models.
Privacy Blur: Quantifying Privacy and Utility for Image Data Release
Dec 18, 2025
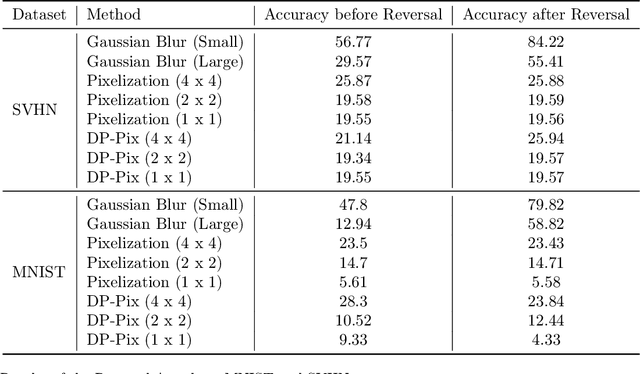

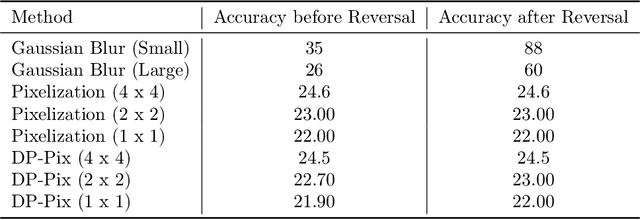
Image data collected in the wild often contains private information such as faces and license plates, and responsible data release must ensure that this information stays hidden. At the same time, released data should retain its usefulness for model-training. The standard method for private information obfuscation in images is Gaussian blurring. In this work, we show that practical implementations of Gaussian blurring are reversible enough to break privacy. We then take a closer look at the privacy-utility tradeoffs offered by three other obfuscation algorithms -- pixelization, pixelization and noise addition (DP-Pix), and cropping. Privacy is evaluated by reversal and discrimination attacks, while utility by the quality of the learnt representations when the model is trained on data with obfuscated faces. We show that the most popular industry-standard method, Gaussian blur is the least private of the four -- being susceptible to reversal attacks in its practical low-precision implementations. In contrast, pixelization and pixelization plus noise addition, when used at the right level of granularity, offer both privacy and utility for a number of computer vision tasks. We make our proposed methods together with suggested parameters available in a software package called Privacy Blur.
RL Is a Hammer and LLMs Are Nails: A Simple Reinforcement Learning Recipe for Strong Prompt Injection
Oct 06, 2025Prompt injection poses a serious threat to the reliability and safety of LLM agents. Recent defenses against prompt injection, such as Instruction Hierarchy and SecAlign, have shown notable robustness against static attacks. However, to more thoroughly evaluate the robustness of these defenses, it is arguably necessary to employ strong attacks such as automated red-teaming. To this end, we introduce RL-Hammer, a simple recipe for training attacker models that automatically learn to perform strong prompt injections and jailbreaks via reinforcement learning. RL-Hammer requires no warm-up data and can be trained entirely from scratch. To achieve high ASRs against industrial-level models with defenses, we propose a set of practical techniques that enable highly effective, universal attacks. Using this pipeline, RL-Hammer reaches a 98% ASR against GPT-4o and a $72\%$ ASR against GPT-5 with the Instruction Hierarchy defense. We further discuss the challenge of achieving high diversity in attacks, highlighting how attacker models tend to reward-hack diversity objectives. Finally, we show that RL-Hammer can evade multiple prompt injection detectors. We hope our work advances automatic red-teaming and motivates the development of stronger, more principled defenses. Code is available at https://github.com/facebookresearch/rl-injector.
Machine Learning with Privacy for Protected Attributes
Jun 24, 2025



Differential privacy (DP) has become the standard for private data analysis. Certain machine learning applications only require privacy protection for specific protected attributes. Using naive variants of differential privacy in such use cases can result in unnecessary degradation of utility. In this work, we refine the definition of DP to create a more general and flexible framework that we call feature differential privacy (FDP). Our definition is simulation-based and allows for both addition/removal and replacement variants of privacy, and can handle arbitrary and adaptive separation of protected and non-protected features. We prove the properties of FDP, such as adaptive composition, and demonstrate its implications for limiting attribute inference attacks. We also propose a modification of the standard DP-SGD algorithm that satisfies FDP while leveraging desirable properties such as amplification via sub-sampling. We apply our framework to various machine learning tasks and show that it can significantly improve the utility of DP-trained models when public features are available. For example, we train diffusion models on the AFHQ dataset of animal faces and observe a drastic improvement in FID compared to DP, from 286.7 to 101.9 at $\epsilon=8$, assuming that the blurred version of a training image is available as a public feature. Overall, our work provides a new approach to private data analysis that can help reduce the utility cost of DP while still providing strong privacy guarantees.
Learning-Time Encoding Shapes Unlearning in LLMs
Jun 18, 2025As large language models (LLMs) are increasingly deployed in the real world, the ability to ``unlearn'', or remove specific pieces of knowledge post hoc, has become essential for a variety of reasons ranging from privacy regulations to correcting outdated or harmful content. Prior work has proposed unlearning benchmarks and algorithms, and has typically assumed that the training process and the target model are fixed. In this work, we empirically investigate how learning-time choices in knowledge encoding impact the effectiveness of unlearning factual knowledge. Our experiments reveal two key findings: (1) learning with paraphrased descriptions improves unlearning performance and (2) unlearning individual piece of knowledge from a chunk of text is challenging. Our results suggest that learning-time knowledge encoding may play a central role in enabling reliable post-hoc unlearning.
Can We Infer Confidential Properties of Training Data from LLMs?
Jun 12, 2025Large language models (LLMs) are increasingly fine-tuned on domain-specific datasets to support applications in fields such as healthcare, finance, and law. These fine-tuning datasets often have sensitive and confidential dataset-level properties -- such as patient demographics or disease prevalence -- that are not intended to be revealed. While prior work has studied property inference attacks on discriminative models (e.g., image classification models) and generative models (e.g., GANs for image data), it remains unclear if such attacks transfer to LLMs. In this work, we introduce PropInfer, a benchmark task for evaluating property inference in LLMs under two fine-tuning paradigms: question-answering and chat-completion. Built on the ChatDoctor dataset, our benchmark includes a range of property types and task configurations. We further propose two tailored attacks: a prompt-based generation attack and a shadow-model attack leveraging word frequency signals. Empirical evaluations across multiple pretrained LLMs show the success of our attacks, revealing a previously unrecognized vulnerability in LLMs.
AbstentionBench: Reasoning LLMs Fail on Unanswerable Questions
Jun 10, 2025



For Large Language Models (LLMs) to be reliably deployed in both everyday and high-stakes domains, knowing when not to answer is equally critical as answering correctly. Real-world user queries, which can be underspecified, ill-posed, or fundamentally unanswerable, require LLMs to reason about uncertainty and selectively abstain -- i.e., refuse to answer definitively. However, abstention remains understudied, without a systematic evaluation framework for modern LLMs. In this work, we introduce AbstentionBench, a large-scale benchmark for holistically evaluating abstention across 20 diverse datasets, including questions with unknown answers, underspecification, false premises, subjective interpretations, and outdated information. Evaluating 20 frontier LLMs reveals abstention is an unsolved problem, and one where scaling models is of little use. While recent reasoning LLMs have shown impressive results in complex problem solving, surprisingly, we find that reasoning fine-tuning degrades abstention (by $24\%$ on average), even for math and science domains on which reasoning models are explicitly trained. We find that while a carefully crafted system prompt can boost abstention in practice, it does not resolve models' fundamental inability to reason about uncertainty. We release AbstentionBench to foster research into advancing LLM reliability.
Do LLMs Really Forget? Evaluating Unlearning with Knowledge Correlation and Confidence Awareness
Jun 06, 2025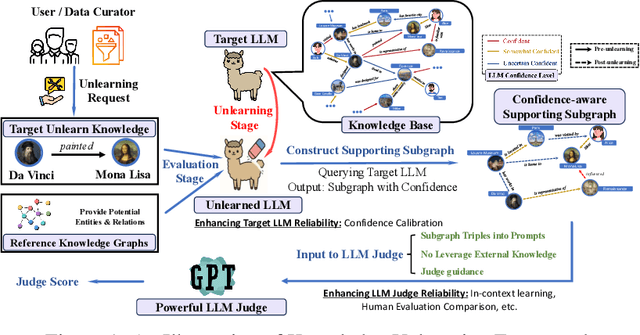
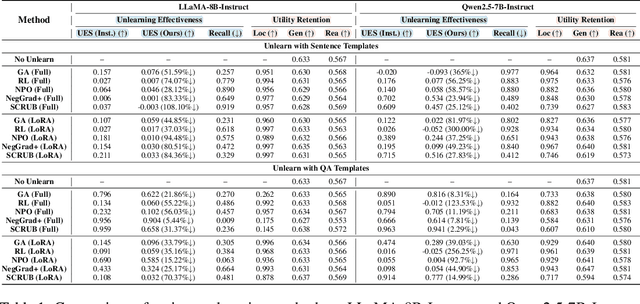
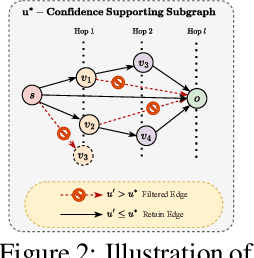
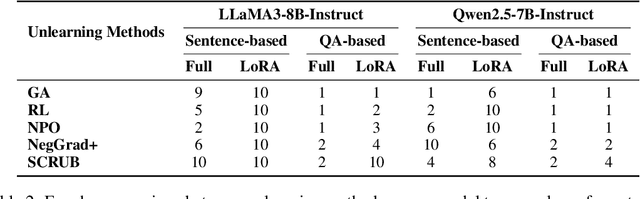
Machine unlearning techniques aim to mitigate unintended memorization in large language models (LLMs). However, existing approaches predominantly focus on the explicit removal of isolated facts, often overlooking latent inferential dependencies and the non-deterministic nature of knowledge within LLMs. Consequently, facts presumed forgotten may persist implicitly through correlated information. To address these challenges, we propose a knowledge unlearning evaluation framework that more accurately captures the implicit structure of real-world knowledge by representing relevant factual contexts as knowledge graphs with associated confidence scores. We further develop an inference-based evaluation protocol leveraging powerful LLMs as judges; these judges reason over the extracted knowledge subgraph to determine unlearning success. Our LLM judges utilize carefully designed prompts and are calibrated against human evaluations to ensure their trustworthiness and stability. Extensive experiments on our newly constructed benchmark demonstrate that our framework provides a more realistic and rigorous assessment of unlearning performance. Moreover, our findings reveal that current evaluation strategies tend to overestimate unlearning effectiveness. Our code is publicly available at https://github.com/Graph-COM/Knowledge_Unlearning.git.