 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate-RAG: Answering Multiple Queries with LLMs while Keeping Your Data Private
Nov 10, 2025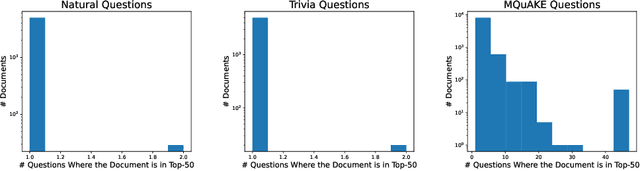
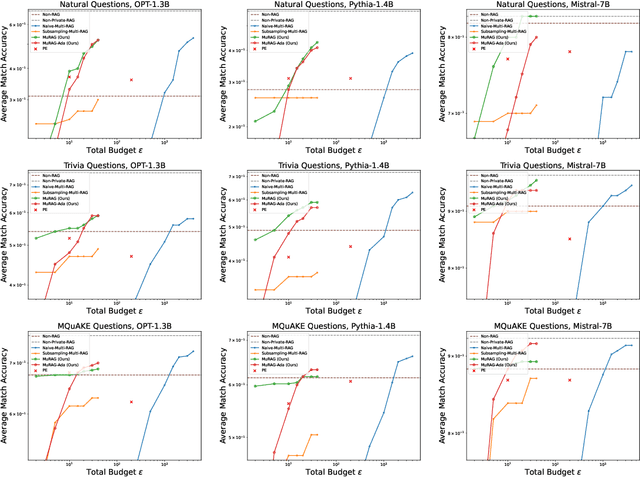

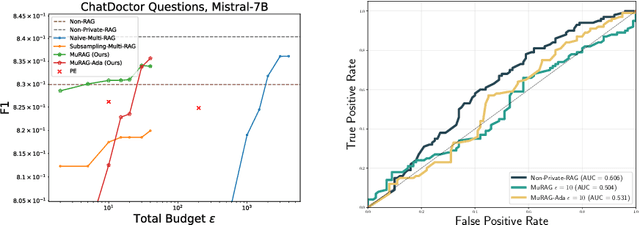
Retrieval-augmented generation (RAG) enhances large language models (LLMs) by retrieving documents from an external corpus at inference time. When this corpus contains sensitive information, however, unprotected RAG systems are at risk of leaking private information. Prior work has introduced differential privacy (DP) guarantees for RAG, but only in single-query settings, which fall short of realistic usage. In this paper, we study the more practical multi-query setting and propose two DP-RAG algorithms. The first, MURAG, leverages an individual privacy filter so that the accumulated privacy loss only depends on how frequently each document is retrieved rather than the total number of queries. The second, MURAG-ADA, further improves utility by privately releasing query-specific thresholds, enabling more precise selection of relevant documents. Our experiments across multiple LLMs and datasets demonstrate that the proposed methods scale to hundreds of queries within a practical DP budget ($\varepsilon\approx10$), while preserving meaningful utility.
Learning-Time Encoding Shapes Unlearning in LLMs
Jun 18, 2025As large language models (LLMs) are increasingly deployed in the real world, the ability to ``unlearn'', or remove specific pieces of knowledge post hoc, has become essential for a variety of reasons ranging from privacy regulations to correcting outdated or harmful content. Prior work has proposed unlearning benchmarks and algorithms, and has typically assumed that the training process and the target model are fixed. In this work, we empirically investigate how learning-time choices in knowledge encoding impact the effectiveness of unlearning factual knowledge. Our experiments reveal two key findings: (1) learning with paraphrased descriptions improves unlearning performance and (2) unlearning individual piece of knowledge from a chunk of text is challenging. Our results suggest that learning-time knowledge encoding may play a central role in enabling reliable post-hoc unlearning.
Can We Infer Confidential Properties of Training Data from LLMs?
Jun 12, 2025Large language models (LLMs) are increasingly fine-tuned on domain-specific datasets to support applications in fields such as healthcare, finance, and law. These fine-tuning datasets often have sensitive and confidential dataset-level properties -- such as patient demographics or disease prevalence -- that are not intended to be revealed. While prior work has studied property inference attacks on discriminative models (e.g., image classification models) and generative models (e.g., GANs for image data), it remains unclear if such attacks transfer to LLMs. In this work, we introduce PropInfer, a benchmark task for evaluating property inference in LLMs under two fine-tuning paradigms: question-answering and chat-completion. Built on the ChatDoctor dataset, our benchmark includes a range of property types and task configurations. We further propose two tailored attacks: a prompt-based generation attack and a shadow-model attack leveraging word frequency signals. Empirical evaluations across multiple pretrained LLMs show the success of our attacks, revealing a previously unrecognized vulnerability in LLMs.
Do LLMs Really Forget? Evaluating Unlearning with Knowledge Correlation and Confidence Awareness
Jun 06, 2025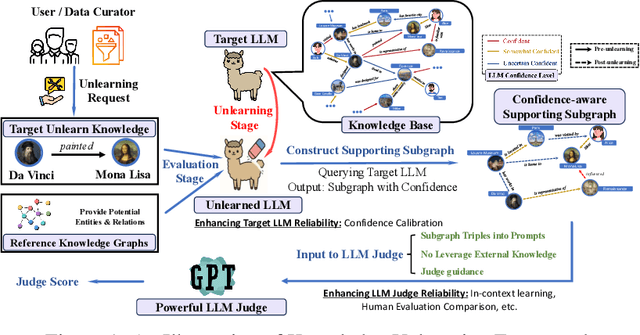
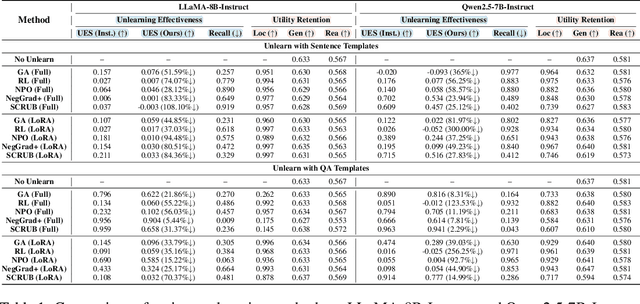
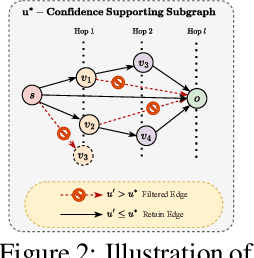
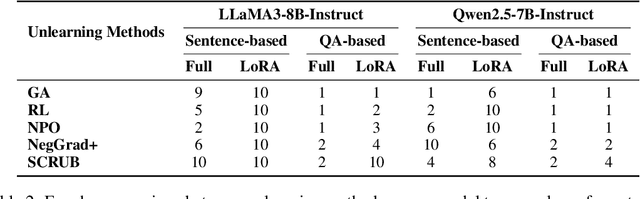
Machine unlearning techniques aim to mitigate unintended memorization in large language models (LLMs). However, existing approaches predominantly focus on the explicit removal of isolated facts, often overlooking latent inferential dependencies and the non-deterministic nature of knowledge within LLMs. Consequently, facts presumed forgotten may persist implicitly through correlated information. To address these challenges, we propose a knowledge unlearning evaluation framework that more accurately captures the implicit structure of real-world knowledge by representing relevant factual contexts as knowledge graphs with associated confidence scores. We further develop an inference-based evaluation protocol leveraging powerful LLMs as judges; these judges reason over the extracted knowledge subgraph to determine unlearning success. Our LLM judges utilize carefully designed prompts and are calibrated against human evaluations to ensure their trustworthiness and stability. Extensive experiments on our newly constructed benchmark demonstrate that our framework provides a more realistic and rigorous assessment of unlearning performance. Moreover, our findings reveal that current evaluation strategies tend to overestimate unlearning effectiveness. Our code is publicly available at https://github.com/Graph-COM/Knowledge_Unlearning.git.
Privacy-Preserving Retrieval Augmented Generation with Differential Privacy
Dec 06, 2024



With the recent remarkable advancement of large language models (LLMs), there has been a growing interest in utilizing them in the domains with highly sensitive data that lies outside their training data. For this purpose, retrieval augmented generation (RAG) is particularly effective -- it assists LLMs by directly providing relevant information from the external knowledge sources. However, without extra privacy safeguards, RAG outputs risk leaking sensitive information from the external data source. In this work, we explore RAG under differential privacy (DP), a formal guarantee of data privacy. The main challenge with differentially private RAG is how to generate long accurate answers within a moderate privacy budget. We address this by proposing an algorithm that smartly spends privacy budget only for the tokens that require the sensitive information and uses the non-private LLM for other tokens. Our extensive empirical evaluations reveal that our algorithm outperforms the non-RAG baseline under a reasonable privacy budget of $\epsilon\approx 10$ across different models and datasets.
Evaluating Deep Unlearning in Large Language Models
Oct 19, 2024

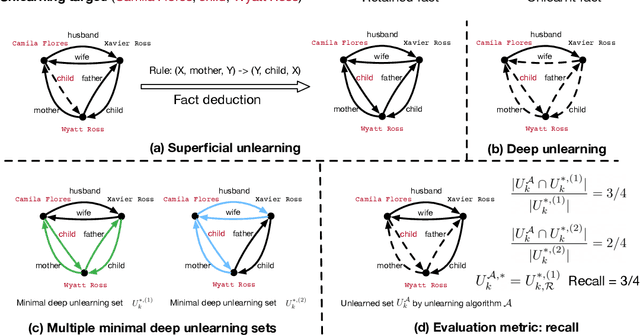

Machine unlearning is a key requirement of many data protection regulations such as GDPR. Prior work on unlearning has mostly considered superficial unlearning tasks where a single or a few related pieces of information are required to be removed. However, the task of unlearning a fact is much more challenging in recent large language models (LLMs), because the facts in LLMs can be deduced from each other. In this work, we investigate whether current unlearning methods for LLMs succeed beyond superficial unlearning of facts. Specifically, we formally propose a framework and a definition for deep unlearning facts that are interrelated. We design the metric, recall, to quantify the extent of deep unlearning. To systematically evaluate deep unlearning, we construct a synthetic dataset EDU-RELAT, which consists of a synthetic knowledge base of family relationships and biographies, together with a realistic logical rule set that connects them. We use this dataset to test four unlearning methods in four LLMs at different sizes. Our findings reveal that in the task of deep unlearning only a single fact, they either fail to properly unlearn with high recall, or end up unlearning many other irrelevant facts. Our dataset and code are publicly available at: https://github.com/wrh14/deep_unlearning.
Influence-based Attributions can be Manipulated
Sep 10, 2024Influence Functions are a standard tool for attributing predictions to training data in a principled manner and are widely used in applications such as data valuation and fairness. In this work, we present realistic incentives to manipulate influencebased attributions and investigate whether these attributions can be systematically tampered by an adversary. We show that this is indeed possible and provide efficient attacks with backward-friendly implementations. Our work raises questions on the reliability of influence-based attributions under adversarial circumstances.
On Speeding Up Language Model Evaluation
Jul 08, 2024Large language models (LLMs) currently dominate the field of natural language processing (NLP), representing the state-of-the-art across a diverse array of tasks. Developing a model of this nature, from training to inference, requires making numerous decisions which define a combinatorial search problem. For example, selecting the optimal pre-trained LLM, prompt, or hyperparameters to attain the best performance for a task often requires evaluating multiple candidates on an entire test set. This exhaustive evaluation can be time-consuming and costly, as both inference and metric computation with LLMs are resource-intensive. In this paper, we address the challenge of identifying the best method within a limited budget for evaluating methods on test examples. By leveraging the well-studied multi-armed bandit framework, which sequentially selects the next method-example pair to evaluate, our approach, combining multi-armed bandit algorithms with low-rank factorization, significantly reduces the required resources. Experiments show that our algorithms can identify the top-performing method using only 5-15\% of the typically needed resources, resulting in an 85-95\% reduction in cost.
Large Scale Knowledge Washing
May 28, 2024Large language models show impressive abilities in memorizing world knowledge, which leads to concerns regarding memorization of private information, toxic or sensitive knowledge, and copyrighted content. We introduce the problem of Large Scale Knowledge Washing, focusing on unlearning an extensive amount of factual knowledge. Previous unlearning methods usually define the reverse loss and update the model via backpropagation, which may affect the model's fluency and reasoning ability or even destroy the model due to extensive training with the reverse loss. Existing works introduce additional data from downstream tasks to prevent the model from losing capabilities, which requires downstream task awareness. Controlling the tradeoff of unlearning and maintaining existing capabilities is also challenging. To this end, we propose LAW (Large Scale Washing) to update the MLP layers in decoder-only large language models to perform knowledge washing, as inspired by model editing methods and based on the hypothesis that knowledge and reasoning are disentanglable. We derive a new objective with the knowledge to be unlearned to update the weights of certain MLP layers. Experimental results demonstrate the effectiveness of LAW in forgetting target knowledge while maintaining reasoning ability. The code will be open-sourced at https://github.com/wangyu-ustc/LargeScaleWashing.
Better Membership Inference Privacy Measurement through Discrepancy
May 24, 2024Membership Inference Attacks have emerged as a dominant method for empirically measuring privacy leakage from machine learning models. Here, privacy is measured by the {\em{advantage}} or gap between a score or a function computed on the training and the test data. A major barrier to the practical deployment of these attacks is that they do not scale to large well-generalized models -- either the advantage is relatively low, or the attack involves training multiple models which is highly compute-intensive. In this work, inspired by discrepancy theory, we propose a new empirical privacy metric that is an upper bound on the advantage of a family of membership inference attacks. We show that this metric does not involve training multiple models, can be applied to large Imagenet classification models in-the-wild, and has higher advantage than existing metrics on models trained with more recent and sophisticated training recipes. Motivated by our empirical results, we also propose new membership inference attacks tailored to these training losses.