 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Deep Unlearning in Large Language Models
Paper and Code


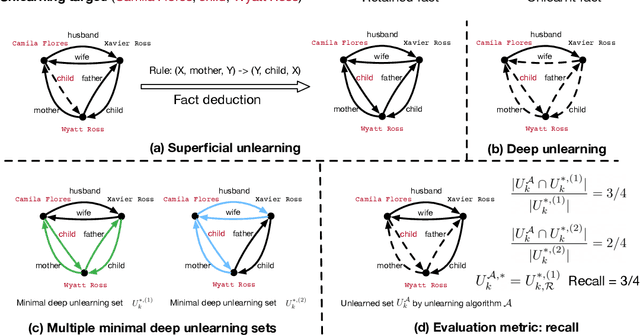

Machine unlearning is a key requirement of many data protection regulations such as GDPR. Prior work on unlearning has mostly considered superficial unlearning tasks where a single or a few related pieces of information are required to be removed. However, the task of unlearning a fact is much more challenging in recent large language models (LLMs), because the facts in LLMs can be deduced from each other. In this work, we investigate whether current unlearning methods for LLMs succeed beyond superficial unlearning of facts. Specifically, we formally propose a framework and a definition for deep unlearning facts that are interrelated. We design the metric, recall, to quantify the extent of deep unlearning. To systematically evaluate deep unlearning, we construct a synthetic dataset EDU-RELAT, which consists of a synthetic knowledge base of family relationships and biographies, together with a realistic logical rule set that connects them. We use this dataset to test four unlearning methods in four LLMs at different sizes. Our findings reveal that in the task of deep unlearning only a single fact, they either fail to properly unlearn with high recall, or end up unlearning many other irrelevant facts. Our dataset and code are publicly available at: https://github.com/wrh14/deep_unlearning.