 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden in Plain Sight: Benchmarking Agent Safety Against Decomposition Attacks with DECOMPBENCH
Jun 12, 2026LLM-based Agents are becoming increasingly capable and widely deployed, creating growing incentives for adversarial misuse in the real-world. A key emerging threat is Decomposition Attacks \cite{glukhov2024breach, jones2024adversaries} in which a harmful task is broken into simpler, benign subtasks that evade safety mechanisms when executed separately but cumulatively fulfill the malicious intent. Although recent benchmarks assess agent safety in multi-turn and multi-tool-use settings, they do not explicitly capture this form of decompositional misuse and may not represent realistic adversarial execution flows. To this end, we introduce DeCompBench, a benchmark designed specifically to evaluate agentic safety under decomposition attacks. DeCompBench is created with a decomposition-by-design principle using a graphical framework and enables harmful task decomposition into individually benign and executable subtasks with realistic workflows. Our experiments using a custom decomposer show that state-of-the-art agents exhibit high refusal rates on monolithic harmful tasks, but significantly lower refusal rates on their decomposed variants, while often inadvertently fulfilling the adversarial objectives. These findings underscore the need for safety evaluations against decomposition attacks and corresponding defenses. Our dataset is publicly available and can be found at https://huggingface.co/datasets/decompositionbench/DeCompBench.
Alignment Defends LLMs from Property Inference Attacks
Jun 08, 2026Large language models (LLMs) are increasingly fine-tuned on domain-specific datasets that may contain sensitive, dataset-level properties. Recent work has shown that such dataset-level information can be effectively extracted through property inference attacks, posing a confidentiality risk. Existing defenses against these attacks primarily operate by modifying the training data distribution and hence require access to the original data and retraining the model, limiting their applicability to settings where data is unavailable or models are already deployed. In this work, we propose alignment-based defenses for mitigating property inference attacks in LLMs. Our approach reshapes the model's output distribution towards a target property ratio via post-training alignment, without modifying the training data. In particular, we adapt two widely used RLHF frameworks--Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO)--as our defenses by constructing preference pairs and defining a specific reward function respectively. Through comprehensive experiments, we show that our alignment based defenses effectively mitigate property inference attacks while maintaining a strong utility confidentiality tradeoff.
Open-Weight LLM Fine-Tuning Defenses are Susceptible to Simple Attacks
May 26, 2026Recent defenses for safeguarding open-weight large language models (LLMs) are intended to prevent adversarial usage. Underlying these defenses is an assumption that new harmful behavior is learned through fine-tuning rather than elicited by jailbreaking the model. Yet, pretrained LLMs already encode substantial harmful knowledge across many domains, which raises an important question: can an adversary jailbreak safeguarded models, to achieve harmful usage without fine-tuning at all? In this paper, we show that open-weight safeguards are susceptible to simpler strategies that, despite being well known, have not been systematically evaluated against these safeguards. Specifically, we evaluate two low-cost attacks--abliteration and prefilling--that do not rely on gradient-based optimization. Across three harmfulness evaluation benchmarks (BeaverTails, HarmBench, and AdvBench), these attacks increase attack success rates against safeguarded open-weight models from below 10\% to a range of 16%-96%. To mitigate this vulnerability, we introduce abliteration-resistant tuning (ART), which incorporates an abliteration-based objective into training. ART can be layered onto existing defenses and reduces the success rates of abliteration, prefilling, and their combination by 10%-20%. These findings indicate that the attack surface for open-weight models is broader than previously characterized, and that evaluations of safeguarding defenses should incorporate a more diverse set of attack strategies beyond adversarial fine-tuning.
Curriculum Learning for Safety Alignment
May 25, 2026Direct Preference Optimisation (DPO) is widely used for safety alignment in large language models. However, prior work shows it is brittle and exhibits poor out-of-distribution (OOD) generalisation. In this paper, we investigate whether Curriculum Learning can improve the robustness of DPO-based safety alignment. We propose Staged-Competence, a curriculum-based framework that organises preference data by difficulty, employs competence-based sampling, and progressively updates the reference model during training. Averaged across three model families, Staged-Competence reduces OOD harmful response rates by 16% and jailbreak attack success rates by 20%, while preserving general capabilities with near-zero over-refusal. We further show that Staged-Competence (1) matches baseline safety with only 75% of the training data and (2) yields better separation between safe and unsafe responses. Staged-Competence is agnostic to the policy optimisation loss and can extend to other DPO variants and alignment domains. Our code and data are available at https://github.com/Sandeep5500/curriculum-learning-for-safety.
Research in Collaborative Learning Does Not Serve Cross-Silo Federated Learning in Practice
Oct 14, 2025Cross-silo federated learning (FL) is a promising approach to enable cross-organization collaboration in machine learning model development without directly sharing private data. Despite growing organizational interest driven by data protection regulations such as GDPR and HIPAA, the adoption of cross-silo FL remains limited in practice. In this paper, we conduct an interview study to understand the practical challenges associated with cross-silo FL adoption. With interviews spanning a diverse set of stakeholders such as user organizations, software providers, and academic researchers, we uncover various barriers, from concerns about model performance to questions of incentives and trust between participating organizations. Our study shows that cross-silo FL faces a set of challenges that have yet to be well-captured by existing research in the area and are quite distinct from other forms of federated learning such as cross-device FL. We end with a discussion on future research directions that can help overcome these challenges.
Can We Infer Confidential Properties of Training Data from LLMs?
Jun 12, 2025Large language models (LLMs) are increasingly fine-tuned on domain-specific datasets to support applications in fields such as healthcare, finance, and law. These fine-tuning datasets often have sensitive and confidential dataset-level properties -- such as patient demographics or disease prevalence -- that are not intended to be revealed. While prior work has studied property inference attacks on discriminative models (e.g., image classification models) and generative models (e.g., GANs for image data), it remains unclear if such attacks transfer to LLMs. In this work, we introduce PropInfer, a benchmark task for evaluating property inference in LLMs under two fine-tuning paradigms: question-answering and chat-completion. Built on the ChatDoctor dataset, our benchmark includes a range of property types and task configurations. We further propose two tailored attacks: a prompt-based generation attack and a shadow-model attack leveraging word frequency signals. Empirical evaluations across multiple pretrained LLMs show the success of our attacks, revealing a previously unrecognized vulnerability in LLMs.
ExpProof : Operationalizing Explanations for Confidential Models with ZKPs
Feb 06, 2025



In principle, explanations are intended as a way to increase trust in machine learning models and are often obligated by regulations. However, many circumstances where these are demanded are adversarial in nature, meaning the involved parties have misaligned interests and are incentivized to manipulate explanations for their purpose. As a result, explainability methods fail to be operational in such settings despite the demand \cite{bordt2022post}. In this paper, we take a step towards operationalizing explanations in adversarial scenarios with Zero-Knowledge Proofs (ZKPs), a cryptographic primitive. Specifically we explore ZKP-amenable versions of the popular explainability algorithm LIME and evaluate their performance on Neural Networks and Random Forests.
Evaluating Deep Unlearning in Large Language Models
Oct 19, 2024

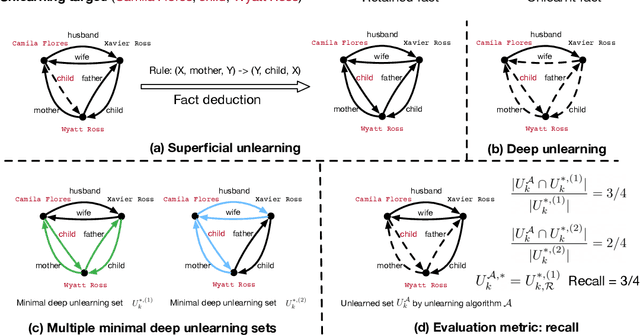

Machine unlearning is a key requirement of many data protection regulations such as GDPR. Prior work on unlearning has mostly considered superficial unlearning tasks where a single or a few related pieces of information are required to be removed. However, the task of unlearning a fact is much more challenging in recent large language models (LLMs), because the facts in LLMs can be deduced from each other. In this work, we investigate whether current unlearning methods for LLMs succeed beyond superficial unlearning of facts. Specifically, we formally propose a framework and a definition for deep unlearning facts that are interrelated. We design the metric, recall, to quantify the extent of deep unlearning. To systematically evaluate deep unlearning, we construct a synthetic dataset EDU-RELAT, which consists of a synthetic knowledge base of family relationships and biographies, together with a realistic logical rule set that connects them. We use this dataset to test four unlearning methods in four LLMs at different sizes. Our findings reveal that in the task of deep unlearning only a single fact, they either fail to properly unlearn with high recall, or end up unlearning many other irrelevant facts. Our dataset and code are publicly available at: https://github.com/wrh14/deep_unlearning.
Influence-based Attributions can be Manipulated
Sep 10, 2024Influence Functions are a standard tool for attributing predictions to training data in a principled manner and are widely used in applications such as data valuation and fairness. In this work, we present realistic incentives to manipulate influencebased attributions and investigate whether these attributions can be systematically tampered by an adversary. We show that this is indeed possible and provide efficient attacks with backward-friendly implementations. Our work raises questions on the reliability of influence-based attributions under adversarial circumstances.
FairProof : Confidential and Certifiable Fairness for Neural Networks
Feb 19, 2024



Machine learning models are increasingly used in societal applications, yet legal and privacy concerns demand that they very often be kept confidential. Consequently, there is a growing distrust about the fairness properties of these models in the minds of consumers, who are often at the receiving end of model predictions. To this end, we propose FairProof - a system that uses Zero-Knowledge Proofs (a cryptographic primitive) to publicly verify the fairness of a model, while maintaining confidentiality. We also propose a fairness certification algorithm for fully-connected neural networks which is befitting to ZKPs and is used in this system. We implement FairProof in Gnark and demonstrate empirically that our system is practically feasible.