 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Case for Computing on Unstructured Data
Sep 18, 2025Unstructured data, such as text, images, audio, and video, comprises the vast majority of the world's information, yet it remains poorly supported by traditional data systems that rely on structured formats for computation. We argue for a new paradigm, which we call computing on unstructured data, built around three stages: extraction of latent structure, transformation of this structure through data processing techniques, and projection back into unstructured formats. This bi-directional pipeline allows unstructured data to benefit from the analytical power of structured computation, while preserving the richness and accessibility of unstructured representations for human and AI consumption. We illustrate this paradigm through two use cases and present the research components that need to be developed in a new data system called MXFlow.
What Really is a Member? Discrediting Membership Inference via Poisoning
Jun 06, 2025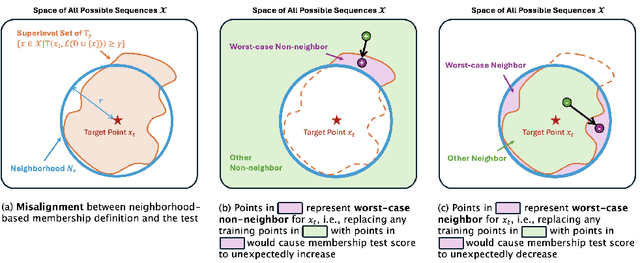

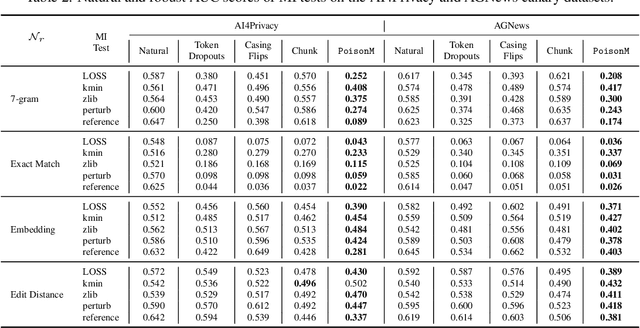
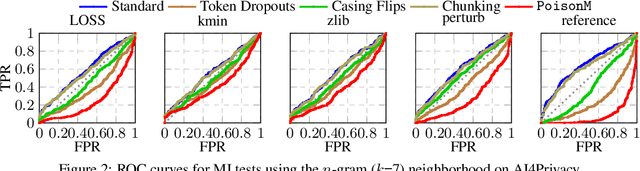
Membership inference tests aim to determine whether a particular data point was included in a language model's training set. However, recent works have shown that such tests often fail under the strict definition of membership based on exact matching, and have suggested relaxing this definition to include semantic neighbors as members as well. In this work, we show that membership inference tests are still unreliable under this relaxation - it is possible to poison the training dataset in a way that causes the test to produce incorrect predictions for a target point. We theoretically reveal a trade-off between a test's accuracy and its robustness to poisoning. We also present a concrete instantiation of this poisoning attack and empirically validate its effectiveness. Our results show that it can degrade the performance of existing tests to well below random.
SQUiD: Synthesizing Relational Databases from Unstructured Text
May 25, 2025Relational databases are central to modern data management, yet most data exists in unstructured forms like text documents. To bridge this gap, we leverage large language models (LLMs) to automatically synthesize a relational database by generating its schema and populating its tables from raw text. We introduce SQUiD, a novel neurosymbolic framework that decomposes this task into four stages, each with specialized techniques. Our experiments show that SQUiD consistently outperforms baselines across diverse datasets.
Pr$εε$mpt: Sanitizing Sensitive Prompts for LLMs
Apr 07, 2025The rise of large language models (LLMs) has introduced new privacy challenges, particularly during inference where sensitive information in prompts may be exposed to proprietary LLM APIs. In this paper, we address the problem of formally protecting the sensitive information contained in a prompt while maintaining response quality. To this end, first, we introduce a cryptographically inspired notion of a prompt sanitizer which transforms an input prompt to protect its sensitive tokens. Second, we propose Pr$\epsilon\epsilon$mpt, a novel system that implements a prompt sanitizer. Pr$\epsilon\epsilon$mpt categorizes sensitive tokens into two types: (1) those where the LLM's response depends solely on the format (such as SSNs, credit card numbers), for which we use format-preserving encryption (FPE); and (2) those where the response depends on specific values, (such as age, salary) for which we apply metric differential privacy (mDP). Our evaluation demonstrates that Pr$\epsilon\epsilon$mpt is a practical method to achieve meaningful privacy guarantees, while maintaining high utility compared to unsanitized prompts, and outperforming prior methods
FairProof : Confidential and Certifiable Fairness for Neural Networks
Feb 19, 2024



Machine learning models are increasingly used in societal applications, yet legal and privacy concerns demand that they very often be kept confidential. Consequently, there is a growing distrust about the fairness properties of these models in the minds of consumers, who are often at the receiving end of model predictions. To this end, we propose FairProof - a system that uses Zero-Knowledge Proofs (a cryptographic primitive) to publicly verify the fairness of a model, while maintaining confidentiality. We also propose a fairness certification algorithm for fully-connected neural networks which is befitting to ZKPs and is used in this system. We implement FairProof in Gnark and demonstrate empirically that our system is practically feasible.
Identifying and Mitigating the Security Risks of Generative AI
Aug 28, 2023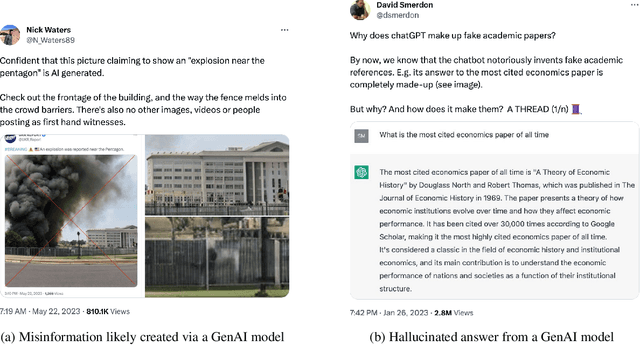
Every major technical invention resurfaces the dual-use dilemma -- the new technology has the potential to be used for good as well as for harm. Generative AI (GenAI) techniques, such as large language models (LLMs) and diffusion models, have shown remarkable capabilities (e.g., in-context learning, code-completion, and text-to-image generation and editing). However, GenAI can be used just as well by attackers to generate new attacks and increase the velocity and efficacy of existing attacks. This paper reports the findings of a workshop held at Google (co-organized by Stanford University and the University of Wisconsin-Madison) on the dual-use dilemma posed by GenAI. This paper is not meant to be comprehensive, but is rather an attempt to synthesize some of the interesting findings from the workshop. We discuss short-term and long-term goals for the community on this topic. We hope this paper provides both a launching point for a discussion on this important topic as well as interesting problems that the research community can work to address.
Can Membership Inferencing be Refuted?
Mar 08, 2023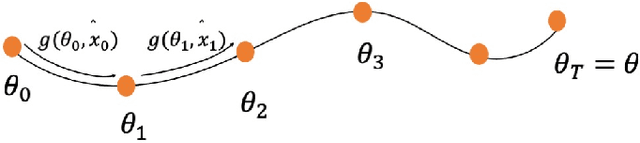

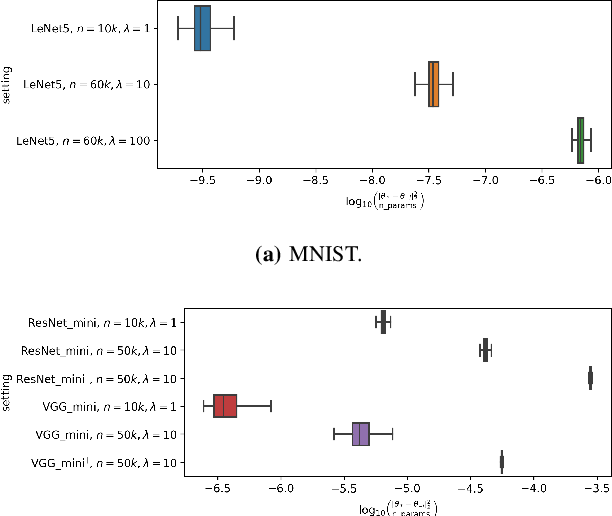

Membership inference (MI) attack is currently the most popular test for measuring privacy leakage in machine learning models. Given a machine learning model, a data point and some auxiliary information, the goal of an MI attack is to determine whether the data point was used to train the model. In this work, we study the reliability of membership inference attacks in practice. Specifically, we show that a model owner can plausibly refute the result of a membership inference test on a data point $x$ by constructing a proof of repudiation that proves that the model was trained without $x$. We design efficient algorithms to construct proofs of repudiation for all data points of the training dataset. Our empirical evaluation demonstrates the practical feasibility of our algorithm by constructing proofs of repudiation for popular machine learning models on MNIST and CIFAR-10. Consequently, our results call for a re-evaluation of the implications of membership inference attacks in practice.
A Shuffling Framework for Local Differential Privacy
Jun 11, 2021
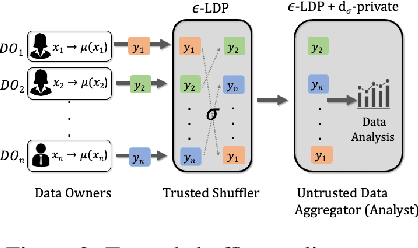
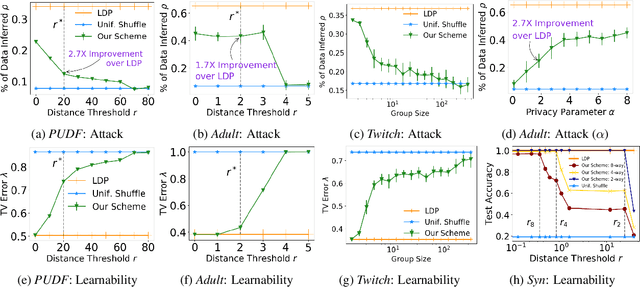
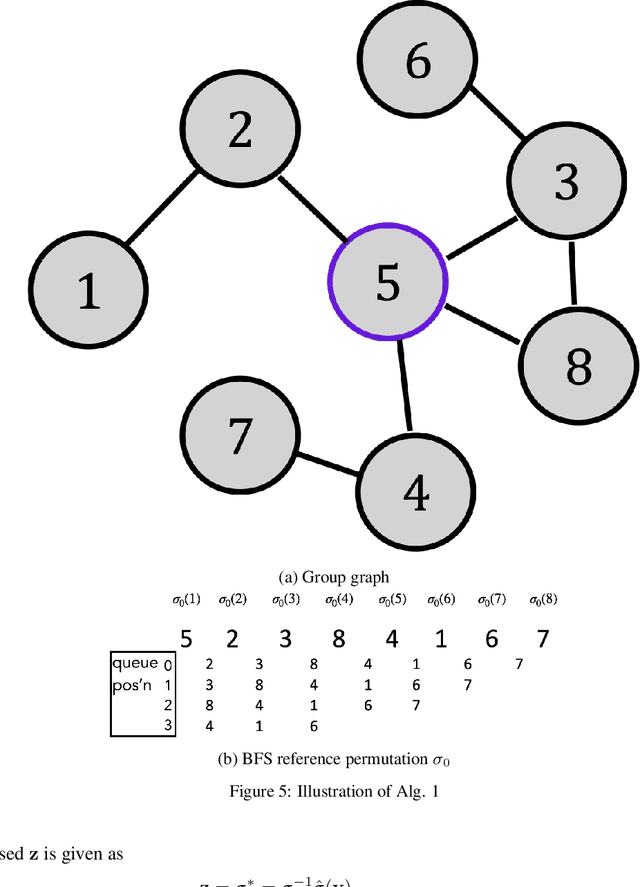
ldp deployments are vulnerable to inference attacks as an adversary can link the noisy responses to their identity and subsequently, auxiliary information using the order of the data. An alternative model, shuffle DP, prevents this by shuffling the noisy responses uniformly at random. However, this limits the data learnability -- only symmetric functions (input order agnostic) can be learned. In this paper, we strike a balance and propose a generalized shuffling framework that interpolates between the two deployment models. We show that systematic shuffling of the noisy responses can thwart specific inference attacks while retaining some meaningful data learnability. To this end, we propose a novel privacy guarantee, d-sigma privacy, that captures the privacy of the order of a data sequence. d-sigma privacy allows tuning the granularity at which the ordinal information is maintained, which formalizes the degree the resistance to inference attacks trading it off with data learnability. Additionally, we propose a novel shuffling mechanism that can achieve d-sigma privacy and demonstrate the practicality of our mechanism via evaluation on real-world datasets.
Data-Dependent Differentially Private Parameter Learning for Directed Graphical Models
May 30, 2019


Directed graphical models (DGMs) are a class of probabilistic models that are widely used for predictive analysis in sensitive domains, such as medical diagnostics. In this paper we present an algorithm for differentially private learning of the parameters of a DGM with a publicly known graph structure over fully observed data. Our solution optimizes for the utility of inference queries over the DGM and \textit{adds noise that is customized to the properties of the private input dataset and the graph structure of the DGM}. To the best of our knowledge, this is the first explicit data-dependent privacy budget allocation algorithm for DGMs. We compare our algorithm with a standard data-independent approach over a diverse suite of DGM benchmarks and demonstrate that our solution requires a privacy budget that is $3\times$ smaller to obtain the same or higher utility.