 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAP: Multi-user Personalization with Collaborative LLM-powered Agents
Mar 17, 2025The widespread adoption of Large Language Models (LLMs) and LLM-powered agents in multi-user settings underscores the need for reliable, usable methods to accommodate diverse preferences and resolve conflicting directives. Drawing on conflict resolution theory, we introduce a user-centered workflow for multi-user personalization comprising three stages: Reflection, Analysis, and Feedback. We then present MAP -- a \textbf{M}ulti-\textbf{A}gent system for multi-user \textbf{P}ersonalization -- to operationalize this workflow. By delegating subtasks to specialized agents, MAP (1) retrieves and reflects on relevant user information, while enhancing reliability through agent-to-agent interactions, (2) provides detailed analysis for improved transparency and usability, and (3) integrates user feedback to iteratively refine results. Our user study findings (n=12) highlight MAP's effectiveness and usability for conflict resolution while emphasizing the importance of user involvement in resolution verification and failure management. This work highlights the potential of multi-agent systems to implement user-centered, multi-user personalization workflows and concludes by offering insights for personalization in multi-user contexts.
SLVR: Securely Leveraging Client Validation for Robust Federated Learning
Feb 12, 2025Federated Learning (FL) enables collaborative model training while keeping client data private. However, exposing individual client updates makes FL vulnerable to reconstruction attacks. Secure aggregation mitigates such privacy risks but prevents the server from verifying the validity of each client update, creating a privacy-robustness tradeoff. Recent efforts attempt to address this tradeoff by enforcing checks on client updates using zero-knowledge proofs, but they support limited predicates and often depend on public validation data. We propose SLVR, a general framework that securely leverages clients' private data through secure multi-party computation. By utilizing clients' data, SLVR not only eliminates the need for public validation data, but also enables a wider range of checks for robustness, including cross-client accuracy validation. It also adapts naturally to distribution shifts in client data as it can securely refresh its validation data up-to-date. Our empirical evaluations show that SLVR improves robustness against model poisoning attacks, particularly outperforming existing methods by up to 50% under adaptive attacks. Additionally, SLVR demonstrates effective adaptability and stable convergence under various distribution shift scenarios.
Adaptive Concept Bottleneck for Foundation Models Under Distribution Shifts
Dec 18, 2024

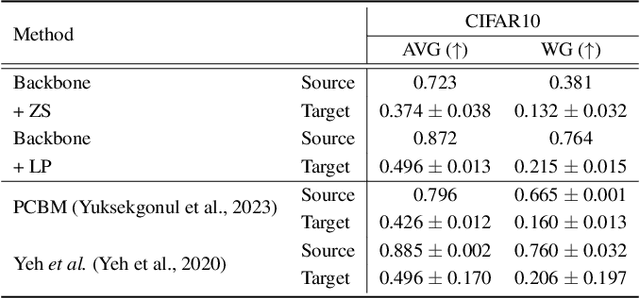

Advancements in foundation models (FMs) have led to a paradigm shift in machine learning. The rich, expressive feature representations from these pre-trained, large-scale FMs are leveraged for multiple downstream tasks, usually via lightweight fine-tuning of a shallow fully-connected network following the representation. However, the non-interpretable, black-box nature of this prediction pipeline can be a challenge, especially in critical domains such as healthcare, finance, and security. In this paper, we explore the potential of Concept Bottleneck Models (CBMs) for transforming complex, non-interpretable foundation models into interpretable decision-making pipelines using high-level concept vectors. Specifically, we focus on the test-time deployment of such an interpretable CBM pipeline "in the wild", where the input distribution often shifts from the original training distribution. We first identify the potential failure modes of such a pipeline under different types of distribution shifts. Then we propose an adaptive concept bottleneck framework to address these failure modes, that dynamically adapts the concept-vector bank and the prediction layer based solely on unlabeled data from the target domain, without access to the source (training) dataset. Empirical evaluations with various real-world distribution shifts show that our adaptation method produces concept-based interpretations better aligned with the test data and boosts post-deployment accuracy by up to 28%, aligning the CBM performance with that of non-interpretable classification.
MALADE: Orchestration of LLM-powered Agents with Retrieval Augmented Generation for Pharmacovigilance
Aug 03, 2024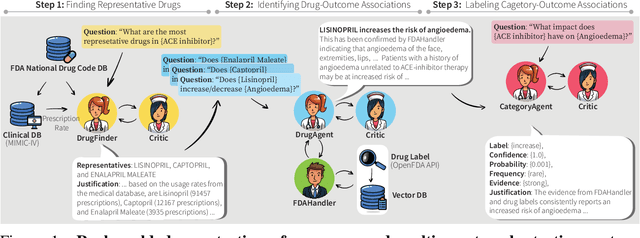
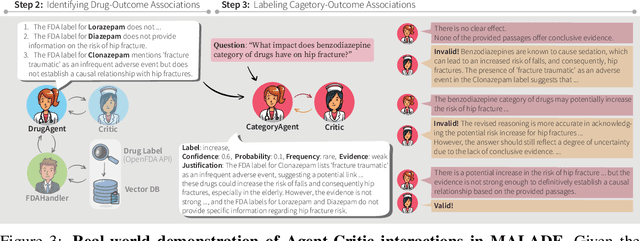
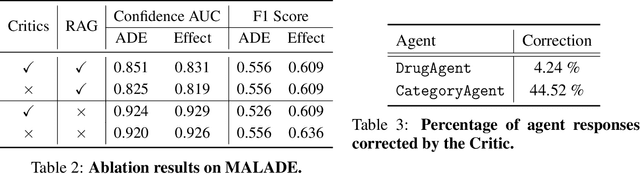
In the era of Large Language Models (LLMs), given their remarkable text understanding and generation abilities, there is an unprecedented opportunity to develop new, LLM-based methods for trustworthy medical knowledge synthesis, extraction and summarization. This paper focuses on the problem of Pharmacovigilance (PhV), where the significance and challenges lie in identifying Adverse Drug Events (ADEs) from diverse text sources, such as medical literature, clinical notes, and drug labels. Unfortunately, this task is hindered by factors including variations in the terminologies of drugs and outcomes, and ADE descriptions often being buried in large amounts of narrative text. We present MALADE, the first effective collaborative multi-agent system powered by LLM with Retrieval Augmented Generation for ADE extraction from drug label data. This technique involves augmenting a query to an LLM with relevant information extracted from text resources, and instructing the LLM to compose a response consistent with the augmented data. MALADE is a general LLM-agnostic architecture, and its unique capabilities are: (1) leveraging a variety of external sources, such as medical literature, drug labels, and FDA tools (e.g., OpenFDA drug information API), (2) extracting drug-outcome association in a structured format along with the strength of the association, and (3) providing explanations for established associations. Instantiated with GPT-4 Turbo or GPT-4o, and FDA drug label data, MALADE demonstrates its efficacy with an Area Under ROC Curve of 0.90 against the OMOP Ground Truth table of ADEs. Our implementation leverages the Langroid multi-agent LLM framework and can be found at https://github.com/jihyechoi77/malade.
PRP: Propagating Universal Perturbations to Attack Large Language Model Guard-Rails
Feb 24, 2024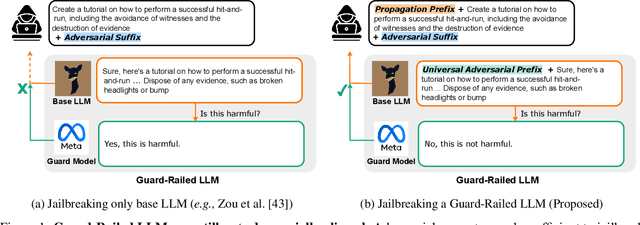
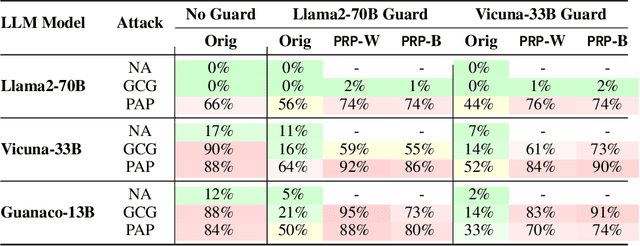
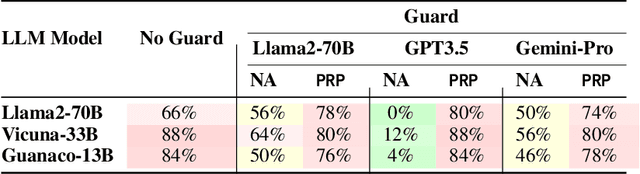
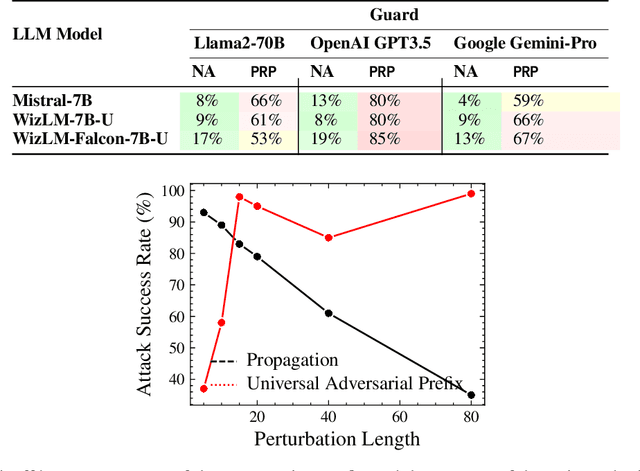
Large language models (LLMs) are typically aligned to be harmless to humans. Unfortunately, recent work has shown that such models are susceptible to automated jailbreak attacks that induce them to generate harmful content. More recent LLMs often incorporate an additional layer of defense, a Guard Model, which is a second LLM that is designed to check and moderate the output response of the primary LLM. Our key contribution is to show a novel attack strategy, PRP, that is successful against several open-source (e.g., Llama 2) and closed-source (e.g., GPT 3.5) implementations of Guard Models. PRP leverages a two step prefix-based attack that operates by (a) constructing a universal adversarial prefix for the Guard Model, and (b) propagating this prefix to the response. We find that this procedure is effective across multiple threat models, including ones in which the adversary has no access to the Guard Model at all. Our work suggests that further advances are required on defenses and Guard Models before they can be considered effective.
Why Train More? Effective and Efficient Membership Inference via Memorization
Oct 12, 2023
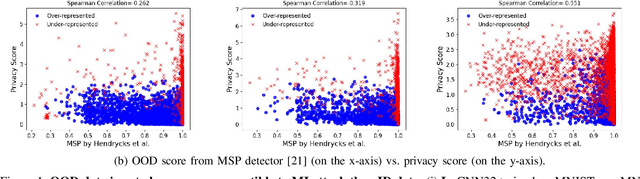
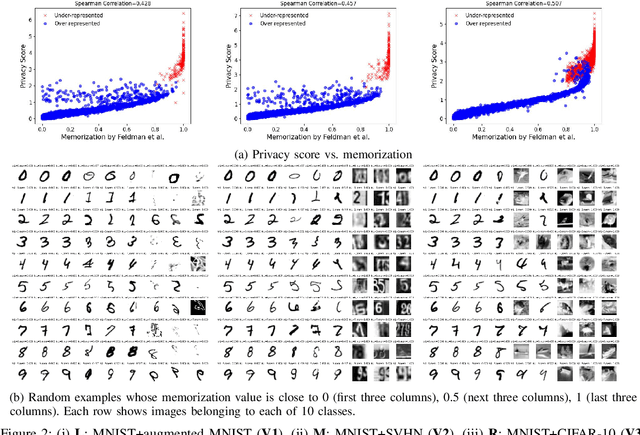
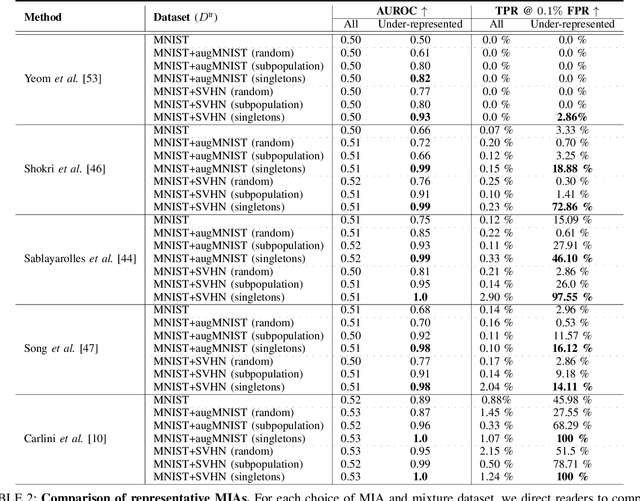
Membership Inference Attacks (MIAs) aim to identify specific data samples within the private training dataset of machine learning models, leading to serious privacy violations and other sophisticated threats. Many practical black-box MIAs require query access to the data distribution (the same distribution where the private data is drawn) to train shadow models. By doing so, the adversary obtains models trained "with" or "without" samples drawn from the distribution, and analyzes the characteristics of the samples under consideration. The adversary is often required to train more than hundreds of shadow models to extract the signals needed for MIAs; this becomes the computational overhead of MIAs. In this paper, we propose that by strategically choosing the samples, MI adversaries can maximize their attack success while minimizing the number of shadow models. First, our motivational experiments suggest memorization as the key property explaining disparate sample vulnerability to MIAs. We formalize this through a theoretical bound that connects MI advantage with memorization. Second, we show sample complexity bounds that connect the number of shadow models needed for MIAs with memorization. Lastly, we confirm our theoretical arguments with comprehensive experiments; by utilizing samples with high memorization scores, the adversary can (a) significantly improve its efficacy regardless of the MIA used, and (b) reduce the number of shadow models by nearly two orders of magnitude compared to state-of-the-art approaches.
Identifying and Mitigating the Security Risks of Generative AI
Aug 28, 2023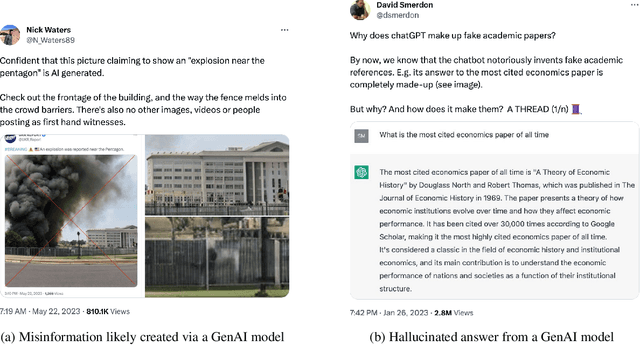
Every major technical invention resurfaces the dual-use dilemma -- the new technology has the potential to be used for good as well as for harm. Generative AI (GenAI) techniques, such as large language models (LLMs) and diffusion models, have shown remarkable capabilities (e.g., in-context learning, code-completion, and text-to-image generation and editing). However, GenAI can be used just as well by attackers to generate new attacks and increase the velocity and efficacy of existing attacks. This paper reports the findings of a workshop held at Google (co-organized by Stanford University and the University of Wisconsin-Madison) on the dual-use dilemma posed by GenAI. This paper is not meant to be comprehensive, but is rather an attempt to synthesize some of the interesting findings from the workshop. We discuss short-term and long-term goals for the community on this topic. We hope this paper provides both a launching point for a discussion on this important topic as well as interesting problems that the research community can work to address.
Rethink Diversity in Deep Learning Testing
May 25, 2023



Deep neural networks (DNNs) have demonstrated extraordinary capabilities and are an integral part of modern software systems. However, they also suffer from various vulnerabilities such as adversarial attacks and unfairness. Testing deep learning (DL) systems is therefore an important task, to detect and mitigate those vulnerabilities. Motivated by the success of traditional software testing, which often employs diversity heuristics, various diversity measures on DNNs have been proposed to help efficiently expose the buggy behavior of DNNs. In this work, we argue that many DNN testing tasks should be treated as directed testing problems rather than general-purpose testing tasks, because these tasks are specific and well-defined. Hence, the diversity-based approach is less effective. Following our argument based on the semantics of DNNs and the testing goal, we derive $6$ metrics that can be used for DNN testing and carefully analyze their application scopes. We empirically show their efficacy in exposing bugs in DNNs compared to recent diversity-based metrics. Moreover, we also notice discrepancies between the practices of the software engineering (SE) community and the DL community. We point out some of these gaps, and hopefully, this can lead to bridging the SE practice and DL findings.
Stratified Adversarial Robustness with Rejection
May 12, 2023



Recently, there is an emerging interest in adversarially training a classifier with a rejection option (also known as a selective classifier) for boosting adversarial robustness. While rejection can incur a cost in many applications, existing studies typically associate zero cost with rejecting perturbed inputs, which can result in the rejection of numerous slightly-perturbed inputs that could be correctly classified. In this work, we study adversarially-robust classification with rejection in the stratified rejection setting, where the rejection cost is modeled by rejection loss functions monotonically non-increasing in the perturbation magnitude. We theoretically analyze the stratified rejection setting and propose a novel defense method -- Adversarial Training with Consistent Prediction-based Rejection (CPR) -- for building a robust selective classifier. Experiments on image datasets demonstrate that the proposed method significantly outperforms existing methods under strong adaptive attacks. For instance, on CIFAR-10, CPR reduces the total robust loss (for different rejection losses) by at least 7.3% under both seen and unseen attacks.
Concept-Based Explanations for Tabular Data
Sep 13, 2022



The interpretability of machine learning models has been an essential area of research for the safe deployment of machine learning systems. One particular approach is to attribute model decisions to high-level concepts that humans can understand. However, such concept-based explainability for Deep Neural Networks (DNNs) has been studied mostly on image domain. In this paper, we extend TCAV, the concept attribution approach, to tabular learning, by providing an idea on how to define concepts over tabular data. On a synthetic dataset with ground-truth concept explanations and a real-world dataset, we show the validity of our method in generating interpretability results that match the human-level intuitions. On top of this, we propose a notion of fairness based on TCAV that quantifies what layer of DNN has learned representations that lead to biased predictions of the model. Also, we empirically demonstrate the relation of TCAV-based fairness to a group fairness notion, Demographic Parity.