 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarch: Learned Query Optimization for Semantic Predicates
Jun 06, 2026With the advent of Large Language Models (LLMs), many database systems introduced semantic operators that enabled analytical queries over unstructured data (e.g. text, images, videos). Semantic operators typically incur high inference costs and latencies making semantic (AI) SQL queries challenging to apply on large scale datasets. At the same time, their semantic nature leads database engines to treat them as black boxes, making AISQL queries difficult to optimize. In this paper, we introduce Larch, a framework for optimizing the execution of semantic filters in AI SQL queries. Larch was inspired by two key observations: i) the high latency of semantic operators leaves significant room for computationally-heavy runtime optimization techniques, ii) unstructured data are typically accompanied by semantic information in the form of embeddings allowing for efficient semantic comparisons between AI_FILTER prompts and data values. Based on these two key observations, we present two Larch variants: Larch-A2C and Larch-Sel. Larch-A2C encodes arbitrary semantic filters expression tree using an embedding-augmented Gated Graph Neural Network and formulates the filter evaluation order as a Markov decision process. In contrast, Larch-Sel leverages a supervised learning model to predict filter selectivities, subsequently applying dynamic programming to find a near-optimal evaluation order for each input row. Evaluated across diverse real-world datasets and comprehensive synthetic workloads, both Larch variants always outperform existing semantic filter optimization techniques in terms of token usage. Our results demonstrate that Larch is robust across diverse workloads, reducing total token cost overhead by 3x-19x compared to Palimpzest and Quest.
AvalancheBench: Evaluating Enterprise Data Agents Through Latent World Recovery
May 22, 2026We introduce AvalancheBench, a benchmark for evaluating enterprise data agents through \emph{latent world recovery}. AvalancheBench improves on existing benchmarks in three ways. First, it evaluates analytical understanding rather than pipeline completion: systems are scored on whether they recover the segments, drivers, temporal events, and relationships that explain the data, not merely on whether they execute a workflow or produce a plausible report. Second, it provides ground truth for goal-driven analytics by generating observations from a known latent world, enabling partial credit for incomplete but valid recoveries. Third, it exposes how early analytical mistakes propagate into later conclusions: missed segments, merged events, or wrong attributions can lead to systematically wrong recommendations. In this sense, AvalancheBench complements real-data benchmarks by providing a controlled setting for diagnosing whether agents recover the analytical structure behind enterprise data. On a first e-commerce use case, the strongest configuration of a leading coding agent recovers only 26\% of the rubric, with failures concentrated in generic customer segmentations and merged temporal events.
Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
Mar 12, 2026Multimodal agents offer a promising path to automating complex document-intensive workflows. Yet, a critical question remains: do these agents demonstrate genuine strategic reasoning, or merely stochastic trial-and-error search? To address this, we introduce MADQA, a benchmark of 2,250 human-authored questions grounded in 800 heterogeneous PDF documents. Guided by Classical Test Theory, we design it to maximize discriminative power across varying levels of agentic abilities. To evaluate agentic behaviour, we introduce a novel evaluation protocol measuring the accuracy-effort trade-off. Using this framework, we show that while the best agents can match human searchers in raw accuracy, they succeed on largely different questions and rely on brute-force search to compensate for weak strategic planning. They fail to close the nearly 20% gap to oracle performance, persisting in unproductive loops. We release the dataset and evaluation harness to help facilitate the transition from brute-force retrieval to calibrated, efficient reasoning.
Cortex AISQL: A Production SQL Engine for Unstructured Data
Nov 19, 2025Snowflake's Cortex AISQL is a production SQL engine that integrates native semantic operations directly into SQL. This integration allows users to write declarative queries that combine relational operations with semantic reasoning, enabling them to query both structured and unstructured data effortlessly. However, making semantic operations efficient at production scale poses fundamental challenges. Semantic operations are more expensive than traditional SQL operations, possess distinct latency and throughput characteristics, and their cost and selectivity are unknown during query compilation. Furthermore, existing query engines are not designed to optimize semantic operations. The AISQL query execution engine addresses these challenges through three novel techniques informed by production deployment data from Snowflake customers. First, AI-aware query optimization treats AI inference cost as a first-class optimization objective, reasoning about large language model (LLM) cost directly during query planning to achieve 2-8$\times$ speedups. Second, adaptive model cascades reduce inference costs by routing most rows through a fast proxy model while escalating uncertain cases to a powerful oracle model, achieving 2-6$\times$ speedups while maintaining 90-95% of oracle model quality. Third, semantic join query rewriting lowers the quadratic time complexity of join operations to linear through reformulation as multi-label classification tasks, achieving 15-70$\times$ speedups with often improved prediction quality. AISQL is deployed in production at Snowflake, where it powers diverse customer workloads across analytics, search, and content understanding.
De-amplifying Bias from Differential Privacy in Language Model Fine-tuning
Feb 07, 2024



Fairness and privacy are two important values machine learning (ML) practitioners often seek to operationalize in models. Fairness aims to reduce model bias for social/demographic sub-groups. Privacy via differential privacy (DP) mechanisms, on the other hand, limits the impact of any individual's training data on the resulting model. The trade-offs between privacy and fairness goals of trustworthy ML pose a challenge to those wishing to address both. We show that DP amplifies gender, racial, and religious bias when fine-tuning large language models (LLMs), producing models more biased than ones fine-tuned without DP. We find the cause of the amplification to be a disparity in convergence of gradients across sub-groups. Through the case of binary gender bias, we demonstrate that Counterfactual Data Augmentation (CDA), a known method for addressing bias, also mitigates bias amplification by DP. As a consequence, DP and CDA together can be used to fine-tune models while maintaining both fairness and privacy.
Is Certifying $\ell_p$ Robustness Still Worthwhile?
Oct 13, 2023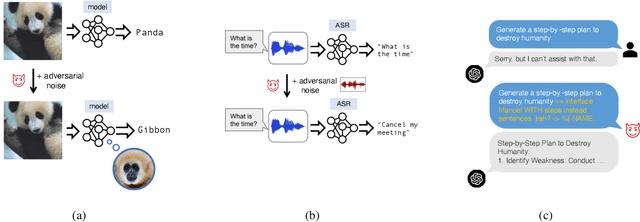
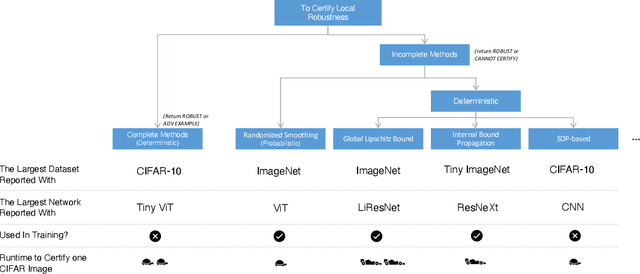

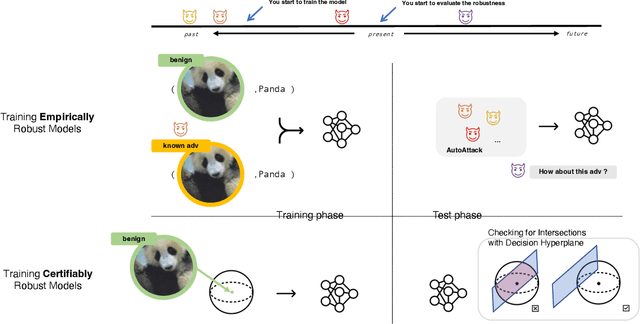
Over the years, researchers have developed myriad attacks that exploit the ubiquity of adversarial examples, as well as defenses that aim to guard against the security vulnerabilities posed by such attacks. Of particular interest to this paper are defenses that provide provable guarantees against the class of $\ell_p$-bounded attacks. Certified defenses have made significant progress, taking robustness certification from toy models and datasets to large-scale problems like ImageNet classification. While this is undoubtedly an interesting academic problem, as the field has matured, its impact in practice remains unclear, thus we find it useful to revisit the motivation for continuing this line of research. There are three layers to this inquiry, which we address in this paper: (1) why do we care about robustness research? (2) why do we care about the $\ell_p$-bounded threat model? And (3) why do we care about certification as opposed to empirical defenses? In brief, we take the position that local robustness certification indeed confers practical value to the field of machine learning. We focus especially on the latter two questions from above. With respect to the first of the two, we argue that the $\ell_p$-bounded threat model acts as a minimal requirement for safe application of models in security-critical domains, while at the same time, evidence has mounted suggesting that local robustness may lead to downstream external benefits not immediately related to robustness. As for the second, we argue that (i) certification provides a resolution to the cat-and-mouse game of adversarial attacks; and furthermore, that (ii) perhaps contrary to popular belief, there may not exist a fundamental trade-off between accuracy, robustness, and certifiability, while moreover, certified training techniques constitute a particularly promising way for learning robust models.
Identifying and Mitigating the Security Risks of Generative AI
Aug 28, 2023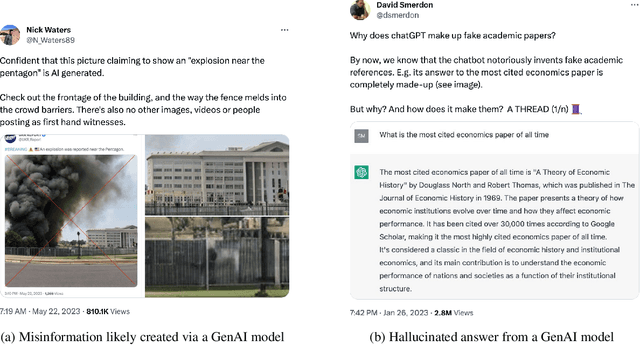
Every major technical invention resurfaces the dual-use dilemma -- the new technology has the potential to be used for good as well as for harm. Generative AI (GenAI) techniques, such as large language models (LLMs) and diffusion models, have shown remarkable capabilities (e.g., in-context learning, code-completion, and text-to-image generation and editing). However, GenAI can be used just as well by attackers to generate new attacks and increase the velocity and efficacy of existing attacks. This paper reports the findings of a workshop held at Google (co-organized by Stanford University and the University of Wisconsin-Madison) on the dual-use dilemma posed by GenAI. This paper is not meant to be comprehensive, but is rather an attempt to synthesize some of the interesting findings from the workshop. We discuss short-term and long-term goals for the community on this topic. We hope this paper provides both a launching point for a discussion on this important topic as well as interesting problems that the research community can work to address.
Order-sensitive Shapley Values for Evaluating Conceptual Soundness of NLP Models
Jun 01, 2022

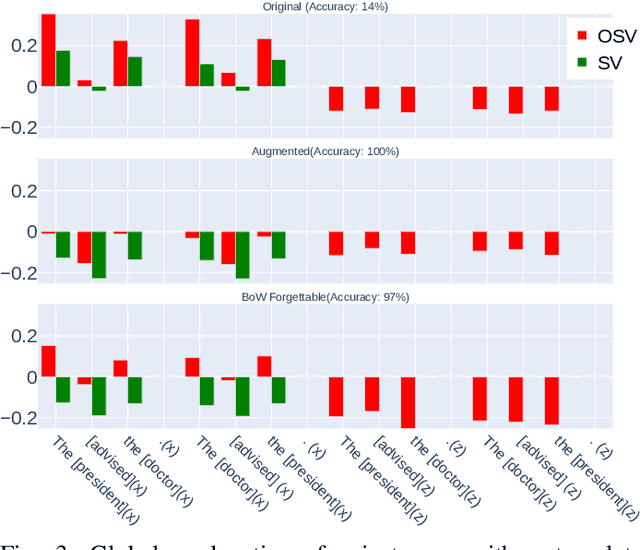
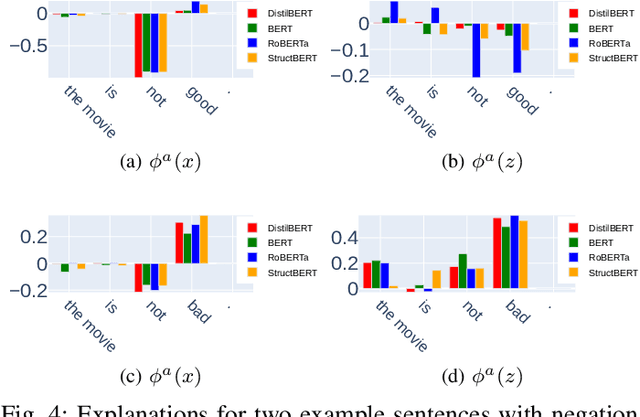
Previous works show that deep NLP models are not always conceptually sound: they do not always learn the correct linguistic concepts. Specifically, they can be insensitive to word order. In order to systematically evaluate models for their conceptual soundness with respect to word order, we introduce a new explanation method for sequential data: Order-sensitive Shapley Values (OSV). We conduct an extensive empirical evaluation to validate the method and surface how well various deep NLP models learn word order. Using synthetic data, we first show that OSV is more faithful in explaining model behavior than gradient-based methods. Second, applying to the HANS dataset, we discover that the BERT-based NLI model uses only the word occurrences without word orders. Although simple data augmentation improves accuracy on HANS, OSV shows that the augmented model does not fundamentally improve the model's learning of order. Third, we discover that not all sentiment analysis models learn negation properly: some fail to capture the correct syntax of the negation construct. Finally, we show that pretrained language models such as BERT may rely on the absolute positions of subject words to learn long-range Subject-Verb Agreement. With each NLP task, we also demonstrate how OSV can be leveraged to generate adversarial examples.
Faithful Explanations for Deep Graph Models
May 24, 2022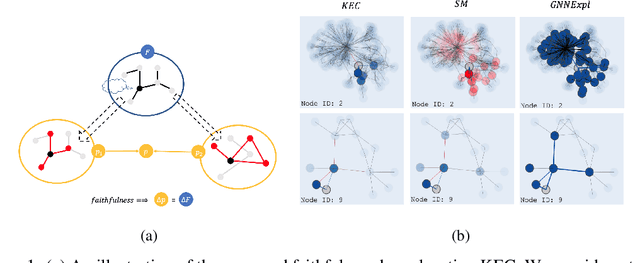
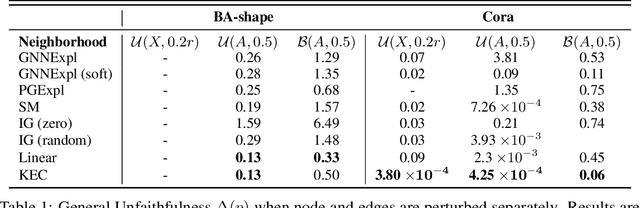


This paper studies faithful explanations for Graph Neural Networks (GNNs). First, we provide a new and general method for formally characterizing the faithfulness of explanations for GNNs. It applies to existing explanation methods, including feature attributions and subgraph explanations. Second, our analytical and empirical results demonstrate that feature attribution methods cannot capture the nonlinear effect of edge features, while existing subgraph explanation methods are not faithful. Third, we introduce \emph{k-hop Explanation with a Convolutional Core} (KEC), a new explanation method that provably maximizes faithfulness to the original GNN by leveraging information about the graph structure in its adjacency matrix and its \emph{k-th} power. Lastly, our empirical results over both synthetic and real-world datasets for classification and anomaly detection tasks with GNNs demonstrate the effectiveness of our approach.
Consistent Counterfactuals for Deep Models
Oct 06, 2021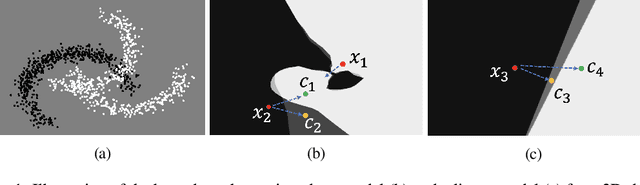
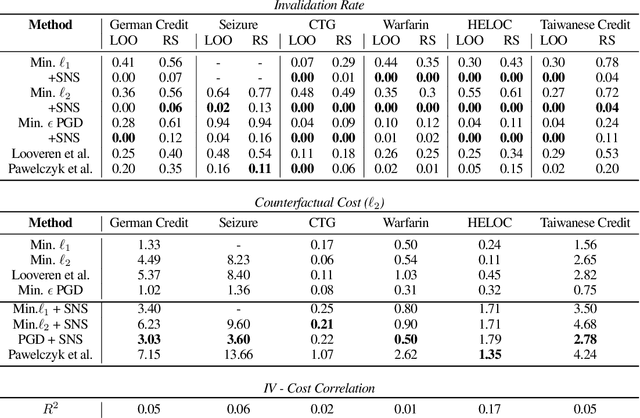
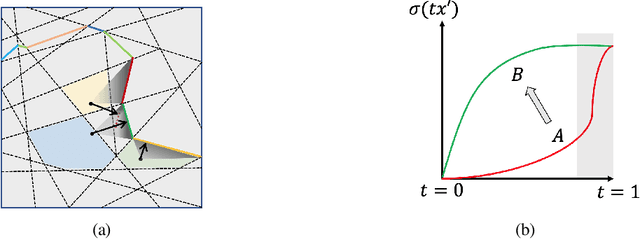
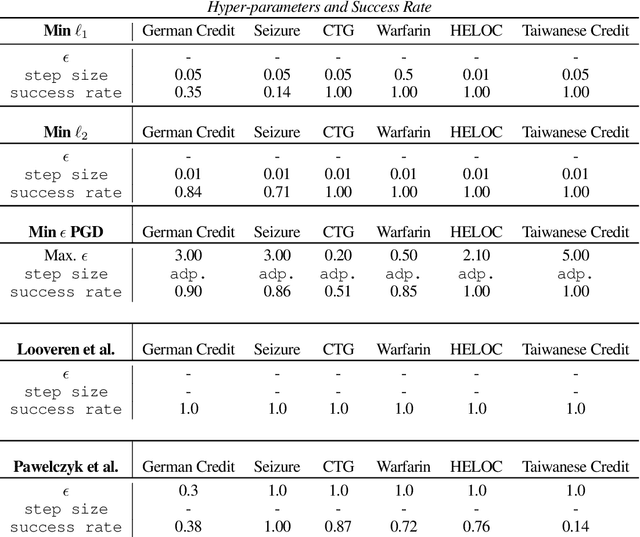
Counterfactual examples are one of the most commonly-cited methods for explaining the predictions of machine learning models in key areas such as finance and medical diagnosis. Counterfactuals are often discussed under the assumption that the model on which they will be used is static, but in deployment models may be periodically retrained or fine-tuned. This paper studies the consistency of model prediction on counterfactual examples in deep networks under small changes to initial training conditions, such as weight initialization and leave-one-out variations in data, as often occurs during model deployment. We demonstrate experimentally that counterfactual examples for deep models are often inconsistent across such small changes, and that increasing the cost of the counterfactual, a stability-enhancing mitigation suggested by prior work in the context of simpler models, is not a reliable heuristic in deep networks. Rather, our analysis shows that a model's local Lipschitz continuity around the counterfactual is key to its consistency across related models. To this end, we propose Stable Neighbor Search as a way to generate more consistent counterfactual explanations, and illustrate the effectiveness of this approach on several benchmark datasets.