 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful Explanations for Deep Graph Models
Paper and Code
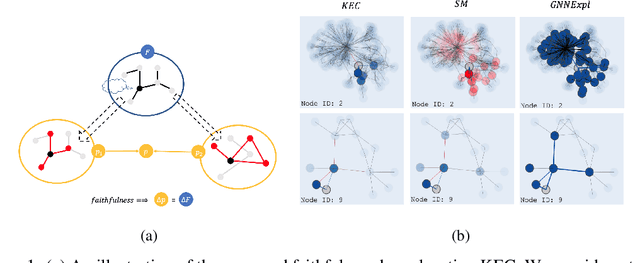
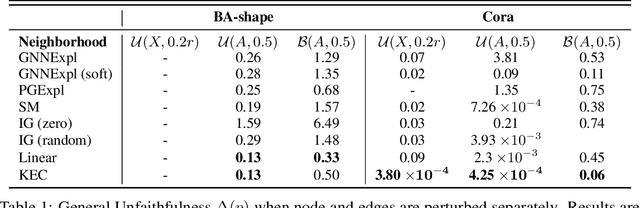


This paper studies faithful explanations for Graph Neural Networks (GNNs). First, we provide a new and general method for formally characterizing the faithfulness of explanations for GNNs. It applies to existing explanation methods, including feature attributions and subgraph explanations. Second, our analytical and empirical results demonstrate that feature attribution methods cannot capture the nonlinear effect of edge features, while existing subgraph explanation methods are not faithful. Third, we introduce \emph{k-hop Explanation with a Convolutional Core} (KEC), a new explanation method that provably maximizes faithfulness to the original GNN by leveraging information about the graph structure in its adjacency matrix and its \emph{k-th} power. Lastly, our empirical results over both synthetic and real-world datasets for classification and anomaly detection tasks with GNNs demonstrate the effectiveness of our approach.