 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEGO-MOF: Equivariant Latent Manipulation for Editable, Generative, and Optimizable MOF Design
Apr 15, 2026Metal-organic frameworks (MOFs) are highly promising for carbon capture, yet navigating their vast design space remains challenging. Recent deep generative models enable de novo MOF design but primarily act as feed-forward structure generators. By heavily relying on predefined building block libraries and non-differentiable post-optimization, they fundamentally sever the information flow required for continuous structural editing. Here, we propose a target-driven generative framework focused on continuous structural manipulation. At its core is LinkerVAE, which maps discrete 3D chemical graphs into a continuous, SE(3)-equivariant latent space. This smooth manifold unlocks geometry-aware manipulations, including implicit chemical style transfer and zero-shot isoreticular expansion. Building upon this, we introduce a test-time optimization (TTO) strategy, utilizing an accurate surrogate model to continuously optimize the latent graphs of existing MOFs toward desired properties. This approach systematically enhances carbon capture performance, achieving a striking average relative boost of 147.5% in pure CO2 uptake while strictly preserving structural validity. Integrated with a latent diffusion model and rigid-body assembly for full MOF construction, our framework establishes a scalable, fully differentiable pathway for both the automated discovery, targeted optimization and editing of functional materials.
MedLoc-R1: Performance-Aware Curriculum Reward Scheduling for GRPO-Based Medical Visual Grounding
Mar 30, 2026Medical visual grounding serves as a crucial foundation for fine-grained multimodal reasoning and interpretable clinical decision support. Despite recent advances in reinforcement learning (RL) for grounding tasks, existing approaches such as Group Relative Policy Optimization~(GRPO) suffer from severe reward sparsity when directly applied to medical images, primarily due to the inherent difficulty of localizing small or ambiguous regions of interest, which is further exacerbated by the rigid and suboptimal nature of fixed IoU-based reward schemes in RL. This leads to vanishing policy gradients and stagnated optimization, particularly during early training. To address this challenge, we propose MedLoc-R1, a performance-aware reward scheduling framework that progressively tightens the reward criterion in accordance with model readiness. MedLoc-R1 introduces a sliding-window performance tracker and a multi-condition update rule that automatically adjust the reward schedule from dense, easily obtainable signals to stricter, fine-grained localization requirements, while preserving the favorable properties of GRPO without introducing auxiliary networks or additional gradient paths. Experiments on three medical visual grounding benchmarks demonstrate that MedLoc-R1 consistently improves both localization accuracy and training stability over GRPO-based baselines. Our framework offers a general, lightweight, and effective solution for RL-based grounding in high-stakes medical applications. Code \& checkpoints are available at \hyperlink{}{https://github.com/MembrAI/MedLoc-R1}.
ATG-MoE: Autoregressive trajectory generation with mixture-of-experts for assembly skill learning
Mar 19, 2026Flexible manufacturing requires robot systems that can adapt to constantly changing tasks, objects, and environments. However, traditional robot programming is labor-intensive and inflexible, while existing learning-based assembly methods often suffer from weak positional generalization, complex multi-stage designs, and limited multi-skill integration capability. To address these issues, this paper proposes ATG-MoE, an end-to-end autoregressive trajectory generation method with mixture of experts for assembly skill learning from demonstration. The proposed method establishes a closed-loop mapping from multi-modal inputs, including RGB-D observations, natural language instructions, and robot proprioception to manipulation trajectories. It integrates multi-modal feature fusion for scene and task understanding, autoregressive sequence modeling for temporally coherent trajectory generation, and a mixture-of-experts architecture for unified multi-skill learning. In contrast to conventional methods that separate visual perception and control or train different skills independently, ATG-MoE directly incorporates visual information into trajectory generation and supports efficient multi-skill integration within a single model. We train and evaluate the proposed method on eight representative assembly skills from a pressure-reducing valve assembly task. Experimental results show that ATG-MoE achieves strong overall performance in simulation, with an average grasp success rate of 96.3% and an average overall success rate of 91.8%, while also demonstrating strong generalization and effective multi-skill integration. Real-world experiments further verify its practicality for multi-skill industrial assembly. The project page can be found at https://hwh23.github.io/ATG-MoE
ForeHOI: Feed-forward 3D Object Reconstruction from Daily Hand-Object Interaction Videos
Feb 05, 2026The ubiquity of monocular videos capturing daily hand-object interactions presents a valuable resource for embodied intelligence. While 3D hand reconstruction from in-the-wild videos has seen significant progress, reconstructing the involved objects remains challenging due to severe occlusions and the complex, coupled motion of the camera, hands, and object. In this paper, we introduce ForeHOI, a novel feed-forward model that directly reconstructs 3D object geometry from monocular hand-object interaction videos within one minute of inference time, eliminating the need for any pre-processing steps. Our key insight is that, the joint prediction of 2D mask inpainting and 3D shape completion in a feed-forward framework can effectively address the problem of severe occlusion in monocular hand-held object videos, thereby achieving results that outperform the performance of optimization-based methods. The information exchanges between the 2D and 3D shape completion boosts the overall reconstruction quality, enabling the framework to effectively handle severe hand-object occlusion. Furthermore, to support the training of our model, we contribute the first large-scale, high-fidelity synthetic dataset of hand-object interactions with comprehensive annotations. Extensive experiments demonstrate that ForeHOI achieves state-of-the-art performance in object reconstruction, significantly outperforming previous methods with around a 100x speedup. Code and data are available at: https://github.com/Tao-11-chen/ForeHOI.
Embodied Intelligent Industrial Robotics: Concepts and Techniques
May 15, 2025
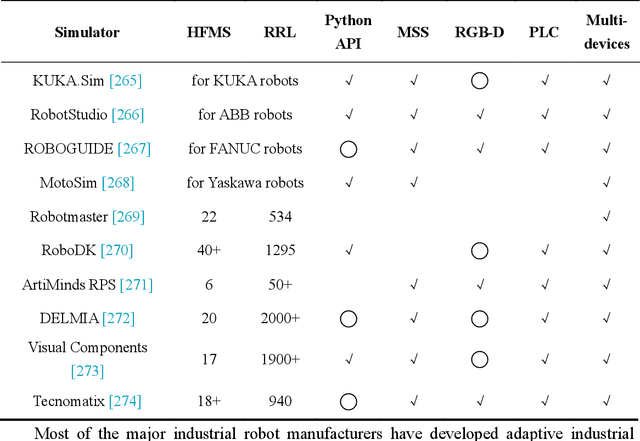

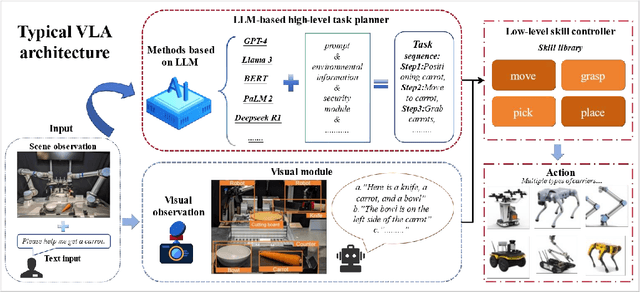
In recent years, embodied intelligent robotics (EIR) has made significant progress in multi-modal perception, autonomous decision-making, and physical interaction. Some robots have already been tested in general-purpose scenarios such as homes and shopping malls. We aim to advance the research and application of embodied intelligence in industrial scenes. However, current EIR lacks a deep understanding of industrial environment semantics and the normative constraints between industrial operating objects. To address this gap, this paper first reviews the history of industrial robotics and the mainstream EIR frameworks. We then introduce the concept of the embodied intelligent industrial robotics (EIIR) and propose a knowledge-driven EIIR technology framework for industrial environments. The framework includes four main modules: world model, high-level task planner, low-level skill controller, and simulator. We also review the current development of technologies related to each module and highlight recent progress in adapting them to industrial applications. Finally, we summarize the key challenges EIIR faces in industrial scenarios and suggest future research directions. We believe that EIIR technology will shape the next generation of industrial robotics. Industrial systems based on embodied intelligent industrial robots offer strong potential for enabling intelligent manufacturing. We will continue to track and summarize new research in this area and hope this review will serve as a valuable reference for scholars and engineers interested in industrial embodied intelligence. Together, we can help drive the rapid advancement and application of this technology. The associated project can be found at https://github.com/jackyzengl/EIIR.
Efficient Sparse Attention needs Adaptive Token Release
Jul 02, 2024



In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide array of text-centric tasks. However, their `large' scale introduces significant computational and storage challenges, particularly in managing the key-value states of the transformer, which limits their wider applicability. Therefore, we propose to adaptively release resources from caches and rebuild the necessary key-value states. Particularly, we accomplish this by a lightweight controller module to approximate an ideal top-$K$ sparse attention. This module retains the tokens with the highest top-$K$ attention weights and simultaneously rebuilds the discarded but necessary tokens, which may become essential for future decoding. Comprehensive experiments in natural language generation and modeling reveal that our method is not only competitive with full attention in terms of performance but also achieves a significant throughput improvement of up to 221.8%. The code for replication is available on the https://github.com/WHUIR/ADORE.
GiPH: Generalizable Placement Learning for Adaptive Heterogeneous Computing
May 23, 2023Careful placement of a computational application within a target device cluster is critical for achieving low application completion time. The problem is challenging due to its NP-hardness and combinatorial nature. In recent years, learning-based approaches have been proposed to learn a placement policy that can be applied to unseen applications, motivated by the problem of placing a neural network across cloud servers. These approaches, however, generally assume the device cluster is fixed, which is not the case in mobile or edge computing settings, where heterogeneous devices move in and out of range for a particular application. We propose a new learning approach called GiPH, which learns policies that generalize to dynamic device clusters via 1) a novel graph representation gpNet that efficiently encodes the information needed for choosing a good placement, and 2) a scalable graph neural network (GNN) that learns a summary of the gpNet information. GiPH turns the placement problem into that of finding a sequence of placement improvements, learning a policy for selecting this sequence that scales to problems of arbitrary size. We evaluate GiPH with a wide range of task graphs and device clusters and show that our learned policy rapidly find good placements for new problem instances. GiPH finds placements with up to 30.5% lower completion times, searching up to 3X faster than other search-based placement policies.
Faithful Explanations for Deep Graph Models
May 24, 2022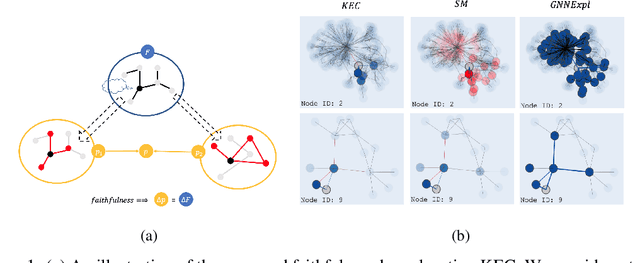
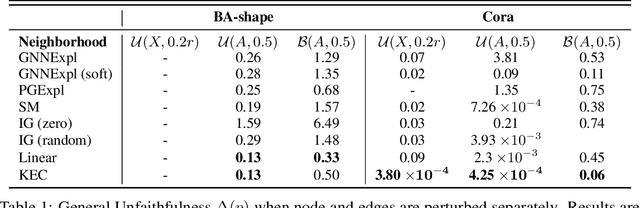


This paper studies faithful explanations for Graph Neural Networks (GNNs). First, we provide a new and general method for formally characterizing the faithfulness of explanations for GNNs. It applies to existing explanation methods, including feature attributions and subgraph explanations. Second, our analytical and empirical results demonstrate that feature attribution methods cannot capture the nonlinear effect of edge features, while existing subgraph explanation methods are not faithful. Third, we introduce \emph{k-hop Explanation with a Convolutional Core} (KEC), a new explanation method that provably maximizes faithfulness to the original GNN by leveraging information about the graph structure in its adjacency matrix and its \emph{k-th} power. Lastly, our empirical results over both synthetic and real-world datasets for classification and anomaly detection tasks with GNNs demonstrate the effectiveness of our approach.