 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONClave -- Secure and Robust Cooperative Perception for CAVs Using Authenticated Consensus and Trust Scoring
Sep 04, 2024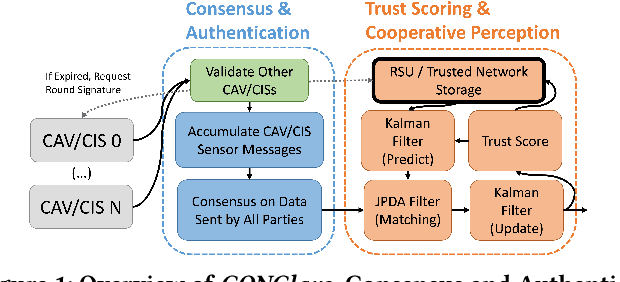
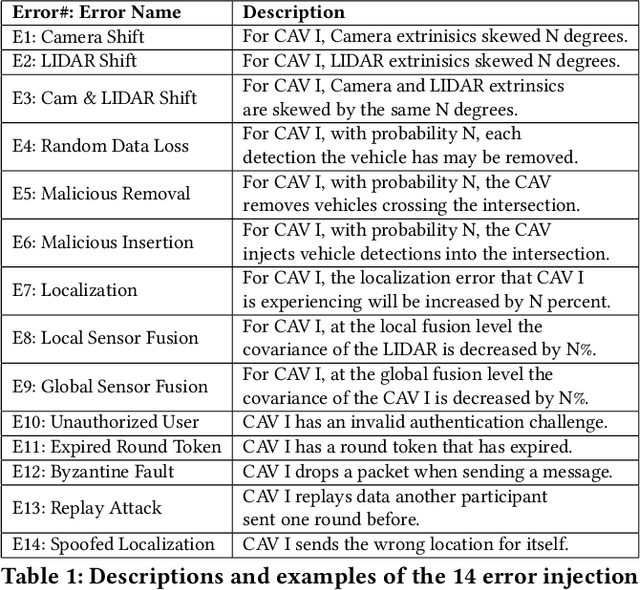

Connected Autonomous Vehicles have great potential to improve automobile safety and traffic flow, especially in cooperative applications where perception data is shared between vehicles. However, this cooperation must be secured from malicious intent and unintentional errors that could cause accidents. Previous works typically address singular security or reliability issues for cooperative driving in specific scenarios rather than the set of errors together. In this paper, we propose CONClave, a tightly coupled authentication, consensus, and trust scoring mechanism that provides comprehensive security and reliability for cooperative perception in autonomous vehicles. CONClave benefits from the pipelined nature of the steps such that faults can be detected significantly faster and with less compute. Overall, CONClave shows huge promise in preventing security flaws, detecting even relatively minor sensing faults, and increasing the robustness and accuracy of cooperative perception in CAVs while adding minimal overhead.
DSP-MLIR: A MLIR Dialect for Digital Signal Processing
Aug 20, 2024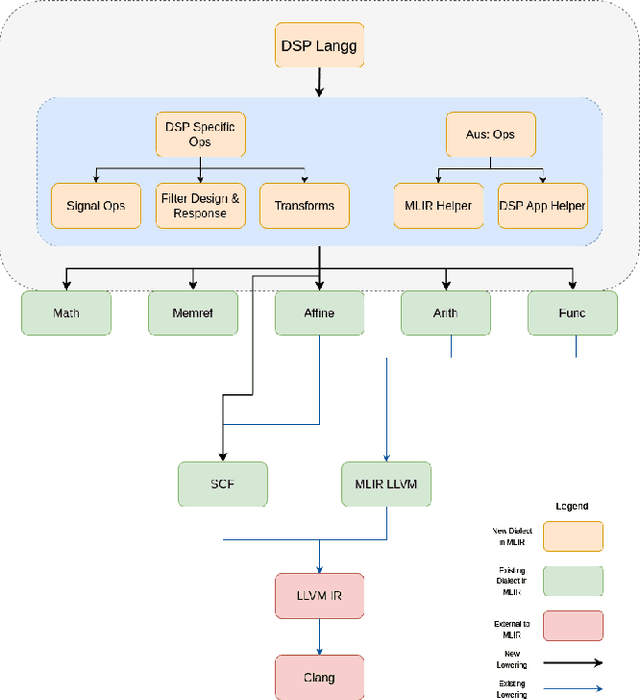
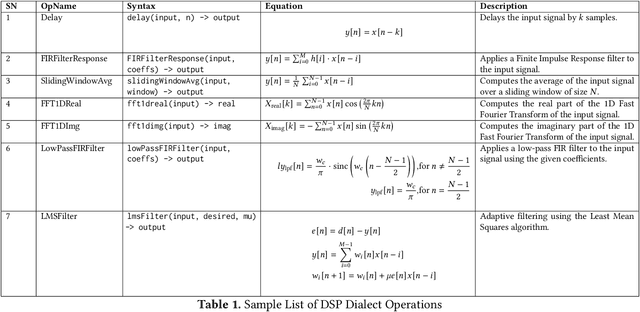
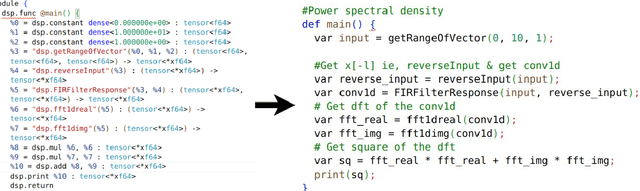
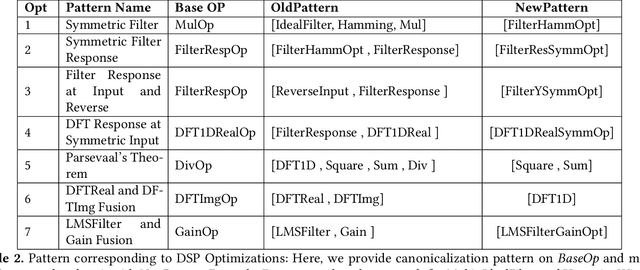
Traditional Digital Signal Processing ( DSP ) compilers work at low level ( C-level / assembly level ) and hence lose much of the optimization opportunities present at high-level ( domain-level ). The emerging multi-level compiler infrastructure MLIR ( Multi-level Intermediate Representation ) allows to specify optimizations at higher level. In this paper, we utilize MLIR framework to introduce a DSP Dialect and perform domain-specific optimizations at dialect -level ( high-level ) and show the usefulness of these optimizations on sample DSP apps. In particular, we develop a compiler for DSP and a DSL (Domain Specific Language) to ease the development of apps. We show the performance improvement in execution time for these sample apps by upto 10x which would have been difficult if the IR were at C/ affine level.
IncidentNet: Traffic Incident Detection, Localization and Severity Estimation with Sparse Sensing
Aug 02, 2024Prior art in traffic incident detection relies on high sensor coverage and is primarily based on decision-tree and random forest models that have limited representation capacity and, as a result, cannot detect incidents with high accuracy. This paper presents IncidentNet - a novel approach for classifying, localizing, and estimating the severity of traffic incidents using deep learning models trained on data captured from sparsely placed sensors in urban environments. Our model works on microscopic traffic data that can be collected using cameras installed at traffic intersections. Due to the unavailability of datasets that provide microscopic traffic details and traffic incident details simultaneously, we also present a methodology to generate a synthetic microscopic traffic dataset that matches given macroscopic traffic data. IncidentNet achieves a traffic incident detection rate of 98%, with false alarm rates of less than 7% in 197 seconds on average in urban environments with cameras on less than 20% of the traffic intersections.
Quantum Polar Metric Learning: Efficient Classically Learned Quantum Embeddings
Dec 04, 2023Deep metric learning has recently shown extremely promising results in the classical data domain, creating well-separated feature spaces. This idea was also adapted to quantum computers via Quantum Metric Learning(QMeL). QMeL consists of a 2 step process with a classical model to compress the data to fit into the limited number of qubits, then train a Parameterized Quantum Circuit(PQC) to create better separation in Hilbert Space. However, on Noisy Intermediate Scale Quantum (NISQ) devices. QMeL solutions result in high circuit width and depth, both of which limit scalability. We propose Quantum Polar Metric Learning (QPMeL) that uses a classical model to learn the parameters of the polar form of a qubit. We then utilize a shallow PQC with $R_y$ and $R_z$ gates to create the state and a trainable layer of $ZZ(\theta)$-gates to learn entanglement. The circuit also computes fidelity via a SWAP Test for our proposed Fidelity Triplet Loss function, used to train both classical and quantum components. When compared to QMeL approaches, QPMeL achieves 3X better multi-class separation, while using only 1/2 the number of gates and depth. We also demonstrate that QPMeL outperforms classical networks with similar configurations, presenting a promising avenue for future research on fully classical models with quantum loss functions.
GiPH: Generalizable Placement Learning for Adaptive Heterogeneous Computing
May 23, 2023Careful placement of a computational application within a target device cluster is critical for achieving low application completion time. The problem is challenging due to its NP-hardness and combinatorial nature. In recent years, learning-based approaches have been proposed to learn a placement policy that can be applied to unseen applications, motivated by the problem of placing a neural network across cloud servers. These approaches, however, generally assume the device cluster is fixed, which is not the case in mobile or edge computing settings, where heterogeneous devices move in and out of range for a particular application. We propose a new learning approach called GiPH, which learns policies that generalize to dynamic device clusters via 1) a novel graph representation gpNet that efficiently encodes the information needed for choosing a good placement, and 2) a scalable graph neural network (GNN) that learns a summary of the gpNet information. GiPH turns the placement problem into that of finding a sequence of placement improvements, learning a policy for selecting this sequence that scales to problems of arbitrary size. We evaluate GiPH with a wide range of task graphs and device clusters and show that our learned policy rapidly find good placements for new problem instances. GiPH finds placements with up to 30.5% lower completion times, searching up to 3X faster than other search-based placement policies.
Accurate Cooperative Sensor Fusion by Parameterized Covariance Generation for Sensing and Localization Pipelines in CAVs
Sep 07, 2022
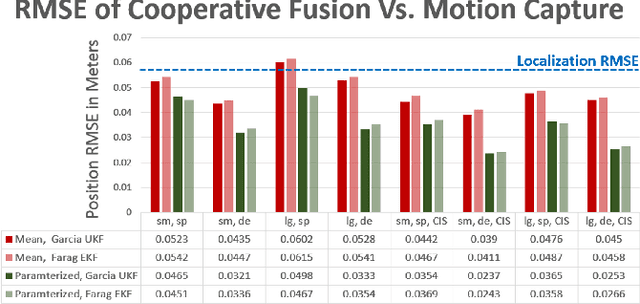
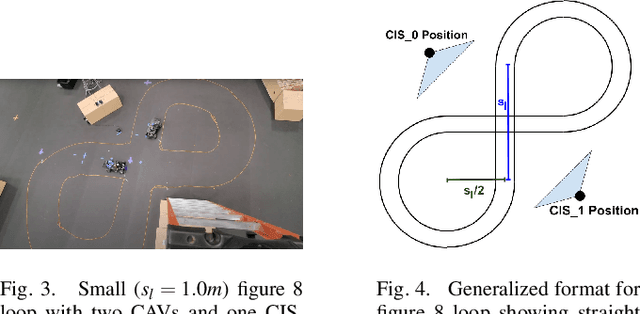
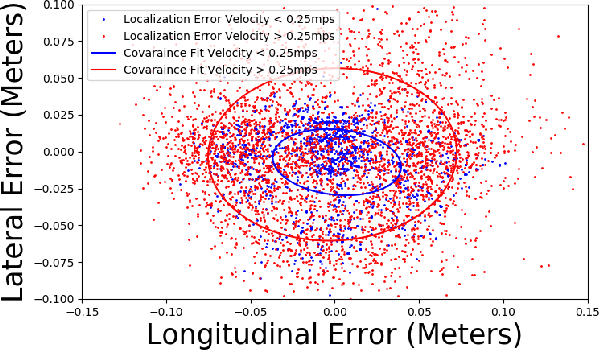
A major challenge in cooperative sensing is to weight the measurements taken from the various sources to get an accurate result. Ideally, the weights should be inversely proportional to the error in the sensing information. However, previous cooperative sensor fusion approaches for autonomous vehicles use a fixed error model, in which the covariance of a sensor and its recognizer pipeline is just the mean of the measured covariance for all sensing scenarios. The approach proposed in this paper estimates error using key predictor terms that have high correlation with sensing and localization accuracy for accurate covariance estimation of each sensor observation. We adopt a tiered fusion model consisting of local and global sensor fusion steps. At the local fusion level, we add in a covariance generation stage using the error model for each sensor and the measured distance to generate the expected covariance matrix for each observation. At the global sensor fusion stage we add an additional stage to generate the localization covariance matrix from the key predictor term velocity and combines that with the covariance generated from the local fusion for accurate cooperative sensing. To showcase our method, we built a set of 1/10 scale model autonomous vehicles with scale accurate sensing capabilities and classified the error characteristics against a motion capture system. Results show an average and max improvement in RMSE when detecting vehicle positions of 1.42x and 1.78x respectively in a four-vehicle cooperative fusion scenario when using our error model versus a typical fixed error model.
Special Session: Towards an Agile Design Methodology for Efficient, Reliable, and Secure ML Systems
Apr 18, 2022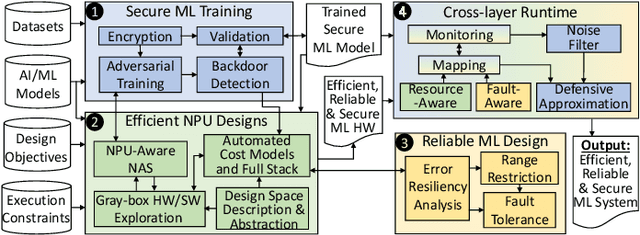
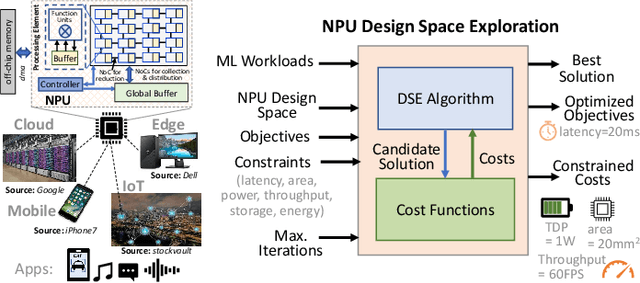
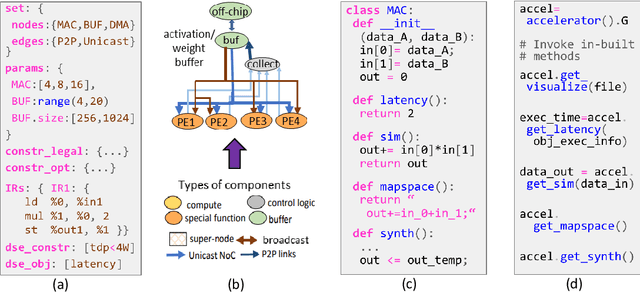
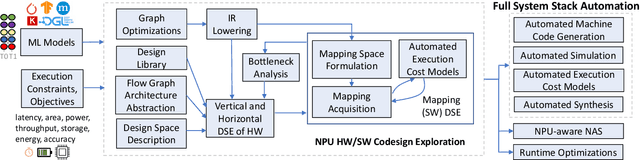
The real-world use cases of Machine Learning (ML) have exploded over the past few years. However, the current computing infrastructure is insufficient to support all real-world applications and scenarios. Apart from high efficiency requirements, modern ML systems are expected to be highly reliable against hardware failures as well as secure against adversarial and IP stealing attacks. Privacy concerns are also becoming a first-order issue. This article summarizes the main challenges in agile development of efficient, reliable and secure ML systems, and then presents an outline of an agile design methodology to generate efficient, reliable and secure ML systems based on user-defined constraints and objectives.
Hardware Acceleration of Sparse and Irregular Tensor Computations of ML Models: A Survey and Insights
Jul 02, 2020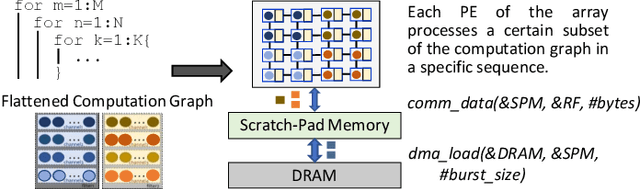


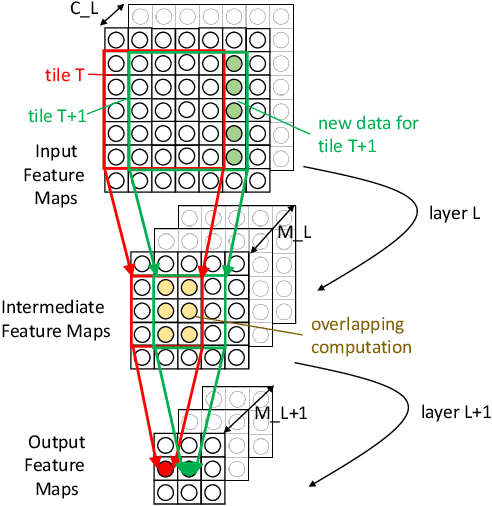
Machine learning (ML) models are widely used in many domains including media processing and generation, computer vision, medical diagnosis, embedded systems, high-performance and scientific computing, and recommendation systems. For efficiently processing these computational- and memory-intensive applications, tensors of these over-parameterized models are compressed by leveraging sparsity, size reduction, and quantization of tensors. Unstructured sparsity and tensors with varying dimensions yield irregular-shaped computation, communication, and memory access patterns; processing them on hardware accelerators in a conventional manner does not inherently leverage acceleration opportunities. This paper provides a comprehensive survey on how to efficiently execute sparse and irregular tensor computations of ML models on hardware accelerators. In particular, it discusses additional enhancement modules in architecture design and software support; categorizes different hardware designs and acceleration techniques and analyzes them in terms of hardware and execution costs; highlights further opportunities in terms of hardware/software/algorithm co-design optimizations and joint optimizations among described hardware and software enhancement modules. The takeaways from this paper include: understanding the key challenges in accelerating sparse, irregular-shaped, and quantized tensors; understanding enhancements in acceleration systems for supporting their efficient computations; analyzing trade-offs in opting for a specific type of design enhancement; understanding how to map and compile models with sparse tensors on the accelerators; understanding recent design trends for efficient accelerations and further opportunities.
Optimizing the Union of Intersections LASSO ($UoI_{LASSO}$) and Vector Autoregressive ($UoI_{VAR}$) Algorithms for Improved Statistical Estimation at Scale
Aug 21, 2018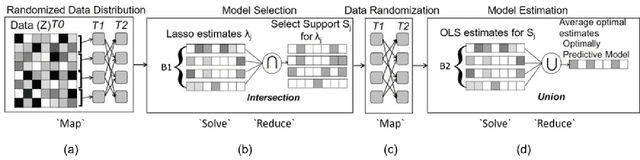
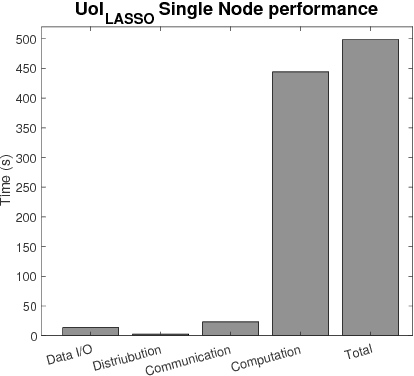
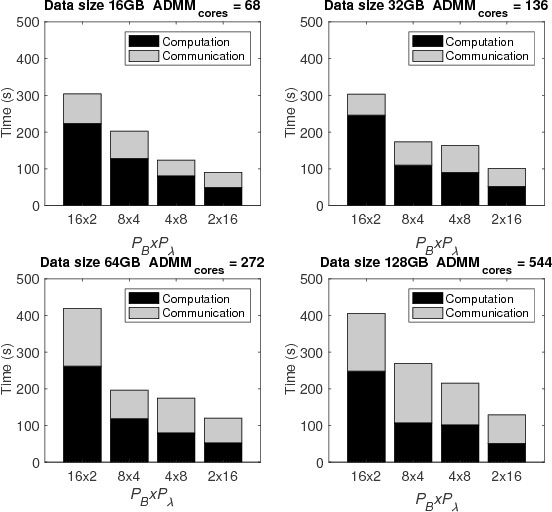
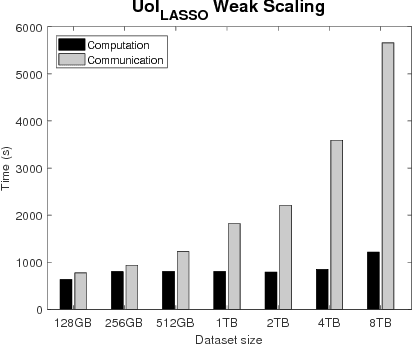
The analysis of scientific data of increasing size and complexity requires statistical machine learning methods that are both interpretable and predictive. Union of Intersections (UoI), a recently developed framework, is a two-step approach that separates model selection and model estimation. A linear regression algorithm based on UoI, $UoI_{LASSO}$, simultaneously achieves low false positives and low false negative feature selection as well as low bias and low variance estimates. Together, these qualities make the results both predictive and interpretable. In this paper, we optimize the $UoI_{LASSO}$ algorithm for single-node execution on NERSC's Cori Knights Landing, a Xeon Phi based supercomputer. We then scale $UoI_{LASSO}$ to execute on cores ranging from 68-278,528 cores on a range of dataset sizes demonstrating the weak and strong scaling of the implementation. We also implement a variant of $UoI_{LASSO}$, $UoI_{VAR}$ for vector autoregressive models, to analyze high dimensional time-series data. We perform single node optimization and multi-node scaling experiments for $UoI_{VAR}$ to demonstrate the effectiveness of the algorithm for weak and strong scaling. Our implementations enable to use estimate the largest VAR model (1000 nodes) we are aware of, and apply it to large neurophysiology data 192 nodes).