 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBypassing Prompt Injection Detectors through Evasive Injections
Jan 31, 2026Large language models (LLMs) are increasingly used in interactive and retrieval-augmented systems, but they remain vulnerable to task drift; deviations from a user's intended instruction due to injected secondary prompts. Recent work has shown that linear probes trained on activation deltas of LLMs' hidden layers can effectively detect such drift. In this paper, we evaluate the robustness of these detectors against adversarially optimised suffixes. We generate universal suffixes that cause poisoned inputs to evade detection across multiple probes simultaneously. Our experiments on Phi-3 3.8B and Llama-3 8B show that a single suffix can achieve high attack success rates; up to 93.91% and 99.63%, respectively, when all probes must be fooled, and nearly perfect success (>90%) under majority vote setting. These results demonstrate that activation delta-based task drift detectors are highly vulnerable to adversarial suffixes, highlighting the need for stronger defences against adaptive attacks. We also propose a defence technique where we generate multiple suffixes and randomly append one of them to the prompts while making forward passes of the LLM and train logistic regression models with these activations. We found this approach to be highly effective against such attacks.
AttenMIA: LLM Membership Inference Attack through Attention Signals
Jan 26, 2026Large Language Models (LLMs) are increasingly deployed to enable or improve a multitude of real-world applications. Given the large size of their training data sets, their tendency to memorize training data raises serious privacy and intellectual property concerns. A key threat is the membership inference attack (MIA), which aims to determine whether a given sample was included in the model's training set. Existing MIAs for LLMs rely primarily on output confidence scores or embedding-based features, but these signals are often brittle, leading to limited attack success. We introduce AttenMIA, a new MIA framework that exploits self-attention patterns inside the transformer model to infer membership. Attention controls the information flow within the transformer, exposing different patterns for memorization that can be used to identify members of the dataset. Our method uses information from attention heads across layers and combines them with perturbation-based divergence metrics to train an effective MIA classifier. Using extensive experiments on open-source models including LLaMA-2, Pythia, and Opt models, we show that attention-based features consistently outperform baselines, particularly under the important low-false-positive metric (e.g., achieving up to 0.996 ROC AUC & 87.9% TPR@1%FPR on the WikiMIA-32 benchmark with Llama2-13b). We show that attention signals generalize across datasets and architectures, and provide a layer- and head-level analysis of where membership leakage is most pronounced. We also show that using AttenMIA to replace other membership inference attacks in a data extraction framework results in training data extraction attacks that outperform the state of the art. Our findings reveal that attention mechanisms, originally introduced to enhance interpretability, can inadvertently amplify privacy risks in LLMs, underscoring the need for new defenses.
Emerging Threats and Countermeasures in Neuromorphic Systems: A Survey
Jan 23, 2026Neuromorphic computing mimics brain-inspired mechanisms through spiking neurons and energy-efficient processing, offering a pathway to efficient in-memory computing (IMC). However, these advancements raise critical security and privacy concerns. As the adoption of bio-inspired architectures and memristive devices increases, so does the urgency to assess the vulnerability of these emerging technologies to hardware and software attacks. Emerging architectures introduce new attack surfaces, particularly due to asynchronous, event-driven processing and stochastic device behavior. The integration of memristors into neuromorphic hardware and software implementations in spiking neural networks offers diverse possibilities for advanced computing architectures, including their role in security-aware applications. This survey systematically analyzes the security landscape of neuromorphic systems, covering attack methodologies, side-channel vulnerabilities, and countermeasures. We focus on both hardware and software concerns relevant to spiking neural networks (SNNs) and hardware primitives, such as Physical Unclonable Functions (PUFs) and True Random Number Generators (TRNGs) for cryptographic and secure computation applications. We approach this analysis from diverse perspectives, from attack methodologies to countermeasure strategies that integrate efficiency and protection in brain-inspired hardware. This review not only maps the current landscape of security threats but provides a foundation for developing secure and trustworthy neuromorphic architectures.
Attention Eclipse: Manipulating Attention to Bypass LLM Safety-Alignment
Feb 21, 2025
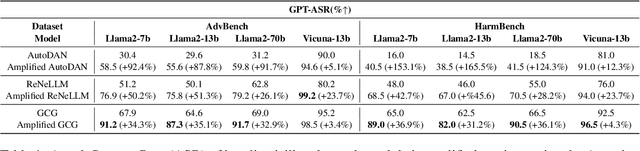


Recent research has shown that carefully crafted jailbreak inputs can induce large language models to produce harmful outputs, despite safety measures such as alignment. It is important to anticipate the range of potential Jailbreak attacks to guide effective defenses and accurate assessment of model safety. In this paper, we present a new approach for generating highly effective Jailbreak attacks that manipulate the attention of the model to selectively strengthen or weaken attention among different parts of the prompt. By harnessing attention loss, we develop more effective jailbreak attacks, that are also transferrable. The attacks amplify the success rate of existing Jailbreak algorithms including GCG, AutoDAN, and ReNeLLM, while lowering their generation cost (for example, the amplified GCG attack achieves 91.2% ASR, vs. 67.9% for the original attack on Llama2-7B/AdvBench, using less than a third of the generation time).
Are Neuromorphic Architectures Inherently Privacy-preserving? An Exploratory Study
Nov 10, 2024
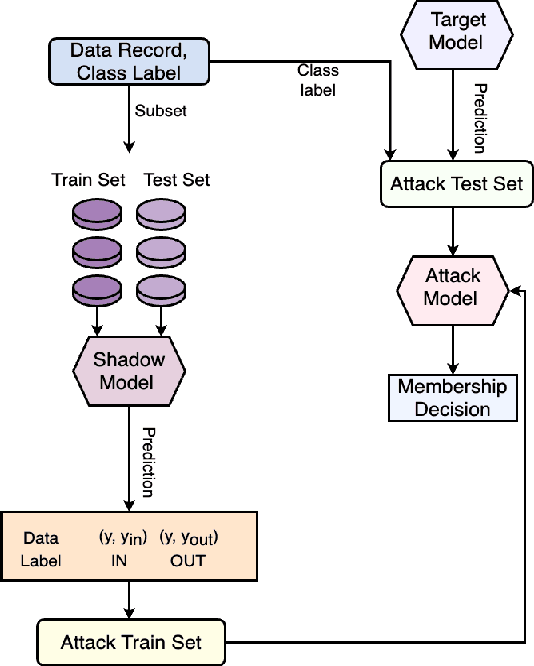
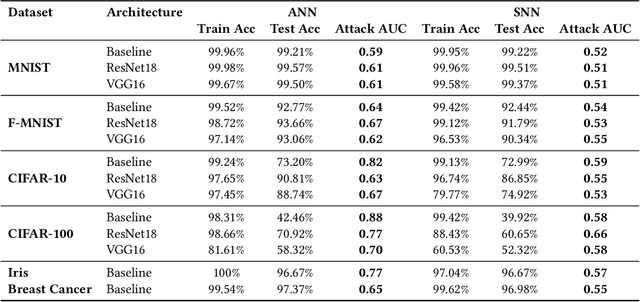
While machine learning (ML) models are becoming mainstream, especially in sensitive application areas, the risk of data leakage has become a growing concern. Attacks like membership inference (MIA) have shown that trained models can reveal sensitive data, jeopardizing confidentiality. While traditional Artificial Neural Networks (ANNs) dominate ML applications, neuromorphic architectures, specifically Spiking Neural Networks (SNNs), are emerging as promising alternatives due to their low power consumption and event-driven processing, akin to biological neurons. Privacy in ANNs is well-studied; however, little work has explored the privacy-preserving properties of SNNs. This paper examines whether SNNs inherently offer better privacy. Using MIAs, we assess the privacy resilience of SNNs versus ANNs across diverse datasets. We analyze the impact of learning algorithms (surrogate gradient and evolutionary), frameworks (snnTorch, TENNLab, LAVA), and parameters on SNN privacy. Our findings show that SNNs consistently outperform ANNs in privacy preservation, with evolutionary algorithms offering additional resilience. For instance, on CIFAR-10, SNNs achieve an AUC of 0.59, significantly lower than ANNs' 0.82, and on CIFAR-100, SNNs maintain an AUC of 0.58 compared to ANNs' 0.88. Additionally, we explore the privacy-utility trade-off with Differentially Private Stochastic Gradient Descent (DPSGD), finding that SNNs sustain less accuracy loss than ANNs under similar privacy constraints.
Model for Peanuts: Hijacking ML Models without Training Access is Possible
Jun 03, 2024



The massive deployment of Machine Learning (ML) models has been accompanied by the emergence of several attacks that threaten their trustworthiness and raise ethical and societal concerns such as invasion of privacy, discrimination risks, and lack of accountability. Model hijacking is one of these attacks, where the adversary aims to hijack a victim model to execute a different task than its original one. Model hijacking can cause accountability and security risks since a hijacked model owner can be framed for having their model offering illegal or unethical services. Prior state-of-the-art works consider model hijacking as a training time attack, whereby an adversary requires access to the ML model training to execute their attack. In this paper, we consider a stronger threat model where the attacker has no access to the training phase of the victim model. Our intuition is that ML models, typically over-parameterized, might (unintentionally) learn more than the intended task for they are trained. We propose a simple approach for model hijacking at inference time named SnatchML to classify unknown input samples using distance measures in the latent space of the victim model to previously known samples associated with the hijacking task classes. SnatchML empirically shows that benign pre-trained models can execute tasks that are semantically related to the initial task. Surprisingly, this can be true even for hijacking tasks unrelated to the original task. We also explore different methods to mitigate this risk. We first propose a novel approach we call meta-unlearning, designed to help the model unlearn a potentially malicious task while training on the original task dataset. We also provide insights on over-parameterization as one possible inherent factor that makes model hijacking easier, and we accordingly propose a compression-based countermeasure against this attack.
Watermarking Neuromorphic Brains: Intellectual Property Protection in Spiking Neural Networks
May 07, 2024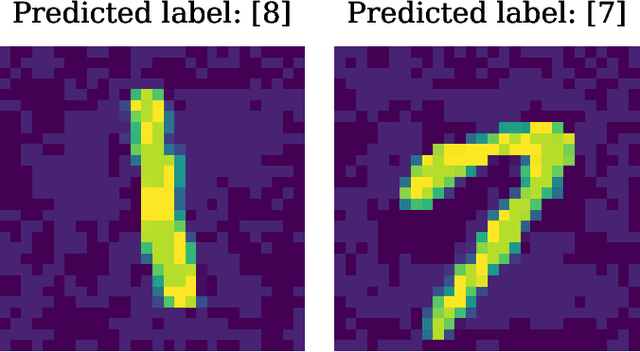
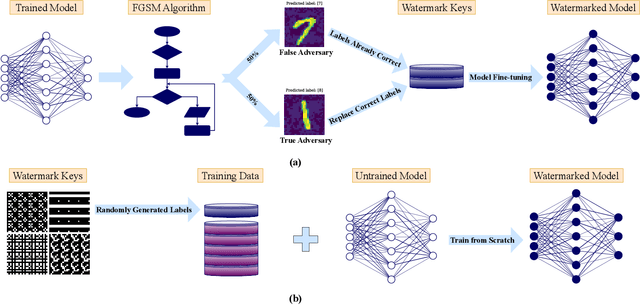
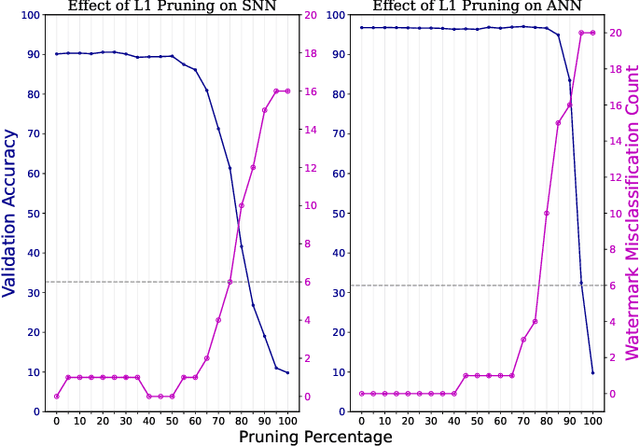
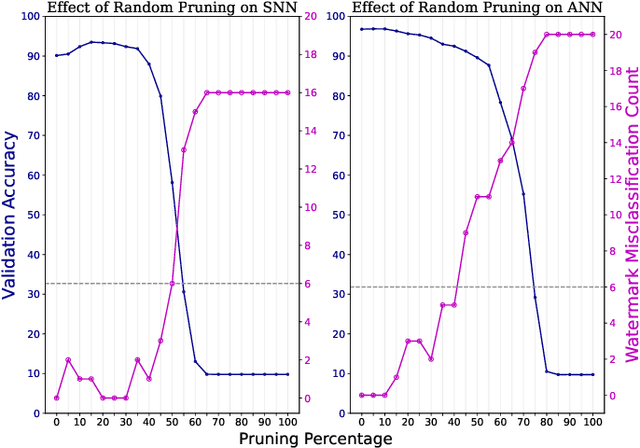
As spiking neural networks (SNNs) gain traction in deploying neuromorphic computing solutions, protecting their intellectual property (IP) has become crucial. Without adequate safeguards, proprietary SNN architectures are at risk of theft, replication, or misuse, which could lead to significant financial losses for the owners. While IP protection techniques have been extensively explored for artificial neural networks (ANNs), their applicability and effectiveness for the unique characteristics of SNNs remain largely unexplored. In this work, we pioneer an investigation into adapting two prominent watermarking approaches, namely, fingerprint-based and backdoor-based mechanisms to secure proprietary SNN architectures. We conduct thorough experiments to evaluate the impact on fidelity, resilience against overwrite threats, and resistance to compression attacks when applying these watermarking techniques to SNNs, drawing comparisons with their ANN counterparts. This study lays the groundwork for developing neuromorphic-aware IP protection strategies tailored to the distinctive dynamics of SNNs.
SSAP: A Shape-Sensitive Adversarial Patch for Comprehensive Disruption of Monocular Depth Estimation in Autonomous Navigation Applications
Mar 18, 2024



Monocular depth estimation (MDE) has advanced significantly, primarily through the integration of convolutional neural networks (CNNs) and more recently, Transformers. However, concerns about their susceptibility to adversarial attacks have emerged, especially in safety-critical domains like autonomous driving and robotic navigation. Existing approaches for assessing CNN-based depth prediction methods have fallen short in inducing comprehensive disruptions to the vision system, often limited to specific local areas. In this paper, we introduce SSAP (Shape-Sensitive Adversarial Patch), a novel approach designed to comprehensively disrupt monocular depth estimation (MDE) in autonomous navigation applications. Our patch is crafted to selectively undermine MDE in two distinct ways: by distorting estimated distances or by creating the illusion of an object disappearing from the system's perspective. Notably, our patch is shape-sensitive, meaning it considers the specific shape and scale of the target object, thereby extending its influence beyond immediate proximity. Furthermore, our patch is trained to effectively address different scales and distances from the camera. Experimental results demonstrate that our approach induces a mean depth estimation error surpassing 0.5, impacting up to 99% of the targeted region for CNN-based MDE models. Additionally, we investigate the vulnerability of Transformer-based MDE models to patch-based attacks, revealing that SSAP yields a significant error of 0.59 and exerts substantial influence over 99% of the target region on these models.
BrainLeaks: On the Privacy-Preserving Properties of Neuromorphic Architectures against Model Inversion Attacks
Feb 01, 2024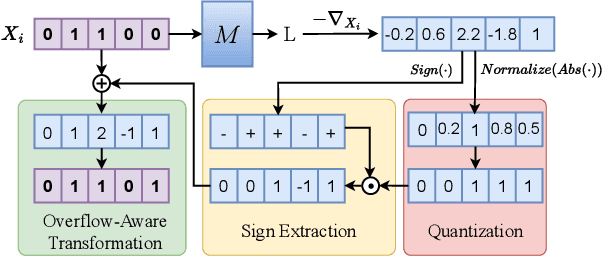

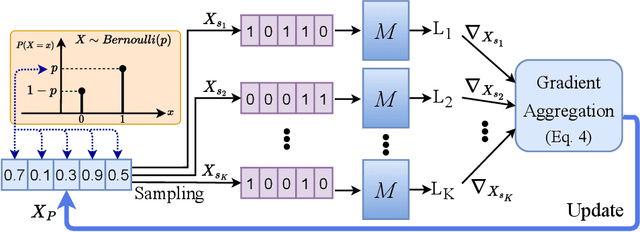

With the mainstream integration of machine learning into security-sensitive domains such as healthcare and finance, concerns about data privacy have intensified. Conventional artificial neural networks (ANNs) have been found vulnerable to several attacks that can leak sensitive data. Particularly, model inversion (MI) attacks enable the reconstruction of data samples that have been used to train the model. Neuromorphic architectures have emerged as a paradigm shift in neural computing, enabling asynchronous and energy-efficient computation. However, little to no existing work has investigated the privacy of neuromorphic architectures against model inversion. Our study is motivated by the intuition that the non-differentiable aspect of spiking neural networks (SNNs) might result in inherent privacy-preserving properties, especially against gradient-based attacks. To investigate this hypothesis, we propose a thorough exploration of SNNs' privacy-preserving capabilities. Specifically, we develop novel inversion attack strategies that are comprehensively designed to target SNNs, offering a comparative analysis with their conventional ANN counterparts. Our experiments, conducted on diverse event-based and static datasets, demonstrate the effectiveness of the proposed attack strategies and therefore questions the assumption of inherent privacy-preserving in neuromorphic architectures.
Evasive Hardware Trojan through Adversarial Power Trace
Jan 04, 2024The globalization of the Integrated Circuit (IC) supply chain, driven by time-to-market and cost considerations, has made ICs vulnerable to hardware Trojans (HTs). Against this threat, a promising approach is to use Machine Learning (ML)-based side-channel analysis, which has the advantage of being a non-intrusive method, along with efficiently detecting HTs under golden chip-free settings. In this paper, we question the trustworthiness of ML-based HT detection via side-channel analysis. We introduce a HT obfuscation (HTO) approach to allow HTs to bypass this detection method. Rather than theoretically misleading the model by simulated adversarial traces, a key aspect of our approach is the design and implementation of adversarial noise as part of the circuitry, alongside the HT. We detail HTO methodologies for ASICs and FPGAs, and evaluate our approach using TrustHub benchmark. Interestingly, we found that HTO can be implemented with only a single transistor for ASIC designs to generate adversarial power traces that can fool the defense with 100% efficiency. We also efficiently implemented our approach on a Spartan 6 Xilinx FPGA using 2 different variants: (i) DSP slices-based, and (ii) ring-oscillator-based design. Additionally, we assess the efficiency of countermeasures like spectral domain analysis, and we show that an adaptive attacker can still design evasive HTOs by constraining the design with a spectral noise budget. In addition, while adversarial training (AT) offers higher protection against evasive HTs, AT models suffer from a considerable utility loss, potentially rendering them unsuitable for such security application. We believe this research represents a significant step in understanding and exploiting ML vulnerabilities in a hardware security context, and we make all resources and designs openly available online: https://dev.d18uu4lqwhbmka.amplifyapp.com