 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Eclipse: Manipulating Attention to Bypass LLM Safety-Alignment
Feb 21, 2025
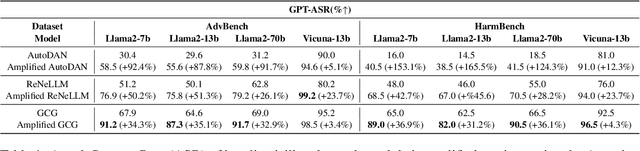


Recent research has shown that carefully crafted jailbreak inputs can induce large language models to produce harmful outputs, despite safety measures such as alignment. It is important to anticipate the range of potential Jailbreak attacks to guide effective defenses and accurate assessment of model safety. In this paper, we present a new approach for generating highly effective Jailbreak attacks that manipulate the attention of the model to selectively strengthen or weaken attention among different parts of the prompt. By harnessing attention loss, we develop more effective jailbreak attacks, that are also transferrable. The attacks amplify the success rate of existing Jailbreak algorithms including GCG, AutoDAN, and ReNeLLM, while lowering their generation cost (for example, the amplified GCG attack achieves 91.2% ASR, vs. 67.9% for the original attack on Llama2-7B/AdvBench, using less than a third of the generation time).
Fool the Hydra: Adversarial Attacks against Multi-view Object Detection Systems
Nov 30, 2023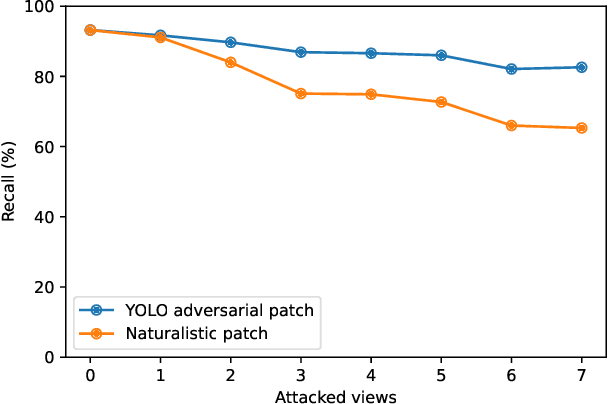
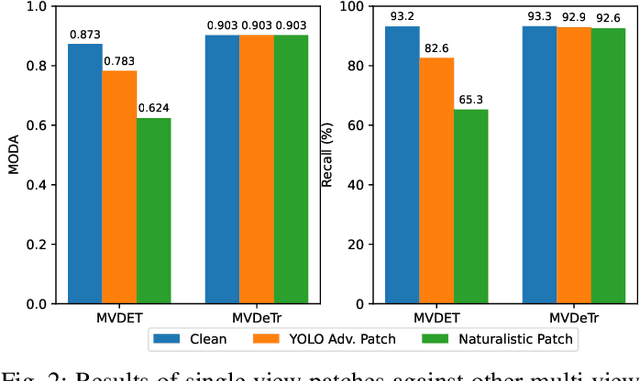
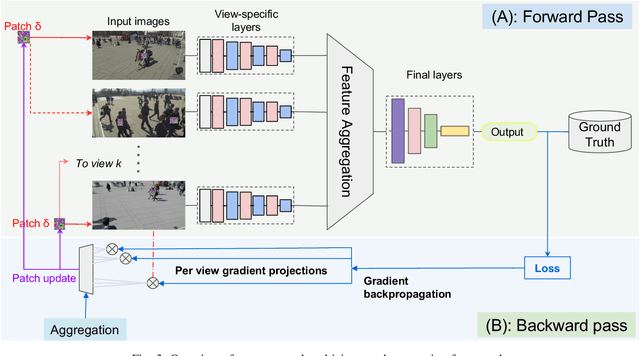
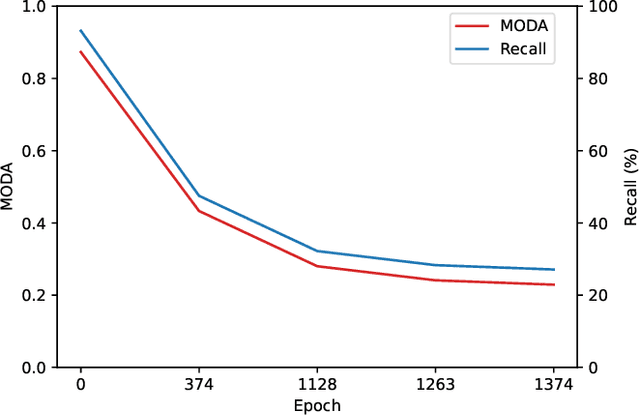
Adversarial patches exemplify the tangible manifestation of the threat posed by adversarial attacks on Machine Learning (ML) models in real-world scenarios. Robustness against these attacks is of the utmost importance when designing computer vision applications, especially for safety-critical domains such as CCTV systems. In most practical situations, monitoring open spaces requires multi-view systems to overcome acquisition challenges such as occlusion handling. Multiview object systems are able to combine data from multiple views, and reach reliable detection results even in difficult environments. Despite its importance in real-world vision applications, the vulnerability of multiview systems to adversarial patches is not sufficiently investigated. In this paper, we raise the following question: Does the increased performance and information sharing across views offer as a by-product robustness to adversarial patches? We first conduct a preliminary analysis showing promising robustness against off-the-shelf adversarial patches, even in an extreme setting where we consider patches applied to all views by all persons in Wildtrack benchmark. However, we challenged this observation by proposing two new attacks: (i) In the first attack, targeting a multiview CNN, we maximize the global loss by proposing gradient projection to the different views and aggregating the obtained local gradients. (ii) In the second attack, we focus on a Transformer-based multiview framework. In addition to the focal loss, we also maximize the transformer-specific loss by dissipating its attention blocks. Our results show a large degradation in the detection performance of victim multiview systems with our first patch attack reaching an attack success rate of 73% , while our second proposed attack reduced the performance of its target detector by 62%
Attention Deficit is Ordered! Fooling Deformable Vision Transformers with Collaborative Adversarial Patches
Nov 21, 2023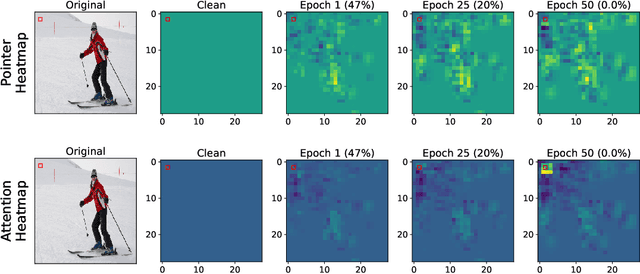



The latest generation of transformer-based vision models have proven to be superior to Convolutional Neural Network (CNN)-based models across several vision tasks, largely attributed to their remarkable prowess in relation modeling. Deformable vision transformers significantly reduce the quadratic complexity of modeling attention by using sparse attention structures, enabling them to be used in larger scale applications such as multi-view vision systems. Recent work demonstrated adversarial attacks against transformers; we show that these attacks do not transfer to deformable transformers due to their sparse attention structure. Specifically, attention in deformable transformers is modeled using pointers to the most relevant other tokens. In this work, we contribute for the first time adversarial attacks that manipulate the attention of deformable transformers, distracting them to focus on irrelevant parts of the image. We also develop new collaborative attacks where a source patch manipulates attention to point to a target patch that adversarially attacks the system. In our experiments, we find that only 1% patched area of the input field can lead to 0% AP. We also show that the attacks provide substantial versatility to support different attacker scenarios because of their ability to redirect attention under the attacker control.
Learn to Compress (LtC): Efficient Learning-based Streaming Video Analytics
Jul 25, 2023



Video analytics are often performed as cloud services in edge settings, mainly to offload computation, and also in situations where the results are not directly consumed at the video sensors. Sending high-quality video data from the edge devices can be expensive both in terms of bandwidth and power use. In order to build a streaming video analytics pipeline that makes efficient use of these resources, it is therefore imperative to reduce the size of the video stream. Traditional video compression algorithms are unaware of the semantics of the video, and can be both inefficient and harmful for the analytics performance. In this paper, we introduce LtC, a collaborative framework between the video source and the analytics server, that efficiently learns to reduce the video streams within an analytics pipeline. Specifically, LtC uses the full-fledged analytics algorithm at the server as a teacher to train a lightweight student neural network, which is then deployed at the video source. The student network is trained to comprehend the semantic significance of various regions within the videos, which is used to differentially preserve the crucial regions in high quality while the remaining regions undergo aggressive compression. Furthermore, LtC also incorporates a novel temporal filtering algorithm based on feature-differencing to omit transmitting frames that do not contribute new information. Overall, LtC is able to use 28-35% less bandwidth and has up to 45% shorter response delay compared to recently published state of the art streaming frameworks while achieving similar analytics performance.
DeepMem: ML Models as storage channels and their applications
Jul 24, 2023



Machine learning (ML) models are overparameterized to support generality and avoid overfitting. Prior works have shown that these additional parameters can be used for both malicious (e.g., hiding a model covertly within a trained model) and beneficial purposes (e.g., watermarking a model). In this paper, we propose a novel information theoretic perspective of the problem; we consider the ML model as a storage channel with a capacity that increases with overparameterization. Specifically, we consider a sender that embeds arbitrary information in the model at training time, which can be extracted by a receiver with a black-box access to the deployed model. We derive an upper bound on the capacity of the channel based on the number of available parameters. We then explore black-box write and read primitives that allow the attacker to: (i) store data in an optimized way within the model by augmenting the training data at the transmitter side, and (ii) to read it by querying the model after it is deployed. We also analyze the detectability of the writing primitive and consider a new version of the problem which takes information storage covertness into account. Specifically, to obtain storage covertness, we introduce a new constraint such that the data augmentation used for the write primitives minimizes the distribution shift with the initial (baseline task) distribution. This constraint introduces a level of "interference" with the initial task, thereby limiting the channel's effective capacity. Therefore, we develop optimizations to improve the capacity in this case, including a novel ML-specific substitution based error correction protocol. We believe that the proposed modeling of the problem offers new tools to better understand and mitigate potential vulnerabilities of ML, especially in the context of increasingly large models.