 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttenMIA: LLM Membership Inference Attack through Attention Signals
Jan 26, 2026Large Language Models (LLMs) are increasingly deployed to enable or improve a multitude of real-world applications. Given the large size of their training data sets, their tendency to memorize training data raises serious privacy and intellectual property concerns. A key threat is the membership inference attack (MIA), which aims to determine whether a given sample was included in the model's training set. Existing MIAs for LLMs rely primarily on output confidence scores or embedding-based features, but these signals are often brittle, leading to limited attack success. We introduce AttenMIA, a new MIA framework that exploits self-attention patterns inside the transformer model to infer membership. Attention controls the information flow within the transformer, exposing different patterns for memorization that can be used to identify members of the dataset. Our method uses information from attention heads across layers and combines them with perturbation-based divergence metrics to train an effective MIA classifier. Using extensive experiments on open-source models including LLaMA-2, Pythia, and Opt models, we show that attention-based features consistently outperform baselines, particularly under the important low-false-positive metric (e.g., achieving up to 0.996 ROC AUC & 87.9% TPR@1%FPR on the WikiMIA-32 benchmark with Llama2-13b). We show that attention signals generalize across datasets and architectures, and provide a layer- and head-level analysis of where membership leakage is most pronounced. We also show that using AttenMIA to replace other membership inference attacks in a data extraction framework results in training data extraction attacks that outperform the state of the art. Our findings reveal that attention mechanisms, originally introduced to enhance interpretability, can inadvertently amplify privacy risks in LLMs, underscoring the need for new defenses.
Attention Eclipse: Manipulating Attention to Bypass LLM Safety-Alignment
Feb 21, 2025
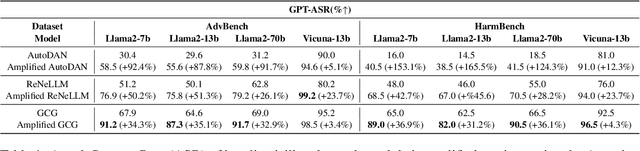


Recent research has shown that carefully crafted jailbreak inputs can induce large language models to produce harmful outputs, despite safety measures such as alignment. It is important to anticipate the range of potential Jailbreak attacks to guide effective defenses and accurate assessment of model safety. In this paper, we present a new approach for generating highly effective Jailbreak attacks that manipulate the attention of the model to selectively strengthen or weaken attention among different parts of the prompt. By harnessing attention loss, we develop more effective jailbreak attacks, that are also transferrable. The attacks amplify the success rate of existing Jailbreak algorithms including GCG, AutoDAN, and ReNeLLM, while lowering their generation cost (for example, the amplified GCG attack achieves 91.2% ASR, vs. 67.9% for the original attack on Llama2-7B/AdvBench, using less than a third of the generation time).
Survey of Vulnerabilities in Large Language Models Revealed by Adversarial Attacks
Oct 16, 2023



Large Language Models (LLMs) are swiftly advancing in architecture and capability, and as they integrate more deeply into complex systems, the urgency to scrutinize their security properties grows. This paper surveys research in the emerging interdisciplinary field of adversarial attacks on LLMs, a subfield of trustworthy ML, combining the perspectives of Natural Language Processing and Security. Prior work has shown that even safety-aligned LLMs (via instruction tuning and reinforcement learning through human feedback) can be susceptible to adversarial attacks, which exploit weaknesses and mislead AI systems, as evidenced by the prevalence of `jailbreak' attacks on models like ChatGPT and Bard. In this survey, we first provide an overview of large language models, describe their safety alignment, and categorize existing research based on various learning structures: textual-only attacks, multi-modal attacks, and additional attack methods specifically targeting complex systems, such as federated learning or multi-agent systems. We also offer comprehensive remarks on works that focus on the fundamental sources of vulnerabilities and potential defenses. To make this field more accessible to newcomers, we present a systematic review of existing works, a structured typology of adversarial attack concepts, and additional resources, including slides for presentations on related topics at the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24).
DeepMem: ML Models as storage channels and their applications
Jul 24, 2023



Machine learning (ML) models are overparameterized to support generality and avoid overfitting. Prior works have shown that these additional parameters can be used for both malicious (e.g., hiding a model covertly within a trained model) and beneficial purposes (e.g., watermarking a model). In this paper, we propose a novel information theoretic perspective of the problem; we consider the ML model as a storage channel with a capacity that increases with overparameterization. Specifically, we consider a sender that embeds arbitrary information in the model at training time, which can be extracted by a receiver with a black-box access to the deployed model. We derive an upper bound on the capacity of the channel based on the number of available parameters. We then explore black-box write and read primitives that allow the attacker to: (i) store data in an optimized way within the model by augmenting the training data at the transmitter side, and (ii) to read it by querying the model after it is deployed. We also analyze the detectability of the writing primitive and consider a new version of the problem which takes information storage covertness into account. Specifically, to obtain storage covertness, we introduce a new constraint such that the data augmentation used for the write primitives minimizes the distribution shift with the initial (baseline task) distribution. This constraint introduces a level of "interference" with the initial task, thereby limiting the channel's effective capacity. Therefore, we develop optimizations to improve the capacity in this case, including a novel ML-specific substitution based error correction protocol. We believe that the proposed modeling of the problem offers new tools to better understand and mitigate potential vulnerabilities of ML, especially in the context of increasingly large models.