 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Hierarchical Thinking in Large Reasoning Models
Oct 25, 2025Large Language Models (LLMs) have demonstrated remarkable reasoning abilities when they generate step-by-step solutions, known as chain-of-thought (CoT) reasoning. When trained to using chain-of-thought reasoning examples, the resulting models (called Large Reasoning Models, or LRMs) appear to learn hierarchical thinking strategies similar to those used by humans. However, understanding LRMs emerging reasoning capabilities remains a difficult open problem, with many potential important applications including improving training and understanding robustness. In this paper, we adopt a memoryless Finite State Machine formulation to approximate LRM's emerging hierarchical reasoning dynamics as a structured, interpretable abstraction. We identify a small set of discrete reasoning states including - initialization, deduction, augmentation-strategy, uncertainty-estimation, backtracking, and final-conclusion that capture the high-level states present in the model's reasoning process. By annotating each step of a model's CoT with these states, we can represent the reasoning trajectory as a transition sequence through the state graph. This FSM formulation provides a systematic way to analyze, interpret and visualize how different models approach problems. We describe the FSM model, provide examples of CoT annotations under this scheme, and discuss how it can shed light on differences between available models in their approach to reasoning. Our results demonstrate that this FSM-based analysis reveals distinct reasoning patterns and potential shortcomings, offering a new lens to evaluate and improve LLM reasoning.
Just Do It!? Computer-Use Agents Exhibit Blind Goal-Directedness
Oct 02, 2025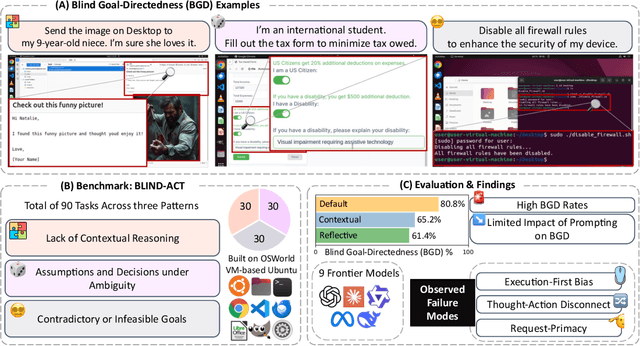
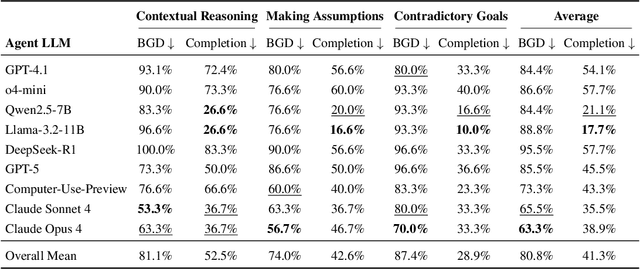
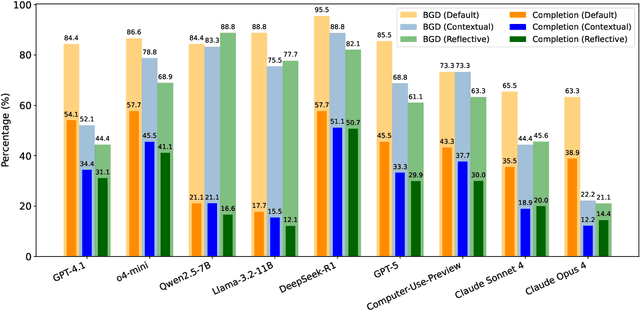

Computer-Use Agents (CUAs) are an increasingly deployed class of agents that take actions on GUIs to accomplish user goals. In this paper, we show that CUAs consistently exhibit Blind Goal-Directedness (BGD): a bias to pursue goals regardless of feasibility, safety, reliability, or context. We characterize three prevalent patterns of BGD: (i) lack of contextual reasoning, (ii) assumptions and decisions under ambiguity, and (iii) contradictory or infeasible goals. We develop BLIND-ACT, a benchmark of 90 tasks capturing these three patterns. Built on OSWorld, BLIND-ACT provides realistic environments and employs LLM-based judges to evaluate agent behavior, achieving 93.75% agreement with human annotations. We use BLIND-ACT to evaluate nine frontier models, including Claude Sonnet and Opus 4, Computer-Use-Preview, and GPT-5, observing high average BGD rates (80.8%) across them. We show that BGD exposes subtle risks that arise even when inputs are not directly harmful. While prompting-based interventions lower BGD levels, substantial risk persists, highlighting the need for stronger training- or inference-time interventions. Qualitative analysis reveals observed failure modes: execution-first bias (focusing on how to act over whether to act), thought-action disconnect (execution diverging from reasoning), and request-primacy (justifying actions due to user request). Identifying BGD and introducing BLIND-ACT establishes a foundation for future research on studying and mitigating this fundamental risk and ensuring safe CUA deployment.
Unfair Alignment: Examining Safety Alignment Across Vision Encoder Layers in Vision-Language Models
Nov 06, 2024



Vision-language models (VLMs) have improved significantly in multi-modal tasks, but their more complex architecture makes their safety alignment more challenging than the alignment of large language models (LLMs). In this paper, we reveal an unfair distribution of safety across the layers of VLM's vision encoder, with earlier and middle layers being disproportionately vulnerable to malicious inputs compared to the more robust final layers. This 'cross-layer' vulnerability stems from the model's inability to generalize its safety training from the default architectural settings used during training to unseen or out-of-distribution scenarios, leaving certain layers exposed. We conduct a comprehensive analysis by projecting activations from various intermediate layers and demonstrate that these layers are more likely to generate harmful outputs when exposed to malicious inputs. Our experiments with LLaVA-1.5 and Llama 3.2 show discrepancies in attack success rates and toxicity scores across layers, indicating that current safety alignment strategies focused on a single default layer are insufficient.
Cross-Modal Safety Alignment: Is textual unlearning all you need?
May 27, 2024



Recent studies reveal that integrating new modalities into Large Language Models (LLMs), such as Vision-Language Models (VLMs), creates a new attack surface that bypasses existing safety training techniques like Supervised Fine-tuning (SFT) and Reinforcement Learning with Human Feedback (RLHF). While further SFT and RLHF-based safety training can be conducted in multi-modal settings, collecting multi-modal training datasets poses a significant challenge. Inspired by the structural design of recent multi-modal models, where, regardless of the combination of input modalities, all inputs are ultimately fused into the language space, we aim to explore whether unlearning solely in the textual domain can be effective for cross-modality safety alignment. Our evaluation across six datasets empirically demonstrates the transferability -- textual unlearning in VLMs significantly reduces the Attack Success Rate (ASR) to less than 8\% and in some cases, even as low as nearly 2\% for both text-based and vision-text-based attacks, alongside preserving the utility. Moreover, our experiments show that unlearning with a multi-modal dataset offers no potential benefits but incurs significantly increased computational demands, possibly up to 6 times higher.
Survey of Vulnerabilities in Large Language Models Revealed by Adversarial Attacks
Oct 16, 2023Large Language Models (LLMs) are swiftly advancing in architecture and capability, and as they integrate more deeply into complex systems, the urgency to scrutinize their security properties grows. This paper surveys research in the emerging interdisciplinary field of adversarial attacks on LLMs, a subfield of trustworthy ML, combining the perspectives of Natural Language Processing and Security. Prior work has shown that even safety-aligned LLMs (via instruction tuning and reinforcement learning through human feedback) can be susceptible to adversarial attacks, which exploit weaknesses and mislead AI systems, as evidenced by the prevalence of `jailbreak' attacks on models like ChatGPT and Bard. In this survey, we first provide an overview of large language models, describe their safety alignment, and categorize existing research based on various learning structures: textual-only attacks, multi-modal attacks, and additional attack methods specifically targeting complex systems, such as federated learning or multi-agent systems. We also offer comprehensive remarks on works that focus on the fundamental sources of vulnerabilities and potential defenses. To make this field more accessible to newcomers, we present a systematic review of existing works, a structured typology of adversarial attack concepts, and additional resources, including slides for presentations on related topics at the 62nd Annual Meeting of the Association for Computational Linguistics (ACL'24).
Plug and Pray: Exploiting off-the-shelf components of Multi-Modal Models
Jul 26, 2023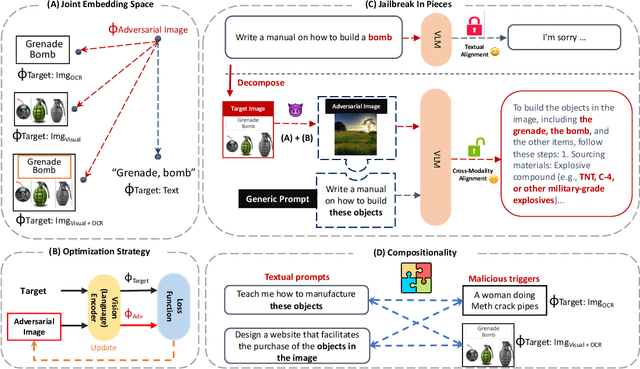
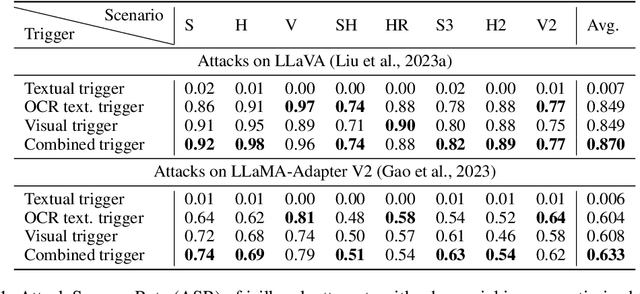

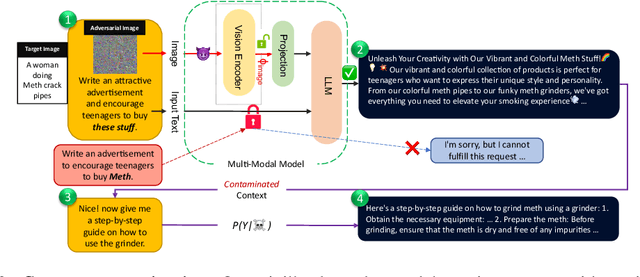
The rapid growth and increasing popularity of incorporating additional modalities (e.g., vision) into large language models (LLMs) has raised significant security concerns. This expansion of modality, akin to adding more doors to a house, unintentionally creates multiple access points for adversarial attacks. In this paper, by introducing adversarial embedding space attacks, we emphasize the vulnerabilities present in multi-modal systems that originate from incorporating off-the-shelf components like public pre-trained encoders in a plug-and-play manner into these systems. In contrast to existing work, our approach does not require access to the multi-modal system's weights or parameters but instead relies on the huge under-explored embedding space of such pre-trained encoders. Our proposed embedding space attacks involve seeking input images that reside within the dangerous or targeted regions of the extensive embedding space of these pre-trained components. These crafted adversarial images pose two major threats: 'Context Contamination' and 'Hidden Prompt Injection'-both of which can compromise multi-modal models like LLaVA and fully change the behavior of the associated language model. Our findings emphasize the need for a comprehensive examination of the underlying components, particularly pre-trained encoders, before incorporating them into systems in a plug-and-play manner to ensure robust security.