 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArcee: Differentiable Recurrent State Chain for Generative Vision Modeling with Mamba SSMs
Nov 17, 2025State-space models (SSMs), Mamba in particular, are increasingly adopted for long-context sequence modeling, providing linear-time aggregation via an input-dependent, causal selective-scan operation. Along this line, recent "Mamba-for-vision" variants largely explore multiple scan orders to relax strict causality for non-sequential signals (e.g., images). Rather than preserving cross-block memory, the conventional formulation of the selective-scan operation in Mamba reinitializes each block's state-space dynamics from zero, discarding the terminal state-space representation (SSR) from the previous block. Arcee, a cross-block recurrent state chain, reuses each block's terminal state-space representation as the initial condition for the next block. Handoff across blocks is constructed as a differentiable boundary map whose Jacobian enables end-to-end gradient flow across terminal boundaries. Key to practicality, Arcee is compatible with all prior "vision-mamba" variants, parameter-free, and incurs constant, negligible cost. As a modeling perspective, we view terminal SSR as a mild directional prior induced by a causal pass over the input, rather than an estimator of the non-sequential signal itself. To quantify the impact, for unconditional generation on CelebA-HQ (256$\times$256) with Flow Matching, Arcee reduces FID$\downarrow$ from $82.81$ to $15.33$ ($5.4\times$ lower) on a single scan-order Zigzag Mamba baseline. Efficient CUDA kernels and training code will be released to support rigorous and reproducible research.
Unfair Alignment: Examining Safety Alignment Across Vision Encoder Layers in Vision-Language Models
Nov 06, 2024



Vision-language models (VLMs) have improved significantly in multi-modal tasks, but their more complex architecture makes their safety alignment more challenging than the alignment of large language models (LLMs). In this paper, we reveal an unfair distribution of safety across the layers of VLM's vision encoder, with earlier and middle layers being disproportionately vulnerable to malicious inputs compared to the more robust final layers. This 'cross-layer' vulnerability stems from the model's inability to generalize its safety training from the default architectural settings used during training to unseen or out-of-distribution scenarios, leaving certain layers exposed. We conduct a comprehensive analysis by projecting activations from various intermediate layers and demonstrate that these layers are more likely to generate harmful outputs when exposed to malicious inputs. Our experiments with LLaVA-1.5 and Llama 3.2 show discrepancies in attack success rates and toxicity scores across layers, indicating that current safety alignment strategies focused on a single default layer are insufficient.
Multi-modal Pose Diffuser: A Multimodal Generative Conditional Pose Prior
Oct 18, 2024The Skinned Multi-Person Linear (SMPL) model plays a crucial role in 3D human pose estimation, providing a streamlined yet effective representation of the human body. However, ensuring the validity of SMPL configurations during tasks such as human mesh regression remains a significant challenge , highlighting the necessity for a robust human pose prior capable of discerning realistic human poses. To address this, we introduce MOPED: \underline{M}ulti-m\underline{O}dal \underline{P}os\underline{E} \underline{D}iffuser. MOPED is the first method to leverage a novel multi-modal conditional diffusion model as a prior for SMPL pose parameters. Our method offers powerful unconditional pose generation with the ability to condition on multi-modal inputs such as images and text. This capability enhances the applicability of our approach by incorporating additional context often overlooked in traditional pose priors. Extensive experiments across three distinct tasks-pose estimation, pose denoising, and pose completion-demonstrate that our multi-modal diffusion model-based prior significantly outperforms existing methods. These results indicate that our model captures a broader spectrum of plausible human poses.
Improving Domain Adaptation Through Class Aware Frequency Transformation
Jul 28, 2024In this work, we explore the usage of the Frequency Transformation for reducing the domain shift between the source and target domain (e.g., synthetic image and real image respectively) towards solving the Domain Adaptation task. Most of the Unsupervised Domain Adaptation (UDA) algorithms focus on reducing the global domain shift between labelled source and unlabelled target domains by matching the marginal distributions under a small domain gap assumption. UDA performance degrades for the cases where the domain gap between source and target distribution is large. In order to bring the source and the target domains closer, we propose a novel approach based on traditional image processing technique Class Aware Frequency Transformation (CAFT) that utilizes pseudo label based class consistent low-frequency swapping for improving the overall performance of the existing UDA algorithms. The proposed approach, when compared with the state-of-the-art deep learning based methods, is computationally more efficient and can easily be plugged into any existing UDA algorithm to improve its performance. Additionally, we introduce a novel approach based on absolute difference of top-2 class prediction probabilities (ADT2P) for filtering target pseudo labels into clean and noisy sets. Samples with clean pseudo labels can be used to improve the performance of unsupervised learning algorithms. We name the overall framework as CAFT++. We evaluate the same on the top of different UDA algorithms across many public domain adaptation datasets. Our extensive experiments indicate that CAFT++ is able to achieve significant performance gains across all the popular benchmarks.
POSTURE: Pose Guided Unsupervised Domain Adaptation for Human Body Part Segmentation
Jul 04, 2024



Existing algorithms for human body part segmentation have shown promising results on challenging datasets, primarily relying on end-to-end supervision. However, these algorithms exhibit severe performance drops in the face of domain shifts, leading to inaccurate segmentation masks. To tackle this issue, we introduce POSTURE: \underline{Po}se Guided Un\underline{s}upervised Domain Adap\underline{t}ation for H\underline{u}man Body Pa\underline{r}t S\underline{e}gmentation - an innovative pseudo-labelling approach designed to improve segmentation performance on the unlabeled target data. Distinct from conventional domain adaptive methods for general semantic segmentation, POSTURE stands out by considering the underlying structure of the human body and uses anatomical guidance from pose keypoints to drive the adaptation process. This strong inductive prior translates to impressive performance improvements, averaging 8\% over existing state-of-the-art domain adaptive semantic segmentation methods across three benchmark datasets. Furthermore, the inherent flexibility of our proposed approach facilitates seamless extension to source-free settings (SF-POSTURE), effectively mitigating potential privacy and computational concerns, with negligible drop in performance.
TEMP3D: Temporally Continuous 3D Human Pose Estimation Under Occlusions
Dec 24, 2023
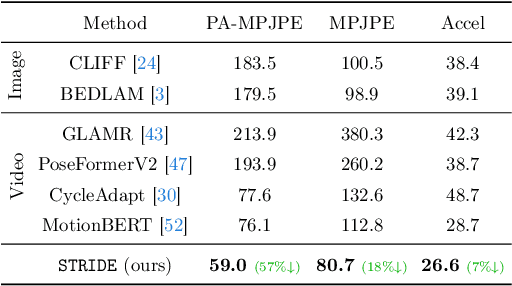
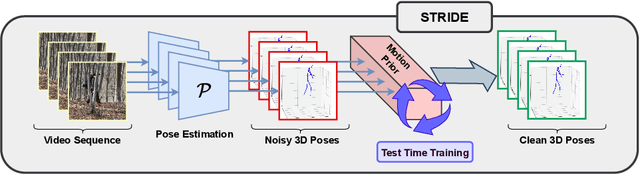

Existing 3D human pose estimation methods perform remarkably well in both monocular and multi-view settings. However, their efficacy diminishes significantly in the presence of heavy occlusions, which limits their practical utility. For video sequences, temporal continuity can help infer accurate poses, especially in heavily occluded frames. In this paper, we aim to leverage this potential of temporal continuity through human motion priors, coupled with large-scale pre-training on 3D poses and self-supervised learning, to enhance 3D pose estimation in a given video sequence. This leads to a temporally continuous 3D pose estimate on unlabelled in-the-wild videos, which may contain occlusions, while exclusively relying on pre-trained 3D pose models. We propose an unsupervised method named TEMP3D that aligns a motion prior model on a given in-the-wild video using existing SOTA single image-based 3D pose estimation methods to give temporally continuous output under occlusions. To evaluate our method, we test it on the Occluded Human3.6M dataset, our custom-built dataset which contains significantly large (up to 100%) human body occlusions incorporated into the Human3.6M dataset. We achieve SOTA results on Occluded Human3.6M and the OcMotion dataset while maintaining competitive performance on non-occluded data. URL: https://sites.google.com/ucr.edu/temp3d
Towards Granularity-adjusted Pixel-level Semantic Annotation
Dec 05, 2023



Recent advancements in computer vision predominantly rely on learning-based systems, leveraging annotations as the driving force to develop specialized models. However, annotating pixel-level information, particularly in semantic segmentation, presents a challenging and labor-intensive task, prompting the need for autonomous processes. In this work, we propose GranSAM which distinguishes itself by providing semantic segmentation at the user-defined granularity level on unlabeled data without the need for any manual supervision, offering a unique contribution in the realm of semantic mask annotation method. Specifically, we propose an approach to enable the Segment Anything Model (SAM) with semantic recognition capability to generate pixel-level annotations for images without any manual supervision. For this, we accumulate semantic information from synthetic images generated by the Stable Diffusion model or web crawled images and employ this data to learn a mapping function between SAM mask embeddings and object class labels. As a result, SAM, enabled with granularity-adjusted mask recognition, can be used for pixel-level semantic annotation purposes. We conducted experiments on the PASCAL VOC 2012 and COCO-80 datasets and observed a +17.95% and +5.17% increase in mIoU, respectively, compared to existing state-of-the-art methods when evaluated under our problem setting.
POISE: Pose Guided Human Silhouette Extraction under Occlusions
Nov 09, 2023



Human silhouette extraction is a fundamental task in computer vision with applications in various downstream tasks. However, occlusions pose a significant challenge, leading to incomplete and distorted silhouettes. To address this challenge, we introduce POISE: Pose Guided Human Silhouette Extraction under Occlusions, a novel self-supervised fusion framework that enhances accuracy and robustness in human silhouette prediction. By combining initial silhouette estimates from a segmentation model with human joint predictions from a 2D pose estimation model, POISE leverages the complementary strengths of both approaches, effectively integrating precise body shape information and spatial information to tackle occlusions. Furthermore, the self-supervised nature of \POISE eliminates the need for costly annotations, making it scalable and practical. Extensive experimental results demonstrate its superiority in improving silhouette extraction under occlusions, with promising results in downstream tasks such as gait recognition. The code for our method is available https://github.com/take2rohit/poise.
Prior-guided Source-free Domain Adaptation for Human Pose Estimation
Aug 26, 2023



Domain adaptation methods for 2D human pose estimation typically require continuous access to the source data during adaptation, which can be challenging due to privacy, memory, or computational constraints. To address this limitation, we focus on the task of source-free domain adaptation for pose estimation, where a source model must adapt to a new target domain using only unlabeled target data. Although recent advances have introduced source-free methods for classification tasks, extending them to the regression task of pose estimation is non-trivial. In this paper, we present Prior-guided Self-training (POST), a pseudo-labeling approach that builds on the popular Mean Teacher framework to compensate for the distribution shift. POST leverages prediction-level and feature-level consistency between a student and teacher model against certain image transformations. In the absence of source data, POST utilizes a human pose prior that regularizes the adaptation process by directing the model to generate more accurate and anatomically plausible pose pseudo-labels. Despite being simple and intuitive, our framework can deliver significant performance gains compared to applying the source model directly to the target data, as demonstrated in our extensive experiments and ablation studies. In fact, our approach achieves comparable performance to recent state-of-the-art methods that use source data for adaptation.
Open-Set Multi-Source Multi-Target Domain Adaptation
Feb 03, 2023
Single-Source Single-Target Domain Adaptation (1S1T) aims to bridge the gap between a labelled source domain and an unlabelled target domain. Despite 1S1T being a well-researched topic, they are typically not deployed to the real world. Methods like Multi-Source Domain Adaptation and Multi-Target Domain Adaptation have evolved to model real-world problems but still do not generalise well. The fact that most of these methods assume a common label-set between source and target is very restrictive. Recent Open-Set Domain Adaptation methods handle unknown target labels but fail to generalise in multiple domains. To overcome these difficulties, first, we propose a novel generic domain adaptation (DA) setting named Open-Set Multi-Source Multi-Target Domain Adaptation (OS-nSmT), with n and m being number of source and target domains respectively. Next, we propose a graph attention based framework named DEGAA which can capture information from multiple source and target domains without knowing the exact label-set of the target. We argue that our method, though offered for multiple sources and multiple targets, can also be agnostic to various other DA settings. To check the robustness and versatility of DEGAA, we put forward ample experiments and ablation studies.