 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Prediction and MLLM aided Uncertainty Quantification in Scene Graph Generation
Mar 18, 2025Scene Graph Generation (SGG) aims to represent visual scenes by identifying objects and their pairwise relationships, providing a structured understanding of image content. However, inherent challenges like long-tailed class distributions and prediction variability necessitate uncertainty quantification in SGG for its practical viability. In this paper, we introduce a novel Conformal Prediction (CP) based framework, adaptive to any existing SGG method, for quantifying their predictive uncertainty by constructing well-calibrated prediction sets over their generated scene graphs. These scene graph prediction sets are designed to achieve statistically rigorous coverage guarantees. Additionally, to ensure these prediction sets contain the most practically interpretable scene graphs, we design an effective MLLM-based post-processing strategy for selecting the most visually and semantically plausible scene graphs within these prediction sets. We show that our proposed approach can produce diverse possible scene graphs from an image, assess the reliability of SGG methods, and improve overall SGG performance.
Unsupervised Domain Adaptation for Occlusion Resilient Human Pose Estimation
Jan 06, 2025



Occlusions are a significant challenge to human pose estimation algorithms, often resulting in inaccurate and anatomically implausible poses. Although current occlusion-robust human pose estimation algorithms exhibit impressive performance on existing datasets, their success is largely attributed to supervised training and the availability of additional information, such as multiple views or temporal continuity. Furthermore, these algorithms typically suffer from performance degradation under distribution shifts. While existing domain adaptive human pose estimation algorithms address this bottleneck, they tend to perform suboptimally when the target domain images are occluded, a common occurrence in real-life scenarios. To address these challenges, we propose OR-POSE: Unsupervised Domain Adaptation for Occlusion Resilient Human POSE Estimation. OR-POSE is an innovative unsupervised domain adaptation algorithm which effectively mitigates domain shifts and overcomes occlusion challenges by employing the mean teacher framework for iterative pseudo-label refinement. Additionally, OR-POSE reinforces realistic pose prediction by leveraging a learned human pose prior which incorporates the anatomical constraints of humans in the adaptation process. Lastly, OR-POSE avoids overfitting to inaccurate pseudo labels generated from heavily occluded images by employing a novel visibility-based curriculum learning approach. This enables the model to gradually transition from training samples with relatively less occlusion to more challenging, heavily occluded samples. Extensive experiments show that OR-POSE outperforms existing analogous state-of-the-art algorithms by $\sim$ 7% on challenging occluded human pose estimation datasets.
Multi-modal Pose Diffuser: A Multimodal Generative Conditional Pose Prior
Oct 18, 2024The Skinned Multi-Person Linear (SMPL) model plays a crucial role in 3D human pose estimation, providing a streamlined yet effective representation of the human body. However, ensuring the validity of SMPL configurations during tasks such as human mesh regression remains a significant challenge , highlighting the necessity for a robust human pose prior capable of discerning realistic human poses. To address this, we introduce MOPED: \underline{M}ulti-m\underline{O}dal \underline{P}os\underline{E} \underline{D}iffuser. MOPED is the first method to leverage a novel multi-modal conditional diffusion model as a prior for SMPL pose parameters. Our method offers powerful unconditional pose generation with the ability to condition on multi-modal inputs such as images and text. This capability enhances the applicability of our approach by incorporating additional context often overlooked in traditional pose priors. Extensive experiments across three distinct tasks-pose estimation, pose denoising, and pose completion-demonstrate that our multi-modal diffusion model-based prior significantly outperforms existing methods. These results indicate that our model captures a broader spectrum of plausible human poses.
POSTURE: Pose Guided Unsupervised Domain Adaptation for Human Body Part Segmentation
Jul 04, 2024



Existing algorithms for human body part segmentation have shown promising results on challenging datasets, primarily relying on end-to-end supervision. However, these algorithms exhibit severe performance drops in the face of domain shifts, leading to inaccurate segmentation masks. To tackle this issue, we introduce POSTURE: \underline{Po}se Guided Un\underline{s}upervised Domain Adap\underline{t}ation for H\underline{u}man Body Pa\underline{r}t S\underline{e}gmentation - an innovative pseudo-labelling approach designed to improve segmentation performance on the unlabeled target data. Distinct from conventional domain adaptive methods for general semantic segmentation, POSTURE stands out by considering the underlying structure of the human body and uses anatomical guidance from pose keypoints to drive the adaptation process. This strong inductive prior translates to impressive performance improvements, averaging 8\% over existing state-of-the-art domain adaptive semantic segmentation methods across three benchmark datasets. Furthermore, the inherent flexibility of our proposed approach facilitates seamless extension to source-free settings (SF-POSTURE), effectively mitigating potential privacy and computational concerns, with negligible drop in performance.
TEMP3D: Temporally Continuous 3D Human Pose Estimation Under Occlusions
Dec 24, 2023
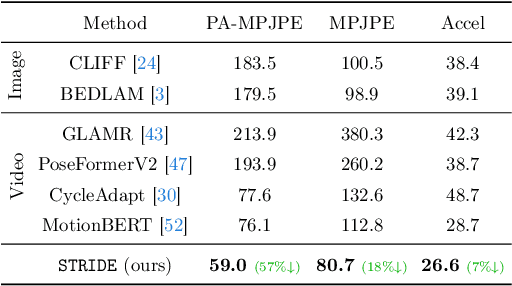

Existing 3D human pose estimation methods perform remarkably well in both monocular and multi-view settings. However, their efficacy diminishes significantly in the presence of heavy occlusions, which limits their practical utility. For video sequences, temporal continuity can help infer accurate poses, especially in heavily occluded frames. In this paper, we aim to leverage this potential of temporal continuity through human motion priors, coupled with large-scale pre-training on 3D poses and self-supervised learning, to enhance 3D pose estimation in a given video sequence. This leads to a temporally continuous 3D pose estimate on unlabelled in-the-wild videos, which may contain occlusions, while exclusively relying on pre-trained 3D pose models. We propose an unsupervised method named TEMP3D that aligns a motion prior model on a given in-the-wild video using existing SOTA single image-based 3D pose estimation methods to give temporally continuous output under occlusions. To evaluate our method, we test it on the Occluded Human3.6M dataset, our custom-built dataset which contains significantly large (up to 100%) human body occlusions incorporated into the Human3.6M dataset. We achieve SOTA results on Occluded Human3.6M and the OcMotion dataset while maintaining competitive performance on non-occluded data. URL: https://sites.google.com/ucr.edu/temp3d
Learning Deformable 3D Graph Similarity to Track Plant Cells in Unregistered Time Lapse Images
Sep 21, 2023Tracking of plant cells in images obtained by microscope is a challenging problem due to biological phenomena such as large number of cells, non-uniform growth of different layers of the tightly packed plant cells and cell division. Moreover, images in deeper layers of the tissue being noisy and unavoidable systemic errors inherent in the imaging process further complicates the problem. In this paper, we propose a novel learning-based method that exploits the tightly packed three-dimensional cell structure of plant cells to create a three-dimensional graph in order to perform accurate cell tracking. We further propose novel algorithms for cell division detection and effective three-dimensional registration, which improve upon the state-of-the-art algorithms. We demonstrate the efficacy of our algorithm in terms of tracking accuracy and inference-time on a benchmark dataset.
Prior-guided Source-free Domain Adaptation for Human Pose Estimation
Aug 26, 2023



Domain adaptation methods for 2D human pose estimation typically require continuous access to the source data during adaptation, which can be challenging due to privacy, memory, or computational constraints. To address this limitation, we focus on the task of source-free domain adaptation for pose estimation, where a source model must adapt to a new target domain using only unlabeled target data. Although recent advances have introduced source-free methods for classification tasks, extending them to the regression task of pose estimation is non-trivial. In this paper, we present Prior-guided Self-training (POST), a pseudo-labeling approach that builds on the popular Mean Teacher framework to compensate for the distribution shift. POST leverages prediction-level and feature-level consistency between a student and teacher model against certain image transformations. In the absence of source data, POST utilizes a human pose prior that regularizes the adaptation process by directing the model to generate more accurate and anatomically plausible pose pseudo-labels. Despite being simple and intuitive, our framework can deliver significant performance gains compared to applying the source model directly to the target data, as demonstrated in our extensive experiments and ablation studies. In fact, our approach achieves comparable performance to recent state-of-the-art methods that use source data for adaptation.
Poisson2Sparse: Self-Supervised Poisson Denoising From a Single Image
Jun 04, 2022

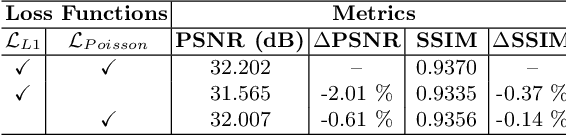
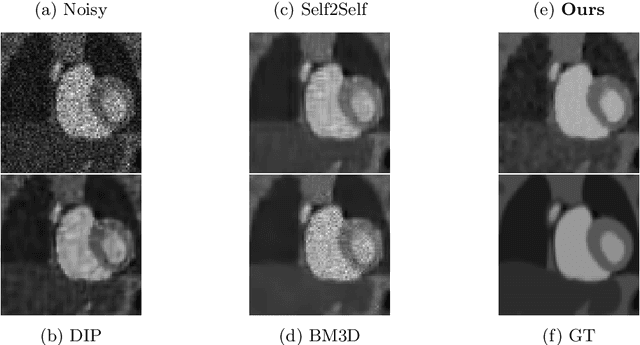
Image enhancement approaches often assume that the noise is signal independent, and approximate the degradation model as zero-mean additive Gaussian noise. However, this assumption does not hold for biomedical imaging systems where sensor-based sources of noise are proportional to signal strengths, and the noise is better represented as a Poisson process. In this work, we explore a sparsity and dictionary learning-based approach and present a novel self-supervised learning method for single-image denoising where the noise is approximated as a Poisson process, requiring no clean ground-truth data. Specifically, we approximate traditional iterative optimization algorithms for image denoising with a recurrent neural network which enforces sparsity with respect to the weights of the network. Since the sparse representations are based on the underlying image, it is able to suppress the spurious components (noise) in the image patches, thereby introducing implicit regularization for denoising task through the network structure. Experiments on two bio-imaging datasets demonstrate that our method outperforms the state-of-the-art approaches in terms of PSNR and SSIM. Our qualitative results demonstrate that, in addition to higher performance on standard quantitative metrics, we are able to recover much more subtle details than other compared approaches.