 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Oracle Feedback with Vision-Language Embeddings for Preference-Based RL
Mar 30, 2026Preference-based reinforcement learning can learn effective reward functions from comparisons, but its scalability is constrained by the high cost of oracle feedback. Lightweight vision-language embedding (VLE) models provide a cheaper alternative, but their noisy outputs limit their effectiveness as standalone reward generators. To address this challenge, we propose ROVED, a hybrid framework that combines VLE-based supervision with targeted oracle feedback. Our method uses the VLE to generate segment-level preferences and defers to an oracle only for samples with high uncertainty, identified through a filtering mechanism. In addition, we introduce a parameter-efficient fine-tuning method that adapts the VLE with the obtained oracle feedback in order to improve the model over time in a synergistic fashion. This ensures the retention of the scalability of embeddings and the accuracy of oracles, while avoiding their inefficiencies. Across multiple robotic manipulation tasks, ROVED matches or surpasses prior preference-based methods while reducing oracle queries by up to 80%. Remarkably, the adapted VLE generalizes across tasks, yielding cumulative annotation savings of up to 90%, highlighting the practicality of combining scalable embeddings with precise oracle supervision for preference-based RL.
Towards Source-Free Machine Unlearning
Aug 20, 2025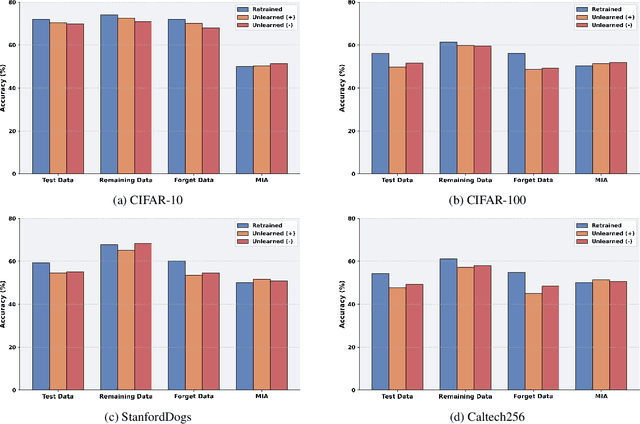
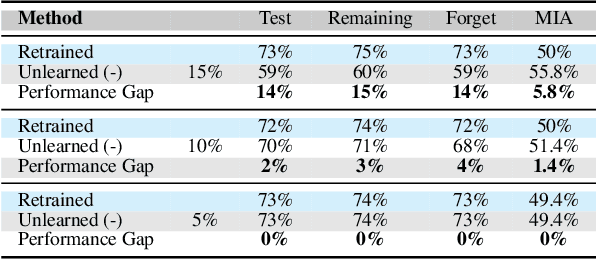
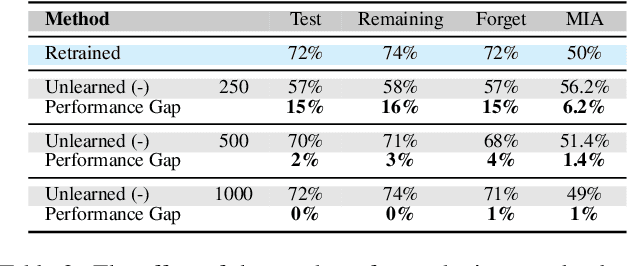
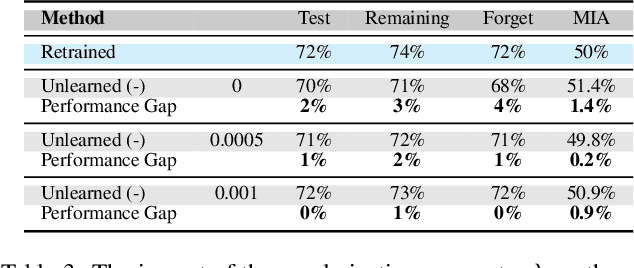
As machine learning becomes more pervasive and data privacy regulations evolve, the ability to remove private or copyrighted information from trained models is becoming an increasingly critical requirement. Existing unlearning methods often rely on the assumption of having access to the entire training dataset during the forgetting process. However, this assumption may not hold true in practical scenarios where the original training data may not be accessible, i.e., the source-free setting. To address this challenge, we focus on the source-free unlearning scenario, where an unlearning algorithm must be capable of removing specific data from a trained model without requiring access to the original training dataset. Building on recent work, we present a method that can estimate the Hessian of the unknown remaining training data, a crucial component required for efficient unlearning. Leveraging this estimation technique, our method enables efficient zero-shot unlearning while providing robust theoretical guarantees on the unlearning performance, while maintaining performance on the remaining data. Extensive experiments over a wide range of datasets verify the efficacy of our method.
Preference VLM: Leveraging VLMs for Scalable Preference-Based Reinforcement Learning
Feb 03, 2025



Preference-based reinforcement learning (RL) offers a promising approach for aligning policies with human intent but is often constrained by the high cost of human feedback. In this work, we introduce PrefVLM, a framework that integrates Vision-Language Models (VLMs) with selective human feedback to significantly reduce annotation requirements while maintaining performance. Our method leverages VLMs to generate initial preference labels, which are then filtered to identify uncertain cases for targeted human annotation. Additionally, we adapt VLMs using a self-supervised inverse dynamics loss to improve alignment with evolving policies. Experiments on Meta-World manipulation tasks demonstrate that PrefVLM achieves comparable or superior success rates to state-of-the-art methods while using up to 2 x fewer human annotations. Furthermore, we show that adapted VLMs enable efficient knowledge transfer across tasks, further minimizing feedback needs. Our results highlight the potential of combining VLMs with selective human supervision to make preference-based RL more scalable and practical.
Multi-modal Pose Diffuser: A Multimodal Generative Conditional Pose Prior
Oct 18, 2024The Skinned Multi-Person Linear (SMPL) model plays a crucial role in 3D human pose estimation, providing a streamlined yet effective representation of the human body. However, ensuring the validity of SMPL configurations during tasks such as human mesh regression remains a significant challenge , highlighting the necessity for a robust human pose prior capable of discerning realistic human poses. To address this, we introduce MOPED: \underline{M}ulti-m\underline{O}dal \underline{P}os\underline{E} \underline{D}iffuser. MOPED is the first method to leverage a novel multi-modal conditional diffusion model as a prior for SMPL pose parameters. Our method offers powerful unconditional pose generation with the ability to condition on multi-modal inputs such as images and text. This capability enhances the applicability of our approach by incorporating additional context often overlooked in traditional pose priors. Extensive experiments across three distinct tasks-pose estimation, pose denoising, and pose completion-demonstrate that our multi-modal diffusion model-based prior significantly outperforms existing methods. These results indicate that our model captures a broader spectrum of plausible human poses.
Robust Offline Imitation Learning from Diverse Auxiliary Data
Oct 04, 2024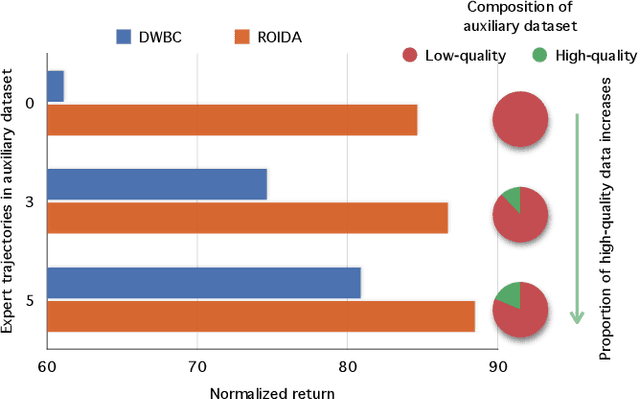
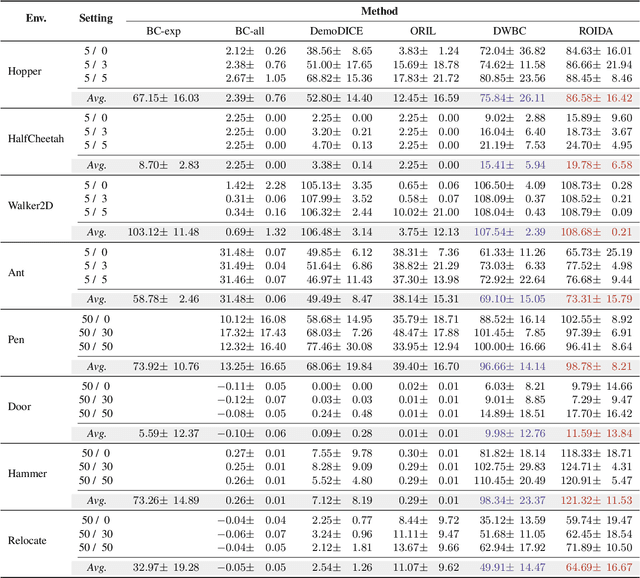
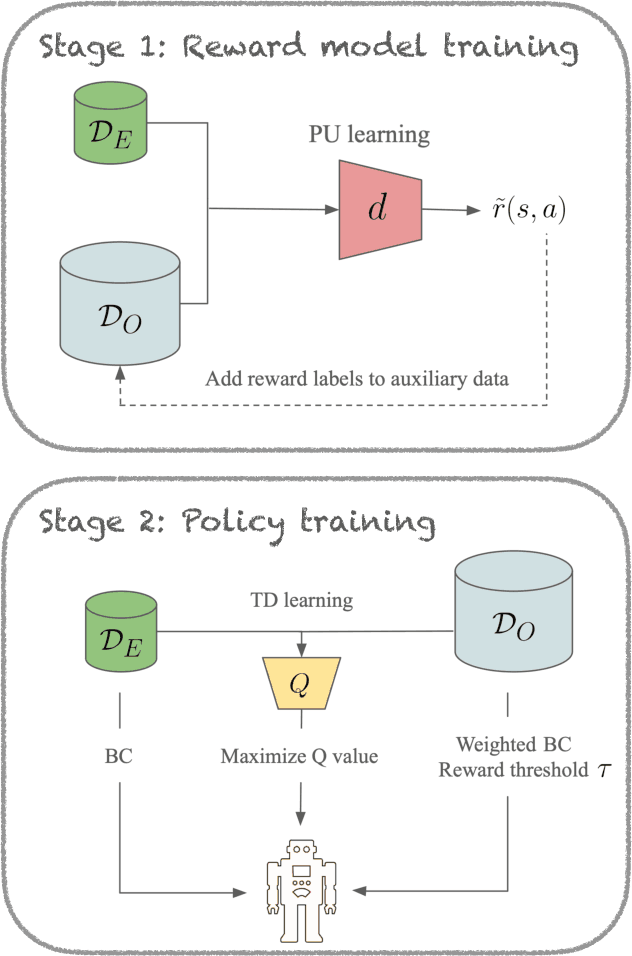
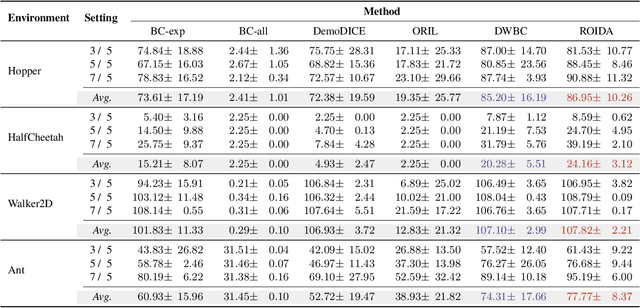
Offline imitation learning enables learning a policy solely from a set of expert demonstrations, without any environment interaction. To alleviate the issue of distribution shift arising due to the small amount of expert data, recent works incorporate large numbers of auxiliary demonstrations alongside the expert data. However, the performance of these approaches rely on assumptions about the quality and composition of the auxiliary data. However, they are rarely successful when those assumptions do not hold. To address this limitation, we propose Robust Offline Imitation from Diverse Auxiliary Data (ROIDA). ROIDA first identifies high-quality transitions from the entire auxiliary dataset using a learned reward function. These high-reward samples are combined with the expert demonstrations for weighted behavioral cloning. For lower-quality samples, ROIDA applies temporal difference learning to steer the policy towards high-reward states, improving long-term returns. This two-pronged approach enables our framework to effectively leverage both high and low-quality data without any assumptions. Extensive experiments validate that ROIDA achieves robust and consistent performance across multiple auxiliary datasets with diverse ratios of expert and non-expert demonstrations. ROIDA effectively leverages unlabeled auxiliary data, outperforming prior methods reliant on specific data assumptions.
Open-World Dynamic Prompt and Continual Visual Representation Learning
Sep 09, 2024

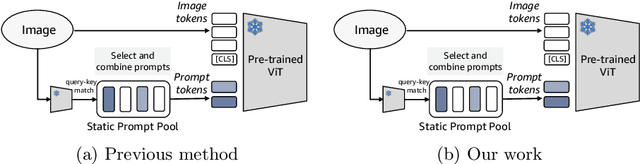

The open world is inherently dynamic, characterized by ever-evolving concepts and distributions. Continual learning (CL) in this dynamic open-world environment presents a significant challenge in effectively generalizing to unseen test-time classes. To address this challenge, we introduce a new practical CL setting tailored for open-world visual representation learning. In this setting, subsequent data streams systematically introduce novel classes that are disjoint from those seen in previous training phases, while also remaining distinct from the unseen test classes. In response, we present Dynamic Prompt and Representation Learner (DPaRL), a simple yet effective Prompt-based CL (PCL) method. Our DPaRL learns to generate dynamic prompts for inference, as opposed to relying on a static prompt pool in previous PCL methods. In addition, DPaRL jointly learns dynamic prompt generation and discriminative representation at each training stage whereas prior PCL methods only refine the prompt learning throughout the process. Our experimental results demonstrate the superiority of our approach, surpassing state-of-the-art methods on well-established open-world image retrieval benchmarks by an average of 4.7\% improvement in Recall@1 performance.
POSTURE: Pose Guided Unsupervised Domain Adaptation for Human Body Part Segmentation
Jul 04, 2024



Existing algorithms for human body part segmentation have shown promising results on challenging datasets, primarily relying on end-to-end supervision. However, these algorithms exhibit severe performance drops in the face of domain shifts, leading to inaccurate segmentation masks. To tackle this issue, we introduce POSTURE: \underline{Po}se Guided Un\underline{s}upervised Domain Adap\underline{t}ation for H\underline{u}man Body Pa\underline{r}t S\underline{e}gmentation - an innovative pseudo-labelling approach designed to improve segmentation performance on the unlabeled target data. Distinct from conventional domain adaptive methods for general semantic segmentation, POSTURE stands out by considering the underlying structure of the human body and uses anatomical guidance from pose keypoints to drive the adaptation process. This strong inductive prior translates to impressive performance improvements, averaging 8\% over existing state-of-the-art domain adaptive semantic segmentation methods across three benchmark datasets. Furthermore, the inherent flexibility of our proposed approach facilitates seamless extension to source-free settings (SF-POSTURE), effectively mitigating potential privacy and computational concerns, with negligible drop in performance.
MeTA: Multi-source Test Time Adaptation
Jan 04, 2024



Test time adaptation is the process of adapting, in an unsupervised manner, a pre-trained source model to each incoming batch of the test data (i.e., without requiring a substantial portion of the test data to be available, as in traditional domain adaptation) and without access to the source data. Since it works with each batch of test data, it is well-suited for dynamic environments where decisions need to be made as the data is streaming in. Current test time adaptation methods are primarily focused on a single source model. We propose the first completely unsupervised Multi-source Test Time Adaptation (MeTA) framework that handles multiple source models and optimally combines them to adapt to the test data. MeTA has two distinguishing features. First, it efficiently obtains the optimal combination weights to combine the source models to adapt to the test data distribution. Second, it identifies which of the source model parameters to update so that only the model which is most correlated to the target data is adapted, leaving the less correlated ones untouched; this mitigates the issue of "forgetting" the source model parameters by focusing only on the source model that exhibits the strongest correlation with the test batch distribution. Experiments on diverse datasets demonstrate that the combination of multiple source models does at least as well as the best source (with hindsight knowledge), and performance does not degrade as the test data distribution changes over time (robust to forgetting).
TEMP3D: Temporally Continuous 3D Human Pose Estimation Under Occlusions
Dec 24, 2023
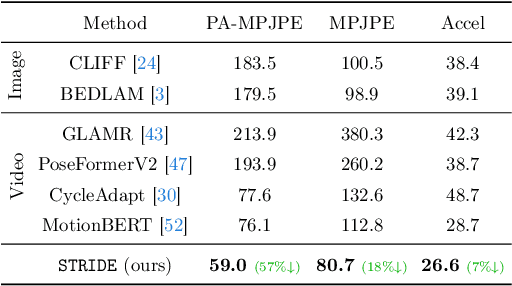
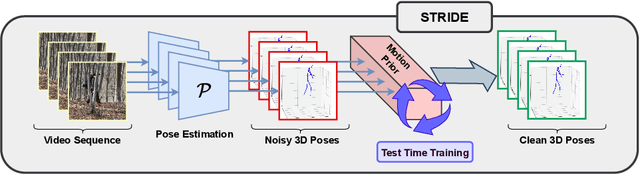

Existing 3D human pose estimation methods perform remarkably well in both monocular and multi-view settings. However, their efficacy diminishes significantly in the presence of heavy occlusions, which limits their practical utility. For video sequences, temporal continuity can help infer accurate poses, especially in heavily occluded frames. In this paper, we aim to leverage this potential of temporal continuity through human motion priors, coupled with large-scale pre-training on 3D poses and self-supervised learning, to enhance 3D pose estimation in a given video sequence. This leads to a temporally continuous 3D pose estimate on unlabelled in-the-wild videos, which may contain occlusions, while exclusively relying on pre-trained 3D pose models. We propose an unsupervised method named TEMP3D that aligns a motion prior model on a given in-the-wild video using existing SOTA single image-based 3D pose estimation methods to give temporally continuous output under occlusions. To evaluate our method, we test it on the Occluded Human3.6M dataset, our custom-built dataset which contains significantly large (up to 100%) human body occlusions incorporated into the Human3.6M dataset. We achieve SOTA results on Occluded Human3.6M and the OcMotion dataset while maintaining competitive performance on non-occluded data. URL: https://sites.google.com/ucr.edu/temp3d
POISE: Pose Guided Human Silhouette Extraction under Occlusions
Nov 09, 2023



Human silhouette extraction is a fundamental task in computer vision with applications in various downstream tasks. However, occlusions pose a significant challenge, leading to incomplete and distorted silhouettes. To address this challenge, we introduce POISE: Pose Guided Human Silhouette Extraction under Occlusions, a novel self-supervised fusion framework that enhances accuracy and robustness in human silhouette prediction. By combining initial silhouette estimates from a segmentation model with human joint predictions from a 2D pose estimation model, POISE leverages the complementary strengths of both approaches, effectively integrating precise body shape information and spatial information to tackle occlusions. Furthermore, the self-supervised nature of \POISE eliminates the need for costly annotations, making it scalable and practical. Extensive experimental results demonstrate its superiority in improving silhouette extraction under occlusions, with promising results in downstream tasks such as gait recognition. The code for our method is available https://github.com/take2rohit/poise.