 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Source-Free Machine Unlearning
Aug 20, 2025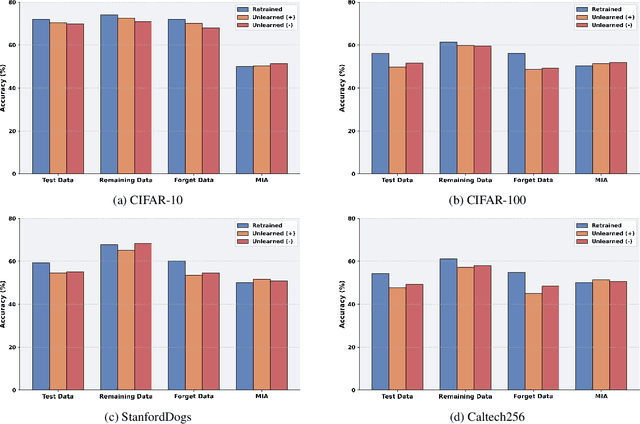
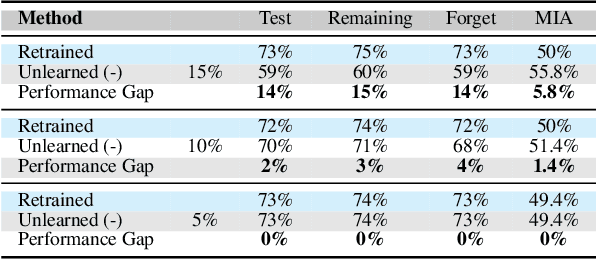
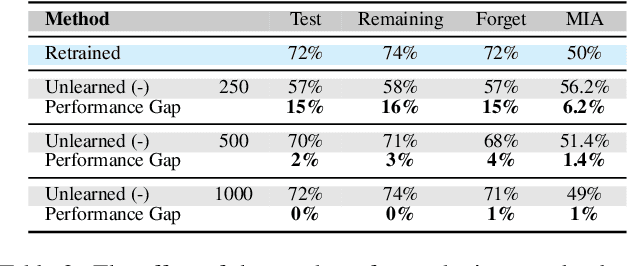
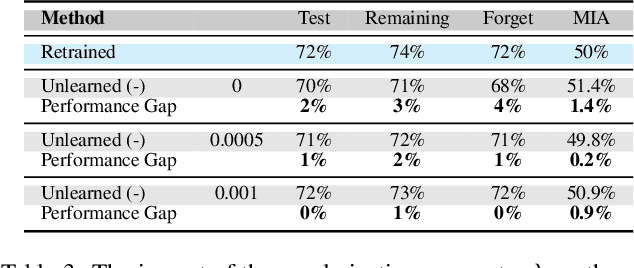
As machine learning becomes more pervasive and data privacy regulations evolve, the ability to remove private or copyrighted information from trained models is becoming an increasingly critical requirement. Existing unlearning methods often rely on the assumption of having access to the entire training dataset during the forgetting process. However, this assumption may not hold true in practical scenarios where the original training data may not be accessible, i.e., the source-free setting. To address this challenge, we focus on the source-free unlearning scenario, where an unlearning algorithm must be capable of removing specific data from a trained model without requiring access to the original training dataset. Building on recent work, we present a method that can estimate the Hessian of the unknown remaining training data, a crucial component required for efficient unlearning. Leveraging this estimation technique, our method enables efficient zero-shot unlearning while providing robust theoretical guarantees on the unlearning performance, while maintaining performance on the remaining data. Extensive experiments over a wide range of datasets verify the efficacy of our method.
HEAL: An Empirical Study on Hallucinations in Embodied Agents Driven by Large Language Models
Jun 18, 2025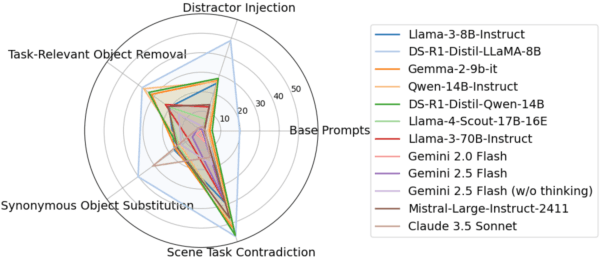
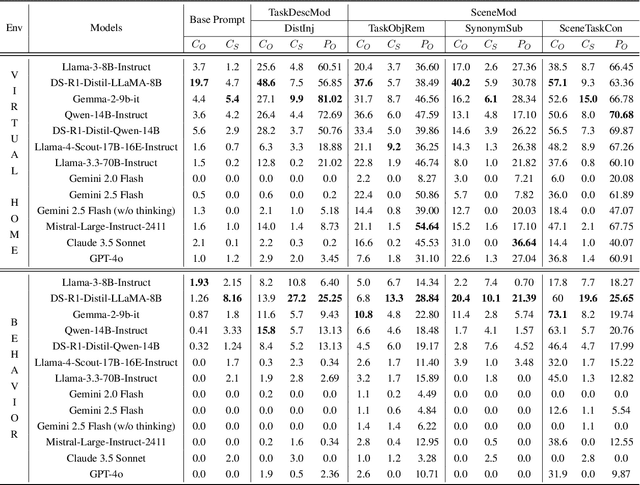

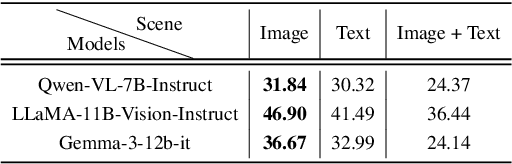
Large language models (LLMs) are increasingly being adopted as the cognitive core of embodied agents. However, inherited hallucinations, which stem from failures to ground user instructions in the observed physical environment, can lead to navigation errors, such as searching for a refrigerator that does not exist. In this paper, we present the first systematic study of hallucinations in LLM-based embodied agents performing long-horizon tasks under scene-task inconsistencies. Our goal is to understand to what extent hallucinations occur, what types of inconsistencies trigger them, and how current models respond. To achieve these goals, we construct a hallucination probing set by building on an existing benchmark, capable of inducing hallucination rates up to 40x higher than base prompts. Evaluating 12 models across two simulation environments, we find that while models exhibit reasoning, they fail to resolve scene-task inconsistencies-highlighting fundamental limitations in handling infeasible tasks. We also provide actionable insights on ideal model behavior for each scenario, offering guidance for developing more robust and reliable planning strategies.
SSMT: Few-Shot Traffic Forecasting with Single Source Meta-Transfer
Oct 21, 2024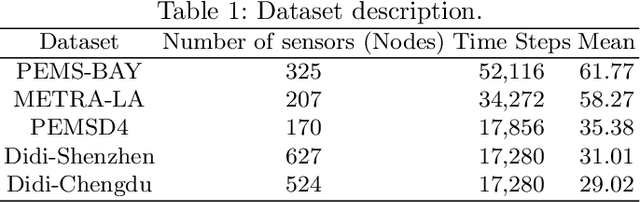
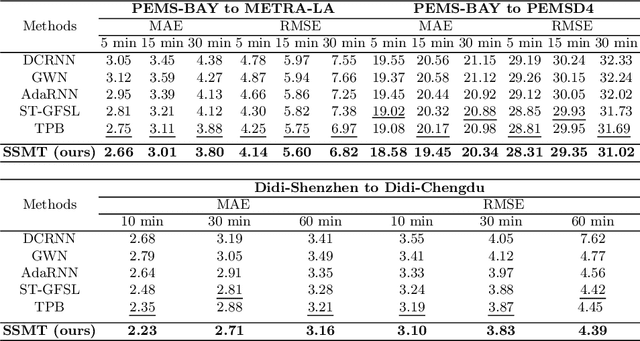
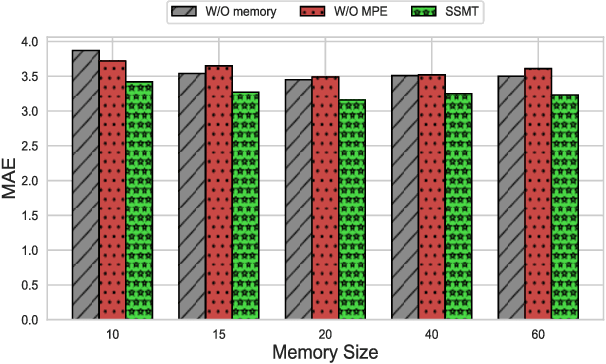

Traffic forecasting in Intelligent Transportation Systems (ITS) is vital for intelligent traffic prediction. Yet, ITS often relies on data from traffic sensors or vehicle devices, where certain cities might not have all those smart devices or enabling infrastructures. Also, recent studies have employed meta-learning to generalize spatial-temporal traffic networks, utilizing data from multiple cities for effective traffic forecasting for data-scarce target cities. However, collecting data from multiple cities can be costly and time-consuming. To tackle this challenge, we introduce Single Source Meta-Transfer Learning (SSMT) which relies only on a single source city for traffic prediction. Our method harnesses this transferred knowledge to enable few-shot traffic forecasting, particularly when the target city possesses limited data. Specifically, we use memory-augmented attention to store the heterogeneous spatial knowledge from the source city and selectively recall them for the data-scarce target city. We extend the idea of sinusoidal positional encoding to establish meta-learning tasks by leveraging diverse temporal traffic patterns from the source city. Moreover, to capture a more generalized representation of the positions we introduced a meta-positional encoding that learns the most optimal representation of the temporal pattern across all the tasks. We experiment on five real-world benchmark datasets to demonstrate that our method outperforms several existing methods in time series traffic prediction.
Source-Free Online Domain Adaptive Semantic Segmentation of Satellite Images under Image Degradation
Jan 04, 2024

Online adaptation to distribution shifts in satellite image segmentation stands as a crucial yet underexplored problem. In this paper, we address source-free and online domain adaptation, i.e., test-time adaptation (TTA), for satellite images, with the focus on mitigating distribution shifts caused by various forms of image degradation. Towards achieving this goal, we propose a novel TTA approach involving two effective strategies. First, we progressively estimate the global Batch Normalization (BN) statistics of the target distribution with incoming data stream. Leveraging these statistics during inference has the ability to effectively reduce domain gap. Furthermore, we enhance prediction quality by refining the predicted masks using global class centers. Both strategies employ dynamic momentum for fast and stable convergence. Notably, our method is backpropagation-free and hence fast and lightweight, making it highly suitable for on-the-fly adaptation to new domain. Through comprehensive experiments across various domain adaptation scenarios, we demonstrate the robust performance of our method.
MeTA: Multi-source Test Time Adaptation
Jan 04, 2024



Test time adaptation is the process of adapting, in an unsupervised manner, a pre-trained source model to each incoming batch of the test data (i.e., without requiring a substantial portion of the test data to be available, as in traditional domain adaptation) and without access to the source data. Since it works with each batch of test data, it is well-suited for dynamic environments where decisions need to be made as the data is streaming in. Current test time adaptation methods are primarily focused on a single source model. We propose the first completely unsupervised Multi-source Test Time Adaptation (MeTA) framework that handles multiple source models and optimally combines them to adapt to the test data. MeTA has two distinguishing features. First, it efficiently obtains the optimal combination weights to combine the source models to adapt to the test data distribution. Second, it identifies which of the source model parameters to update so that only the model which is most correlated to the target data is adapted, leaving the less correlated ones untouched; this mitigates the issue of "forgetting" the source model parameters by focusing only on the source model that exhibits the strongest correlation with the test batch distribution. Experiments on diverse datasets demonstrate that the combination of multiple source models does at least as well as the best source (with hindsight knowledge), and performance does not degrade as the test data distribution changes over time (robust to forgetting).
Active Learning Guided Federated Online Adaptation: Applications in Medical Image Segmentation
Dec 08, 2023Data privacy, storage, and distribution shifts are major bottlenecks in medical image analysis. Data cannot be shared across patients, physicians, and facilities due to privacy concerns, usually requiring each patient's data to be analyzed in a discreet setting at a near real-time pace. However, one would like to take advantage of the accumulated knowledge across healthcare facilities as the computational systems analyze data of more and more patients while incorporating feedback provided by physicians to improve accuracy. Motivated by these, we propose a method for medical image segmentation that adapts to each incoming data batch (online adaptation), incorporates physician feedback through active learning, and assimilates knowledge across facilities in a federated setup. Combining an online adaptation scheme at test time with an efficient sampling strategy with budgeted annotation helps bridge the gap between the source and the incoming stream of target domain data. A federated setup allows collaborative aggregation of knowledge across distinct distributed models without needing to share the data across different models. This facilitates the improvement of performance over time by accumulating knowledge across users. Towards achieving these goals, we propose a computationally amicable, privacy-preserving image segmentation technique \textbf{DrFRODA} that uses federated learning to adapt the model in an online manner with feedback from doctors in the loop. Our experiments on publicly available datasets show that the proposed distributed active learning-based online adaptation method outperforms unsupervised online adaptation methods and shows competitive results with offline active learning-based adaptation methods.
Effective Restoration of Source Knowledge in Continual Test Time Adaptation
Nov 08, 2023Traditional test-time adaptation (TTA) methods face significant challenges in adapting to dynamic environments characterized by continuously changing long-term target distributions. These challenges primarily stem from two factors: catastrophic forgetting of previously learned valuable source knowledge and gradual error accumulation caused by miscalibrated pseudo labels. To address these issues, this paper introduces an unsupervised domain change detection method that is capable of identifying domain shifts in dynamic environments and subsequently resets the model parameters to the original source pre-trained values. By restoring the knowledge from the source, it effectively corrects the negative consequences arising from the gradual deterioration of model parameters caused by ongoing shifts in the domain. Our method involves progressive estimation of global batch-norm statistics specific to each domain, while keeping track of changes in the statistics triggered by domain shifts. Importantly, our method is agnostic to the specific adaptation technique employed and thus, can be incorporated to existing TTA methods to enhance their performance in dynamic environments. We perform extensive experiments on benchmark datasets to demonstrate the superior performance of our method compared to state-of-the-art adaptation methods.
HRFNet: High-Resolution Forgery Network for Localizing Satellite Image Manipulation
Jul 20, 2023Existing high-resolution satellite image forgery localization methods rely on patch-based or downsampling-based training. Both of these training methods have major drawbacks, such as inaccurate boundaries between pristine and forged regions, the generation of unwanted artifacts, etc. To tackle the aforementioned challenges, inspired by the high-resolution image segmentation literature, we propose a novel model called HRFNet to enable satellite image forgery localization effectively. Specifically, equipped with shallow and deep branches, our model can successfully integrate RGB and resampling features in both global and local manners to localize forgery more accurately. We perform various experiments to demonstrate that our method achieves the best performance, while the memory requirement and processing speed are not compromised compared to existing methods.
STLGRU: Spatio-Temporal Lightweight Graph GRU for Traffic Flow Prediction
Dec 08, 2022Reliable forecasting of traffic flow requires efficient modeling of traffic data. Different correlations and influences arise in a dynamic traffic network, making modeling a complicated task. Existing literature has proposed many different methods to capture the complex underlying spatial-temporal relations of traffic networks. However, methods still struggle to capture different local and global dependencies of long-range nature. Also, as more and more sophisticated methods are being proposed, models are increasingly becoming memory-heavy and, thus, unsuitable for low-powered devices. In this paper, we focus on solving these problems by proposing a novel deep learning framework - STLGRU. Specifically, our proposed STLGRU can effectively capture both local and global spatial-temporal relations of a traffic network using memory-augmented attention and gating mechanism. Instead of employing separate temporal and spatial components, we show that our memory module and gated unit can learn the spatial-temporal dependencies successfully, allowing for reduced memory usage with fewer parameters. We extensively experiment on several real-world traffic prediction datasets to show that our model performs better than existing methods while the memory footprint remains lower. Code is available at \url{https://github.com/Kishor-Bhaumik/STLGRU}.
CFL-Net: Image Forgery Localization Using Contrastive Learning
Oct 04, 2022
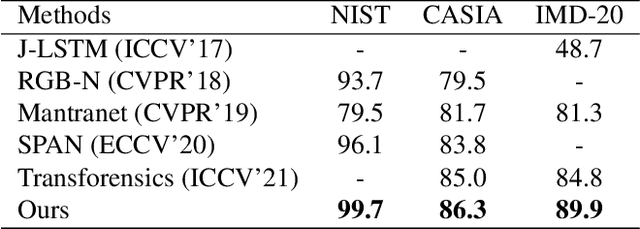
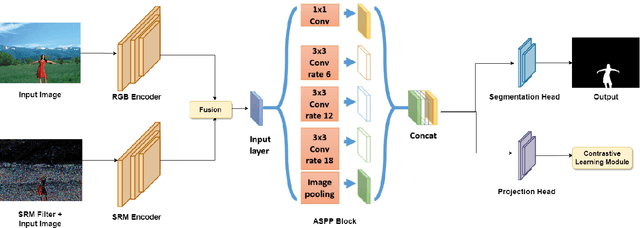
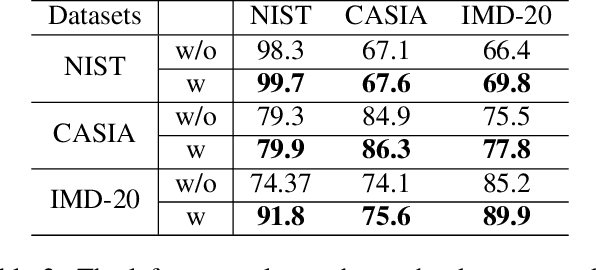
Conventional forgery localizing methods usually rely on different forgery footprints such as JPEG artifacts, edge inconsistency, camera noise, etc., with cross-entropy loss to locate manipulated regions. However, these methods have the disadvantage of over-fitting and focusing on only a few specific forgery footprints. On the other hand, real-life manipulated images are generated via a wide variety of forgery operations and thus, leave behind a wide variety of forgery footprints. Therefore, we need a more general approach for image forgery localization that can work well on a variety of forgery conditions. A key assumption in underlying forged region localization is that there remains a difference of feature distribution between untampered and manipulated regions in each forged image sample, irrespective of the forgery type. In this paper, we aim to leverage this difference of feature distribution to aid in image forgery localization. Specifically, we use contrastive loss to learn mapping into a feature space where the features between untampered and manipulated regions are well-separated for each image. Also, our method has the advantage of localizing manipulated region without requiring any prior knowledge or assumption about the forgery type. We demonstrate that our work outperforms several existing methods on three benchmark image manipulation datasets. Code is available at https://github.com/niloy193/CFLNet.