 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIXAD: Memory-Induced Explainable Time Series Anomaly Detection
Oct 30, 2024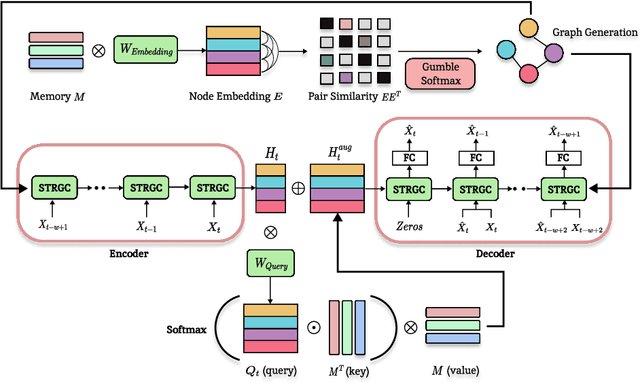


For modern industrial applications, accurately detecting and diagnosing anomalies in multivariate time series data is essential. Despite such need, most state-of-the-art methods often prioritize detection performance over model interpretability. Addressing this gap, we introduce MIXAD (Memory-Induced Explainable Time Series Anomaly Detection), a model designed for interpretable anomaly detection. MIXAD leverages a memory network alongside spatiotemporal processing units to understand the intricate dynamics and topological structures inherent in sensor relationships. We also introduce a novel anomaly scoring method that detects significant shifts in memory activation patterns during anomalies. Our approach not only ensures decent detection performance but also outperforms state-of-the-art baselines by 34.30% and 34.51% in interpretability metrics.
SSMT: Few-Shot Traffic Forecasting with Single Source Meta-Transfer
Oct 21, 2024
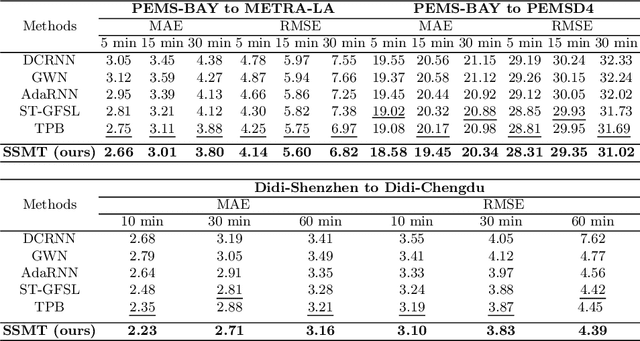
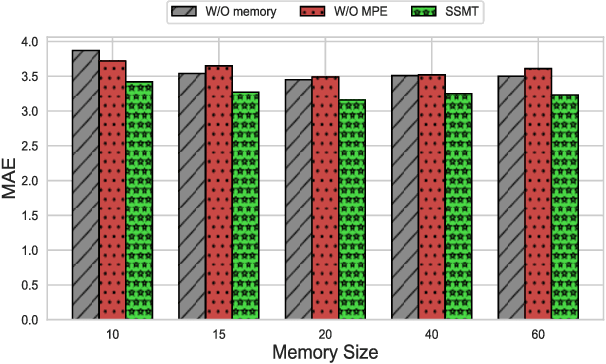

Traffic forecasting in Intelligent Transportation Systems (ITS) is vital for intelligent traffic prediction. Yet, ITS often relies on data from traffic sensors or vehicle devices, where certain cities might not have all those smart devices or enabling infrastructures. Also, recent studies have employed meta-learning to generalize spatial-temporal traffic networks, utilizing data from multiple cities for effective traffic forecasting for data-scarce target cities. However, collecting data from multiple cities can be costly and time-consuming. To tackle this challenge, we introduce Single Source Meta-Transfer Learning (SSMT) which relies only on a single source city for traffic prediction. Our method harnesses this transferred knowledge to enable few-shot traffic forecasting, particularly when the target city possesses limited data. Specifically, we use memory-augmented attention to store the heterogeneous spatial knowledge from the source city and selectively recall them for the data-scarce target city. We extend the idea of sinusoidal positional encoding to establish meta-learning tasks by leveraging diverse temporal traffic patterns from the source city. Moreover, to capture a more generalized representation of the positions we introduced a meta-positional encoding that learns the most optimal representation of the temporal pattern across all the tasks. We experiment on five real-world benchmark datasets to demonstrate that our method outperforms several existing methods in time series traffic prediction.
Source-Free Online Domain Adaptive Semantic Segmentation of Satellite Images under Image Degradation
Jan 04, 2024

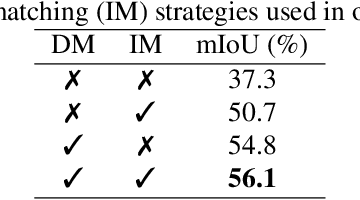
Online adaptation to distribution shifts in satellite image segmentation stands as a crucial yet underexplored problem. In this paper, we address source-free and online domain adaptation, i.e., test-time adaptation (TTA), for satellite images, with the focus on mitigating distribution shifts caused by various forms of image degradation. Towards achieving this goal, we propose a novel TTA approach involving two effective strategies. First, we progressively estimate the global Batch Normalization (BN) statistics of the target distribution with incoming data stream. Leveraging these statistics during inference has the ability to effectively reduce domain gap. Furthermore, we enhance prediction quality by refining the predicted masks using global class centers. Both strategies employ dynamic momentum for fast and stable convergence. Notably, our method is backpropagation-free and hence fast and lightweight, making it highly suitable for on-the-fly adaptation to new domain. Through comprehensive experiments across various domain adaptation scenarios, we demonstrate the robust performance of our method.
HRFNet: High-Resolution Forgery Network for Localizing Satellite Image Manipulation
Jul 20, 2023Existing high-resolution satellite image forgery localization methods rely on patch-based or downsampling-based training. Both of these training methods have major drawbacks, such as inaccurate boundaries between pristine and forged regions, the generation of unwanted artifacts, etc. To tackle the aforementioned challenges, inspired by the high-resolution image segmentation literature, we propose a novel model called HRFNet to enable satellite image forgery localization effectively. Specifically, equipped with shallow and deep branches, our model can successfully integrate RGB and resampling features in both global and local manners to localize forgery more accurately. We perform various experiments to demonstrate that our method achieves the best performance, while the memory requirement and processing speed are not compromised compared to existing methods.
STLGRU: Spatio-Temporal Lightweight Graph GRU for Traffic Flow Prediction
Dec 08, 2022Reliable forecasting of traffic flow requires efficient modeling of traffic data. Different correlations and influences arise in a dynamic traffic network, making modeling a complicated task. Existing literature has proposed many different methods to capture the complex underlying spatial-temporal relations of traffic networks. However, methods still struggle to capture different local and global dependencies of long-range nature. Also, as more and more sophisticated methods are being proposed, models are increasingly becoming memory-heavy and, thus, unsuitable for low-powered devices. In this paper, we focus on solving these problems by proposing a novel deep learning framework - STLGRU. Specifically, our proposed STLGRU can effectively capture both local and global spatial-temporal relations of a traffic network using memory-augmented attention and gating mechanism. Instead of employing separate temporal and spatial components, we show that our memory module and gated unit can learn the spatial-temporal dependencies successfully, allowing for reduced memory usage with fewer parameters. We extensively experiment on several real-world traffic prediction datasets to show that our model performs better than existing methods while the memory footprint remains lower. Code is available at \url{https://github.com/Kishor-Bhaumik/STLGRU}.
CFL-Net: Image Forgery Localization Using Contrastive Learning
Oct 04, 2022
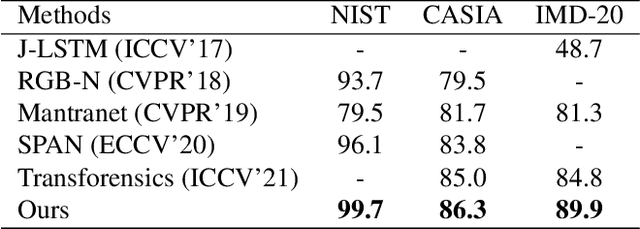
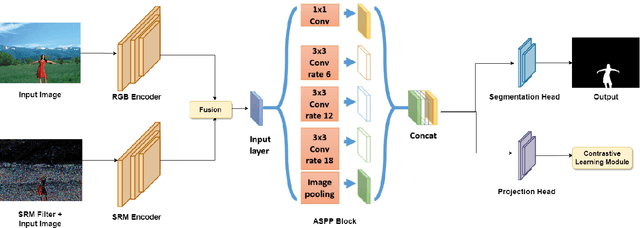
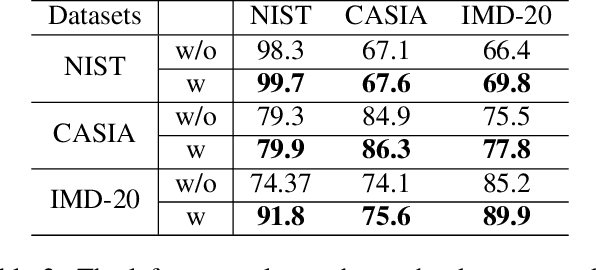
Conventional forgery localizing methods usually rely on different forgery footprints such as JPEG artifacts, edge inconsistency, camera noise, etc., with cross-entropy loss to locate manipulated regions. However, these methods have the disadvantage of over-fitting and focusing on only a few specific forgery footprints. On the other hand, real-life manipulated images are generated via a wide variety of forgery operations and thus, leave behind a wide variety of forgery footprints. Therefore, we need a more general approach for image forgery localization that can work well on a variety of forgery conditions. A key assumption in underlying forged region localization is that there remains a difference of feature distribution between untampered and manipulated regions in each forged image sample, irrespective of the forgery type. In this paper, we aim to leverage this difference of feature distribution to aid in image forgery localization. Specifically, we use contrastive loss to learn mapping into a feature space where the features between untampered and manipulated regions are well-separated for each image. Also, our method has the advantage of localizing manipulated region without requiring any prior knowledge or assumption about the forgery type. We demonstrate that our work outperforms several existing methods on three benchmark image manipulation datasets. Code is available at https://github.com/niloy193/CFLNet.
Variational Stacked Local Attention Networks for Diverse Video Captioning
Jan 04, 2022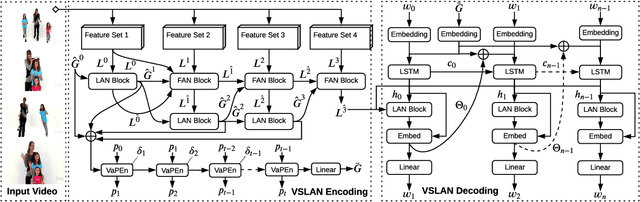

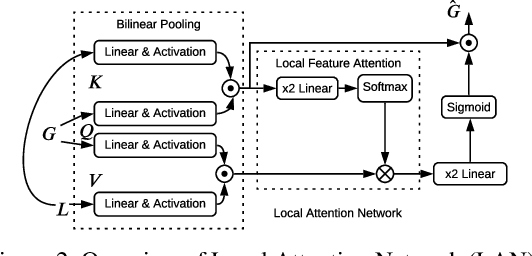
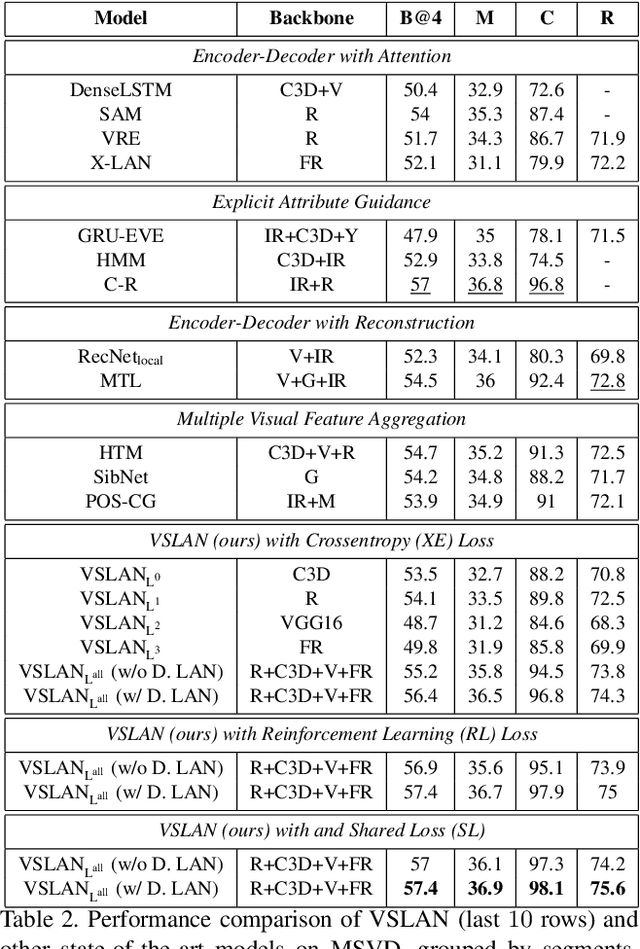
While describing Spatio-temporal events in natural language, video captioning models mostly rely on the encoder's latent visual representation. Recent progress on the encoder-decoder model attends encoder features mainly in linear interaction with the decoder. However, growing model complexity for visual data encourages more explicit feature interaction for fine-grained information, which is currently absent in the video captioning domain. Moreover, feature aggregations methods have been used to unveil richer visual representation, either by the concatenation or using a linear layer. Though feature sets for a video semantically overlap to some extent, these approaches result in objective mismatch and feature redundancy. In addition, diversity in captions is a fundamental component of expressing one event from several meaningful perspectives, currently missing in the temporal, i.e., video captioning domain. To this end, we propose Variational Stacked Local Attention Network (VSLAN), which exploits low-rank bilinear pooling for self-attentive feature interaction and stacking multiple video feature streams in a discount fashion. Each feature stack's learned attributes contribute to our proposed diversity encoding module, followed by the decoding query stage to facilitate end-to-end diverse and natural captions without any explicit supervision on attributes. We evaluate VSLAN on MSVD and MSR-VTT datasets in terms of syntax and diversity. The CIDEr score of VSLAN outperforms current off-the-shelf methods by $7.8\%$ on MSVD and $4.5\%$ on MSR-VTT, respectively. On the same datasets, VSLAN achieves competitive results in caption diversity metrics.
Human Activity Recognition from Wearable Sensor Data Using Self-Attention
Mar 17, 2020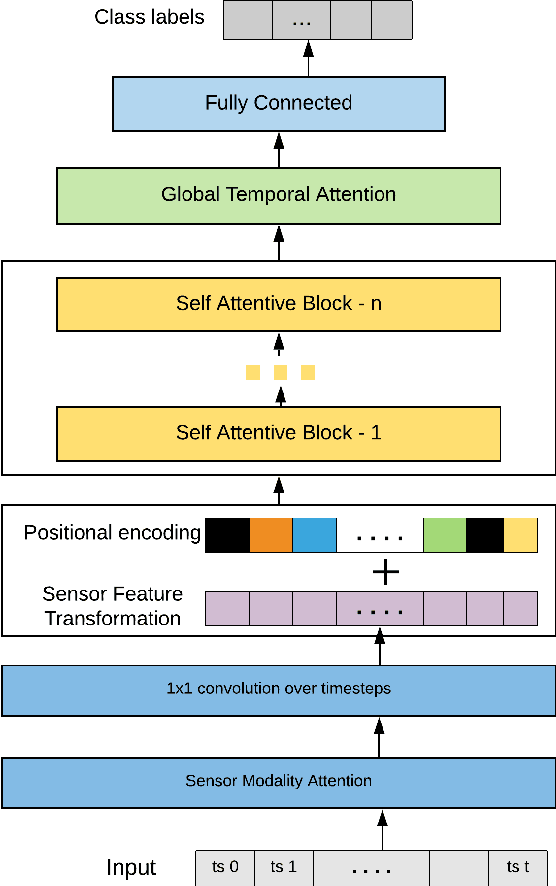
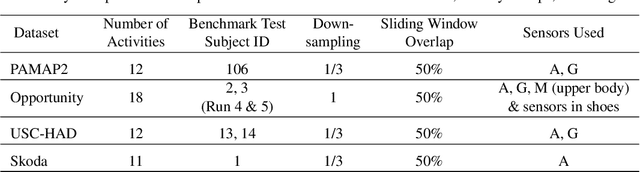
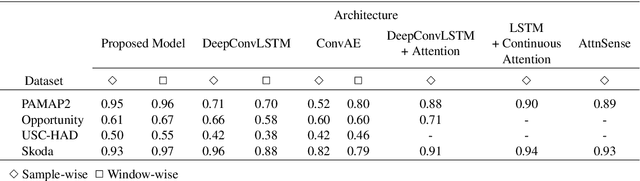
Human Activity Recognition from body-worn sensor data poses an inherent challenge in capturing spatial and temporal dependencies of time-series signals. In this regard, the existing recurrent or convolutional or their hybrid models for activity recognition struggle to capture spatio-temporal context from the feature space of sensor reading sequence. To address this complex problem, we propose a self-attention based neural network model that foregoes recurrent architectures and utilizes different types of attention mechanisms to generate higher dimensional feature representation used for classification. We performed extensive experiments on four popular publicly available HAR datasets: PAMAP2, Opportunity, Skoda and USC-HAD. Our model achieve significant performance improvement over recent state-of-the-art models in both benchmark test subjects and Leave-one-subject-out evaluation. We also observe that the sensor attention maps produced by our model is able capture the importance of the modality and placement of the sensors in predicting the different activity classes.