 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAPPA: Benchmarking Agents, Plans, and Pipelines for Automated Text-to-SQL Generation
Nov 06, 2025



Text-to-SQL systems provide a natural language interface that can enable even laymen to access information stored in databases. However, existing Large Language Models (LLM) struggle with SQL generation from natural instructions due to large schema sizes and complex reasoning. Prior work often focuses on complex, somewhat impractical pipelines using flagship models, while smaller, efficient models remain overlooked. In this work, we explore three multi-agent LLM pipelines, with systematic performance benchmarking across a range of small to large open-source models: (1) Multi-agent discussion pipeline, where agents iteratively critique and refine SQL queries, and a judge synthesizes the final answer; (2) Planner-Coder pipeline, where a thinking model planner generates stepwise SQL generation plans and a coder synthesizes queries; and (3) Coder-Aggregator pipeline, where multiple coders independently generate SQL queries, and a reasoning agent selects the best query. Experiments on the Bird-Bench Mini-Dev set reveal that Multi-Agent discussion can improve small model performance, with up to 10.6% increase in Execution Accuracy for Qwen2.5-7b-Instruct seen after three rounds of discussion. Among the pipelines, the LLM Reasoner-Coder pipeline yields the best results, with DeepSeek-R1-32B and QwQ-32B planners boosting Gemma 3 27B IT accuracy from 52.4% to the highest score of 56.4%. Codes are available at https://github.com/treeDweller98/bappa-sql.
BD Open LULC Map: High-resolution land use land cover mapping & benchmarking for urban development in Dhaka, Bangladesh
May 28, 2025Land Use Land Cover (LULC) mapping using deep learning significantly enhances the reliability of LULC classification, aiding in understanding geography, socioeconomic conditions, poverty levels, and urban sprawl. However, the scarcity of annotated satellite data, especially in South/East Asian developing countries, poses a major challenge due to limited funding, diverse infrastructures, and dense populations. In this work, we introduce the BD Open LULC Map (BOLM), providing pixel-wise LULC annotations across eleven classes (e.g., Farmland, Water, Forest, Urban Structure, Rural Built-Up) for Dhaka metropolitan city and its surroundings using high-resolution Bing satellite imagery (2.22 m/pixel). BOLM spans 4,392 sq km (891 million pixels), with ground truth validated through a three-stage process involving GIS experts. We benchmark LULC segmentation using DeepLab V3+ across five major classes and compare performance on Bing and Sentinel-2A imagery. BOLM aims to support reliable deep models and domain adaptation tasks, addressing critical LULC dataset gaps in South/East Asia.
RGC-Bent: A Novel Dataset for Bent Radio Galaxy Classification
May 25, 2025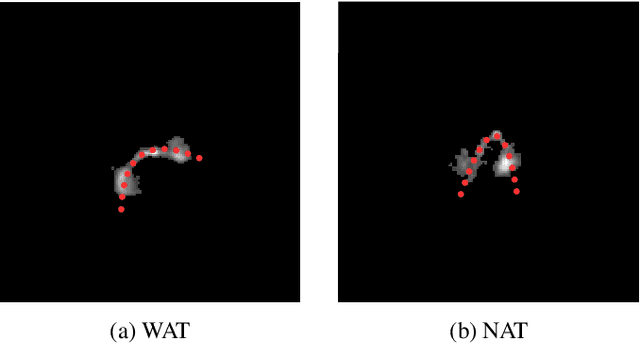
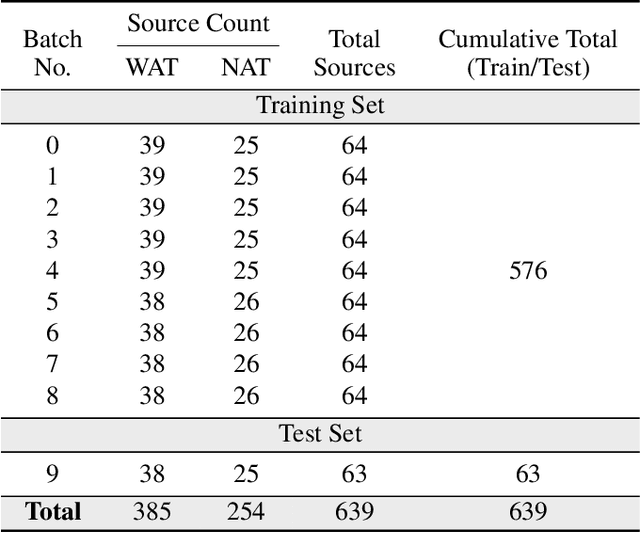

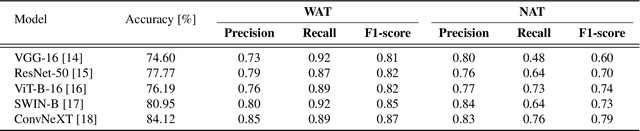
We introduce a novel machine learning dataset tailored for the classification of bent radio active galactic nuclei (AGN) in astronomical observations. Bent radio AGN, distinguished by their curved jet structures, provide critical insights into galaxy cluster dynamics, interactions within the intracluster medium, and the broader physics of AGN. Despite their astrophysical significance, the classification of bent radio AGN remains a challenge due to the scarcity of specialized datasets and benchmarks. To address this, we present a dataset, derived from a well-recognized radio astronomy survey, that is designed to support the classification of NAT (Narrow-Angle Tail) and WAT (Wide-Angle Tail) categories, along with detailed data processing steps. We further evaluate the performance of state-of-the-art deep learning models on the dataset, including Convolutional Neural Networks (CNNs), and transformer-based architectures. Our results demonstrate the effectiveness of advanced machine learning models in classifying bent radio AGN, with ConvNeXT achieving the highest F1-scores for both NAT and WAT sources. By sharing this dataset and benchmarks, we aim to facilitate the advancement of research in AGN classification, galaxy cluster environments and galaxy evolution.
FedCTTA: A Collaborative Approach to Continual Test-Time Adaptation in Federated Learning
May 19, 2025Federated Learning (FL) enables collaborative model training across distributed clients without sharing raw data, making it ideal for privacy-sensitive applications. However, FL models often suffer performance degradation due to distribution shifts between training and deployment. Test-Time Adaptation (TTA) offers a promising solution by allowing models to adapt using only test samples. However, existing TTA methods in FL face challenges such as computational overhead, privacy risks from feature sharing, and scalability concerns due to memory constraints. To address these limitations, we propose Federated Continual Test-Time Adaptation (FedCTTA), a privacy-preserving and computationally efficient framework for federated adaptation. Unlike prior methods that rely on sharing local feature statistics, FedCTTA avoids direct feature exchange by leveraging similarity-aware aggregation based on model output distributions over randomly generated noise samples. This approach ensures adaptive knowledge sharing while preserving data privacy. Furthermore, FedCTTA minimizes the entropy at each client for continual adaptation, enhancing the model's confidence in evolving target distributions. Our method eliminates the need for server-side training during adaptation and maintains a constant memory footprint, making it scalable even as the number of clients or training rounds increases. Extensive experiments show that FedCTTA surpasses existing methods across diverse temporal and spatial heterogeneity scenarios.
MIXAD: Memory-Induced Explainable Time Series Anomaly Detection
Oct 30, 2024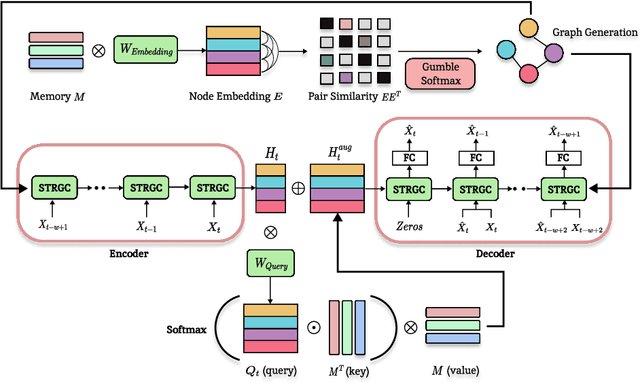


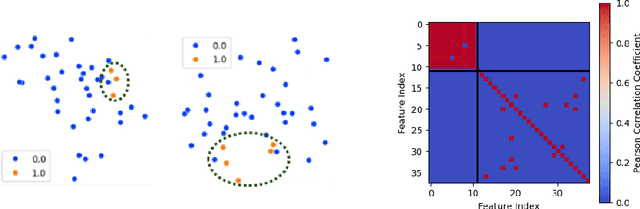
For modern industrial applications, accurately detecting and diagnosing anomalies in multivariate time series data is essential. Despite such need, most state-of-the-art methods often prioritize detection performance over model interpretability. Addressing this gap, we introduce MIXAD (Memory-Induced Explainable Time Series Anomaly Detection), a model designed for interpretable anomaly detection. MIXAD leverages a memory network alongside spatiotemporal processing units to understand the intricate dynamics and topological structures inherent in sensor relationships. We also introduce a novel anomaly scoring method that detects significant shifts in memory activation patterns during anomalies. Our approach not only ensures decent detection performance but also outperforms state-of-the-art baselines by 34.30% and 34.51% in interpretability metrics.
SSMT: Few-Shot Traffic Forecasting with Single Source Meta-Transfer
Oct 21, 2024
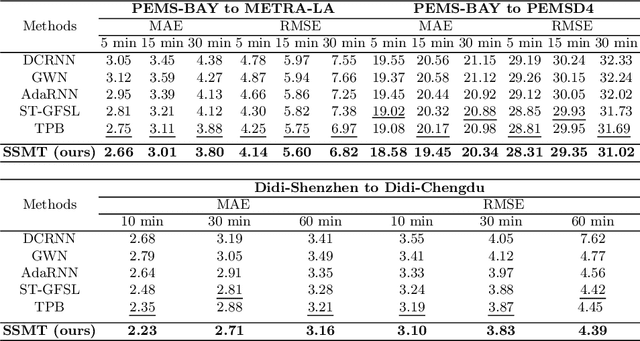
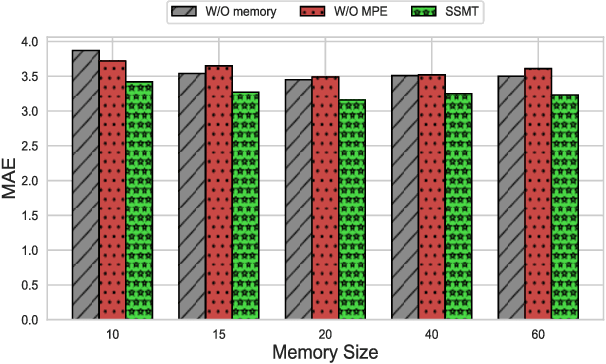

Traffic forecasting in Intelligent Transportation Systems (ITS) is vital for intelligent traffic prediction. Yet, ITS often relies on data from traffic sensors or vehicle devices, where certain cities might not have all those smart devices or enabling infrastructures. Also, recent studies have employed meta-learning to generalize spatial-temporal traffic networks, utilizing data from multiple cities for effective traffic forecasting for data-scarce target cities. However, collecting data from multiple cities can be costly and time-consuming. To tackle this challenge, we introduce Single Source Meta-Transfer Learning (SSMT) which relies only on a single source city for traffic prediction. Our method harnesses this transferred knowledge to enable few-shot traffic forecasting, particularly when the target city possesses limited data. Specifically, we use memory-augmented attention to store the heterogeneous spatial knowledge from the source city and selectively recall them for the data-scarce target city. We extend the idea of sinusoidal positional encoding to establish meta-learning tasks by leveraging diverse temporal traffic patterns from the source city. Moreover, to capture a more generalized representation of the positions we introduced a meta-positional encoding that learns the most optimal representation of the temporal pattern across all the tasks. We experiment on five real-world benchmark datasets to demonstrate that our method outperforms several existing methods in time series traffic prediction.
DM-Codec: Distilling Multimodal Representations for Speech Tokenization
Oct 19, 2024



Recent advancements in speech-language models have yielded significant improvements in speech tokenization and synthesis. However, effectively mapping the complex, multidimensional attributes of speech into discrete tokens remains challenging. This process demands acoustic, semantic, and contextual information for precise speech representations. Existing speech representations generally fall into two categories: acoustic tokens from audio codecs and semantic tokens from speech self-supervised learning models. Although recent efforts have unified acoustic and semantic tokens for improved performance, they overlook the crucial role of contextual representation in comprehensive speech modeling. Our empirical investigations reveal that the absence of contextual representations results in elevated Word Error Rate (WER) and Word Information Lost (WIL) scores in speech transcriptions. To address these limitations, we propose two novel distillation approaches: (1) a language model (LM)-guided distillation method that incorporates contextual information, and (2) a combined LM and self-supervised speech model (SM)-guided distillation technique that effectively distills multimodal representations (acoustic, semantic, and contextual) into a comprehensive speech tokenizer, termed DM-Codec. The DM-Codec architecture adopts a streamlined encoder-decoder framework with a Residual Vector Quantizer (RVQ) and incorporates the LM and SM during the training process. Experiments show DM-Codec significantly outperforms state-of-the-art speech tokenization models, reducing WER by up to 13.46%, WIL by 9.82%, and improving speech quality by 5.84% and intelligibility by 1.85% on the LibriSpeech benchmark dataset. The code, samples, and model checkpoints are available at https://github.com/mubtasimahasan/DM-Codec.
BD-SAT: High-resolution Land Use Land Cover Dataset & Benchmark Results for Developing Division: Dhaka, BD
Jun 09, 2024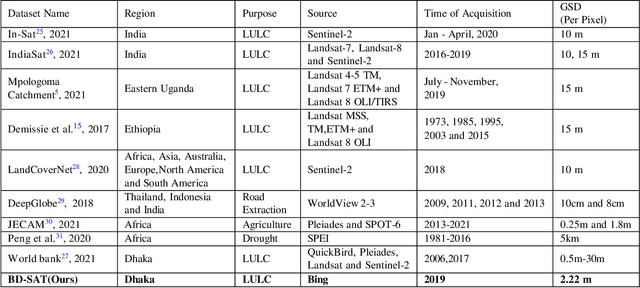

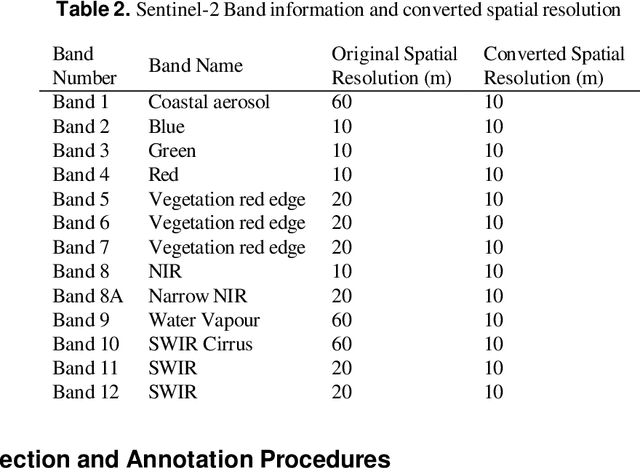

Land Use Land Cover (LULC) analysis on satellite images using deep learning-based methods is significantly helpful in understanding the geography, socio-economic conditions, poverty levels, and urban sprawl in developing countries. Recent works involve segmentation with LULC classes such as farmland, built-up areas, forests, meadows, water bodies, etc. Training deep learning methods on satellite images requires large sets of images annotated with LULC classes. However, annotated data for developing countries are scarce due to a lack of funding, absence of dedicated residential/industrial/economic zones, a large population, and diverse building materials. BD-SAT provides a high-resolution dataset that includes pixel-by-pixel LULC annotations for Dhaka metropolitan city and surrounding rural/urban areas. Using a strict and standardized procedure, the ground truth is created using Bing satellite imagery with a ground spatial distance of 2.22 meters per pixel. A three-stage, well-defined annotation process has been followed with support from GIS experts to ensure the reliability of the annotations. We performed several experiments to establish benchmark results. The results show that the annotated BD-SAT is sufficient to train large deep learning models with adequate accuracy for five major LULC classes: forest, farmland, built-up areas, water bodies, and meadows.
Morphological Classification of Radio Galaxies using Semi-Supervised Group Equivariant CNNs
May 31, 2023Out of the estimated few trillion galaxies, only around a million have been detected through radio frequencies, and only a tiny fraction, approximately a thousand, have been manually classified. We have addressed this disparity between labeled and unlabeled images of radio galaxies by employing a semi-supervised learning approach to classify them into the known Fanaroff-Riley Type I (FRI) and Type II (FRII) categories. A Group Equivariant Convolutional Neural Network (G-CNN) was used as an encoder of the state-of-the-art self-supervised methods SimCLR (A Simple Framework for Contrastive Learning of Visual Representations) and BYOL (Bootstrap Your Own Latent). The G-CNN preserves the equivariance for the Euclidean Group E(2), enabling it to effectively learn the representation of globally oriented feature maps. After representation learning, we trained a fully-connected classifier and fine-tuned the trained encoder with labeled data. Our findings demonstrate that our semi-supervised approach outperforms existing state-of-the-art methods across several metrics, including cluster quality, convergence rate, accuracy, precision, recall, and the F1-score. Moreover, statistical significance testing via a t-test revealed that our method surpasses the performance of a fully supervised G-CNN. This study emphasizes the importance of semi-supervised learning in radio galaxy classification, where labeled data are still scarce, but the prospects for discovery are immense.
Automatic Detection of Natural Disaster Effect on Paddy Field from Satellite Images using Deep Learning Techniques
Apr 02, 2023This paper aims to detect rice field damage from natural disasters in Bangladesh using high-resolution satellite imagery. The authors developed ground truth data for rice field damage from the field level. At first, NDVI differences before and after the disaster are calculated to identify possible crop loss. The areas equal to and above the 0.33 threshold are marked as crop loss areas as significant changes are observed. The authors also verified crop loss areas by collecting data from local farmers. Later, different bands of satellite data (Red, Green, Blue) and (False Color Infrared) are useful to detect crop loss area. We used the NDVI different images as ground truth to train the DeepLabV3plus model. With RGB, we got IoU 0.41 and with FCI, we got IoU 0.51. As FCI uses NIR, Red, Blue bands and NDVI is normalized difference between NIR and Red bands, so greater FCI's IoU score than RGB is expected. But RGB does not perform very badly here. So, where other bands are not available, RGB can use to understand crop loss areas to some extent. The ground truth developed in this paper can be used for segmentation models with very high resolution RGB only images such as Bing, Google etc.