 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoute, Retrieve, Reflect, Repair: Self-Improving Agentic Framework for Visual Detection and Linguistic Reasoning in Medical Imaging
Jan 13, 2026Medical image analysis increasingly relies on large vision-language models (VLMs), yet most systems remain single-pass black boxes that offer limited control over reasoning, safety, and spatial grounding. We propose R^4, an agentic framework that decomposes medical imaging workflows into four coordinated agents: a Router that configures task- and specialization-aware prompts from the image, patient history, and metadata; a Retriever that uses exemplar memory and pass@k sampling to jointly generate free-text reports and bounding boxes; a Reflector that critiques each draft-box pair for key clinical error modes (negation, laterality, unsupported claims, contradictions, missing findings, and localization errors); and a Repairer that iteratively revises both narrative and spatial outputs under targeted constraints while curating high-quality exemplars for future cases. Instantiated on chest X-ray analysis with multiple modern VLM backbones and evaluated on report generation and weakly supervised detection, R^4 consistently boosts LLM-as-a-Judge scores by roughly +1.7-+2.5 points and mAP50 by +2.5-+3.5 absolute points over strong single-VLM baselines, without any gradient-based fine-tuning. These results show that agentic routing, reflection, and repair can turn strong but brittle VLMs into more reliable and better grounded tools for clinical image interpretation. Our code can be found at: https://github.com/faiyazabdullah/MultimodalMedAgent
BD Open LULC Map: High-resolution land use land cover mapping & benchmarking for urban development in Dhaka, Bangladesh
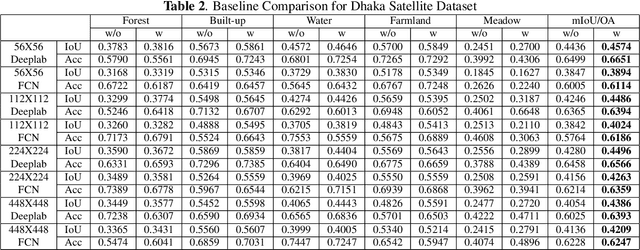
May 28, 2025Land Use Land Cover (LULC) mapping using deep learning significantly enhances the reliability of LULC classification, aiding in understanding geography, socioeconomic conditions, poverty levels, and urban sprawl. However, the scarcity of annotated satellite data, especially in South/East Asian developing countries, poses a major challenge due to limited funding, diverse infrastructures, and dense populations. In this work, we introduce the BD Open LULC Map (BOLM), providing pixel-wise LULC annotations across eleven classes (e.g., Farmland, Water, Forest, Urban Structure, Rural Built-Up) for Dhaka metropolitan city and its surroundings using high-resolution Bing satellite imagery (2.22 m/pixel). BOLM spans 4,392 sq km (891 million pixels), with ground truth validated through a three-stage process involving GIS experts. We benchmark LULC segmentation using DeepLab V3+ across five major classes and compare performance on Bing and Sentinel-2A imagery. BOLM aims to support reliable deep models and domain adaptation tasks, addressing critical LULC dataset gaps in South/East Asia.
RGC-Bent: A Novel Dataset for Bent Radio Galaxy Classification
May 25, 2025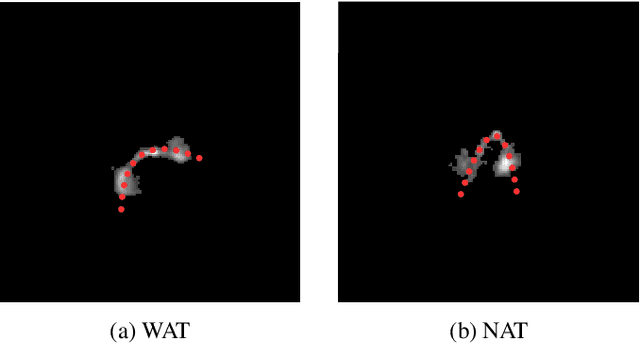
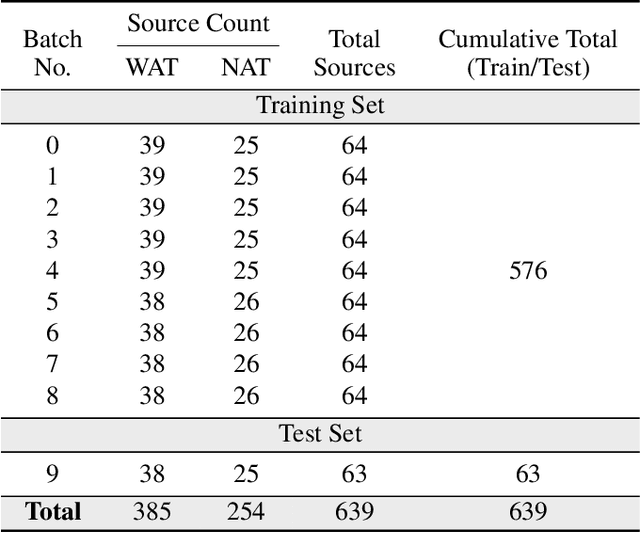

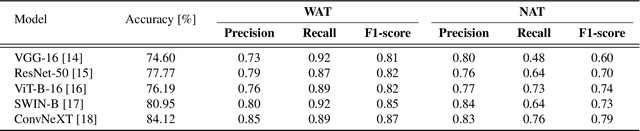
We introduce a novel machine learning dataset tailored for the classification of bent radio active galactic nuclei (AGN) in astronomical observations. Bent radio AGN, distinguished by their curved jet structures, provide critical insights into galaxy cluster dynamics, interactions within the intracluster medium, and the broader physics of AGN. Despite their astrophysical significance, the classification of bent radio AGN remains a challenge due to the scarcity of specialized datasets and benchmarks. To address this, we present a dataset, derived from a well-recognized radio astronomy survey, that is designed to support the classification of NAT (Narrow-Angle Tail) and WAT (Wide-Angle Tail) categories, along with detailed data processing steps. We further evaluate the performance of state-of-the-art deep learning models on the dataset, including Convolutional Neural Networks (CNNs), and transformer-based architectures. Our results demonstrate the effectiveness of advanced machine learning models in classifying bent radio AGN, with ConvNeXT achieving the highest F1-scores for both NAT and WAT sources. By sharing this dataset and benchmarks, we aim to facilitate the advancement of research in AGN classification, galaxy cluster environments and galaxy evolution.
BD-SAT: High-resolution Land Use Land Cover Dataset & Benchmark Results for Developing Division: Dhaka, BD
Jun 09, 2024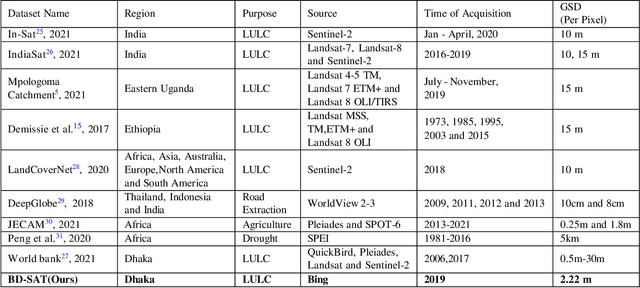

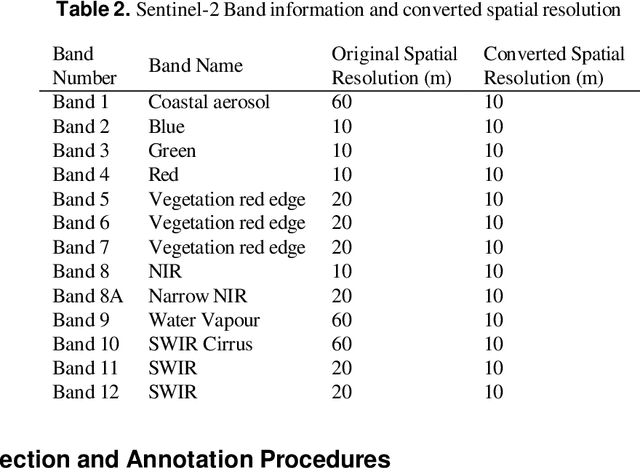

Land Use Land Cover (LULC) analysis on satellite images using deep learning-based methods is significantly helpful in understanding the geography, socio-economic conditions, poverty levels, and urban sprawl in developing countries. Recent works involve segmentation with LULC classes such as farmland, built-up areas, forests, meadows, water bodies, etc. Training deep learning methods on satellite images requires large sets of images annotated with LULC classes. However, annotated data for developing countries are scarce due to a lack of funding, absence of dedicated residential/industrial/economic zones, a large population, and diverse building materials. BD-SAT provides a high-resolution dataset that includes pixel-by-pixel LULC annotations for Dhaka metropolitan city and surrounding rural/urban areas. Using a strict and standardized procedure, the ground truth is created using Bing satellite imagery with a ground spatial distance of 2.22 meters per pixel. A three-stage, well-defined annotation process has been followed with support from GIS experts to ensure the reliability of the annotations. We performed several experiments to establish benchmark results. The results show that the annotated BD-SAT is sufficient to train large deep learning models with adequate accuracy for five major LULC classes: forest, farmland, built-up areas, water bodies, and meadows.
Deep Dive into Semi-Supervised ELBO for Improving Classification Performance
Aug 29, 2021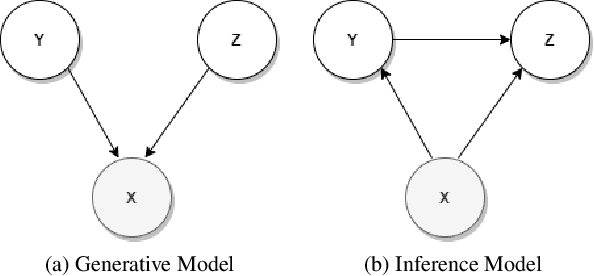
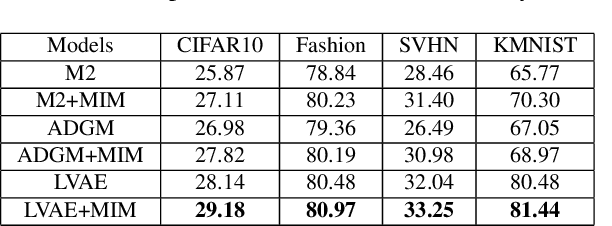
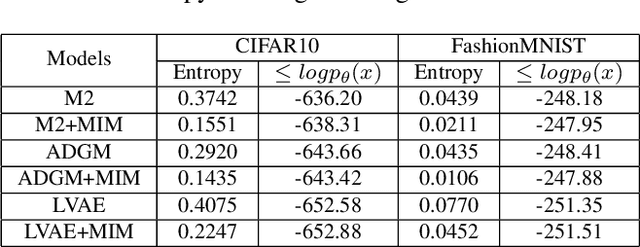
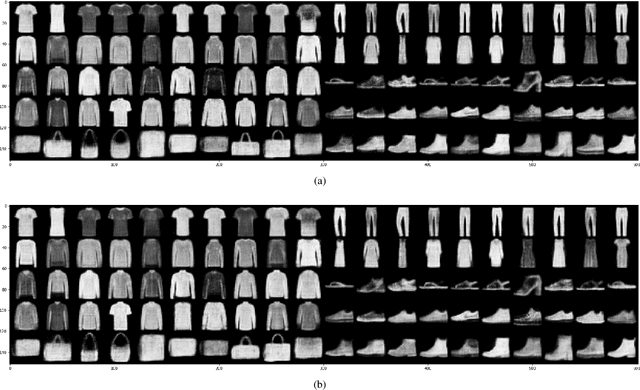
Decomposition of the evidence lower bound (ELBO) objective of VAE used for density estimation revealed the deficiency of VAE for representation learning and suggested ways to improve the model. In this paper, we investigate whether we can get similar insights by decomposing the ELBO for semi-supervised classification using VAE model. Specifically, we show that mutual information between input and class labels decreases during maximization of ELBO objective. We propose a method to address this issue. We also enforce cluster assumption to aid in classification. Experiments on a diverse datasets verify that our method can be used to improve the classification performance of existing VAE based semi-supervised models. Experiments also show that, this can be achieved without sacrificing the generative power of the model.
A Novel Disaster Image Dataset and Characteristics Analysis using Attention Model
Jul 02, 2021
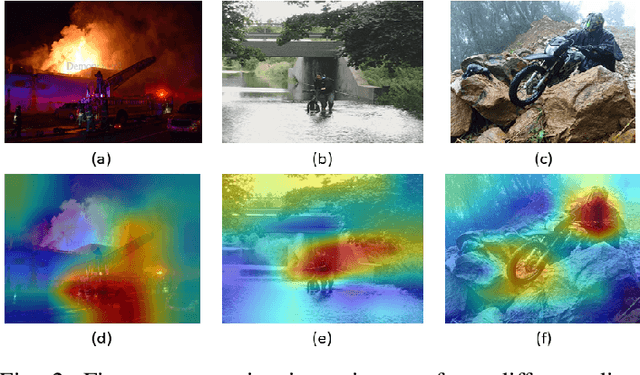

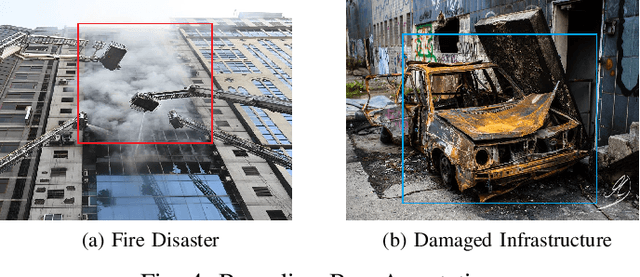
The advancement of deep learning technology has enabled us to develop systems that outperform any other classification technique. However, success of any empirical system depends on the quality and diversity of the data available to train the proposed system. In this research, we have carefully accumulated a relatively challenging dataset that contains images collected from various sources for three different disasters: fire, water and land. Besides this, we have also collected images for various damaged infrastructure due to natural or man made calamities and damaged human due to war or accidents. We have also accumulated image data for a class named non-damage that contains images with no such disaster or sign of damage in them. There are 13,720 manually annotated images in this dataset, each image is annotated by three individuals. We are also providing discriminating image class information annotated manually with bounding box for a set of 200 test images. Images are collected from different news portals, social media, and standard datasets made available by other researchers. A three layer attention model (TLAM) is trained and average five fold validation accuracy of 95.88% is achieved. Moreover, on the 200 unseen test images this accuracy is 96.48%. We also generate and compare attention maps for these test images to determine the characteristics of the trained attention model. Our dataset is available at https://niloy193.github.io/Disaster-Dataset
Attention Toward Neighbors: A Context Aware Framework for High Resolution Image Segmentation
Jun 24, 2021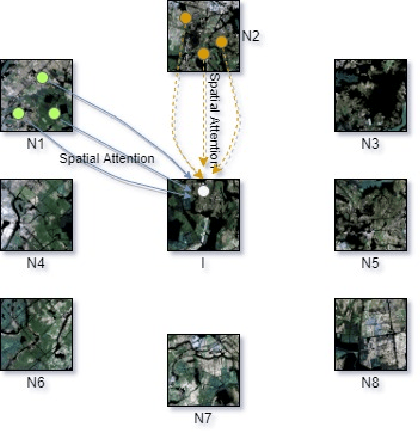
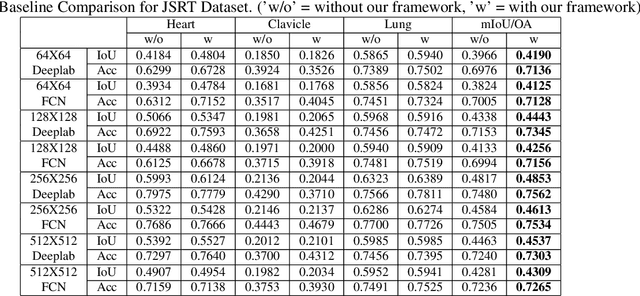
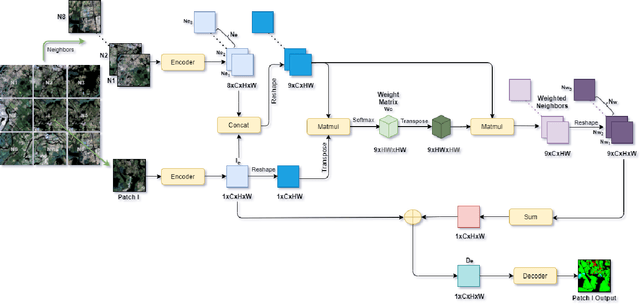
High-resolution image segmentation remains challenging and error-prone due to the enormous size of intermediate feature maps. Conventional methods avoid this problem by using patch based approaches where each patch is segmented independently. However, independent patch segmentation induces errors, particularly at the patch boundary due to the lack of contextual information in very high-resolution images where the patch size is much smaller compared to the full image. To overcome these limitations, in this paper, we propose a novel framework to segment a particular patch by incorporating contextual information from its neighboring patches. This allows the segmentation network to see the target patch with a wider field of view without the need of larger feature maps. Comparative analysis from a number of experiments shows that our proposed framework is able to segment high resolution images with significantly improved mean Intersection over Union and overall accuracy.
Deep-learning coupled with novel classification method to classify the urban environment of the developing world
Nov 25, 2020
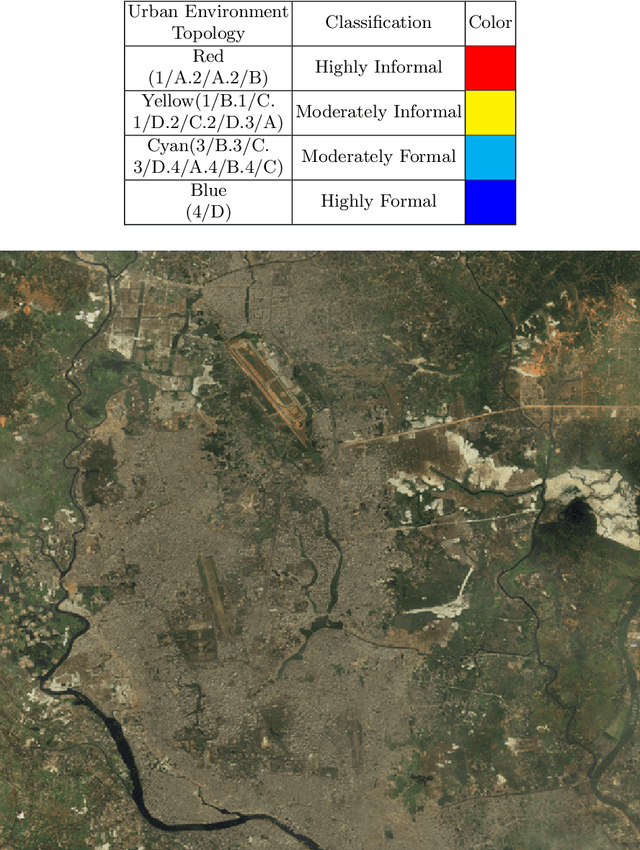
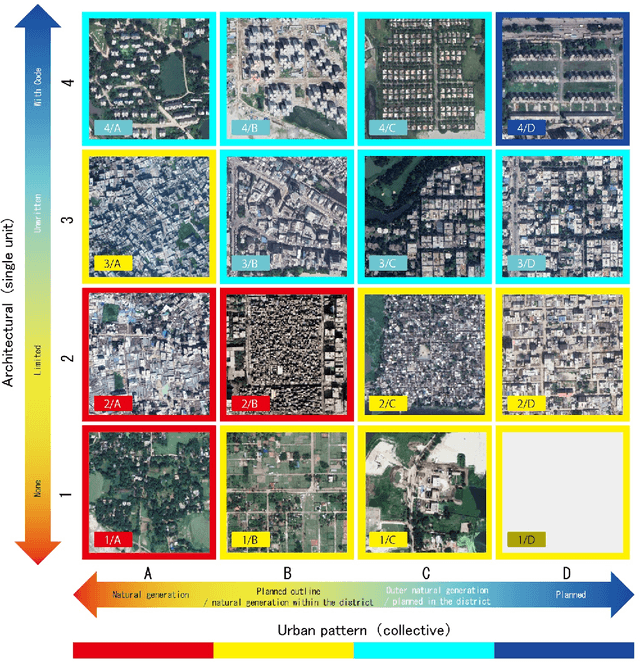
Rapid globalization and the interdependence of humanity that engender tremendous in-flow of human migration towards the urban spaces. With advent of high definition satellite images, high resolution data, computational methods such as deep neural network, capable hardware; urban planning is seeing a paradigm shift. Legacy data on urban environments are now being complemented with high-volume, high-frequency data. In this paper we propose a novel classification method that is readily usable for machine analysis and show applicability of the methodology on a developing world setting. The state-of-the-art is mostly dominated by classification of building structures, building types etc. and largely represents the developed world which are insufficient for developing countries such as Bangladesh where the surrounding is crucial for the classification. Moreover, the traditional methods propose small-scale classifications, which give limited information with poor scalability and are slow to compute. We categorize the urban area in terms of informal and formal spaces taking the surroundings into account. 50 km x 50 km Google Earth image of Dhaka, Bangladesh was visually annotated and categorized by an expert. The classification is based broadly on two dimensions: urbanization and the architectural form of urban environment. Consequently, the urban space is divided into four classes: 1) highly informal; 2) moderately informal; 3) moderately formal; and 4) highly formal areas. In total 16 sub-classes were identified. For semantic segmentation, Google's DeeplabV3+ model was used which increases the field of view of the filters to incorporate larger context. Image encompassing 70% of the urban space was used for training and the remaining 30% was used for testing and validation. The model is able to segment with 75% accuracy and 60% Mean IoU.
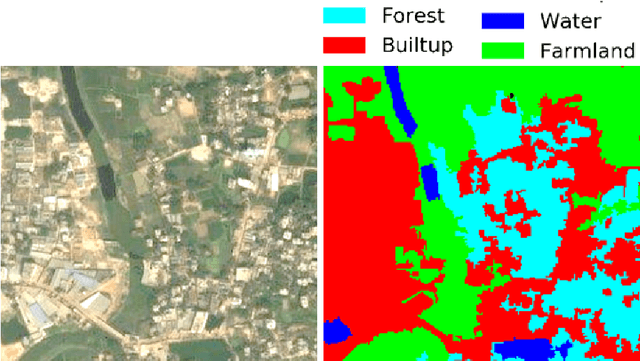
LULC Segmentation of RGB Satellite Image Using FCN-8
Aug 24, 2020


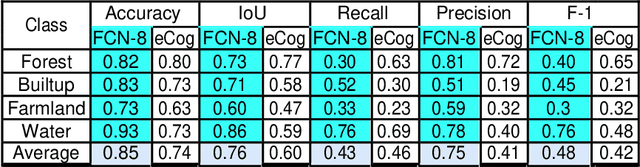
This work presents use of Fully Convolutional Network (FCN-8) for semantic segmentation of high-resolution RGB earth surface satel-lite images into land use land cover (LULC) categories. Specically, we propose a non-overlapping grid-based approach to train a Fully Convo-lutional Network (FCN-8) with vgg-16 weights to segment satellite im-ages into four (forest, built-up, farmland and water) classes. The FCN-8 semantically projects the discriminating features in lower resolution learned by the encoder onto the pixel space in higher resolution to get a dense classi cation. We experimented the proposed system with Gaofen-2 image dataset, that contains 150 images of over 60 di erent cities in china. For comparison, we used available ground-truth along with images segmented using a widely used commeriial GIS software called eCogni-tion. With the proposed non-overlapping grid-based approach, FCN-8 obtains signi cantly improved performance, than the eCognition soft-ware. Our model achieves average accuracy of 91.0% and average Inter-section over Union (IoU) of 0.84. In contrast, eCognitions average accu-racy is 74.0% and IoU is 0.60. This paper also reports a detail analysis of errors occurred at the LULC boundary.