 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajGPT-R: Generating Urban Mobility Trajectory with Reinforcement Learning-Enhanced Generative Pre-trained Transformer
Feb 24, 2026Mobility trajectories are essential for understanding urban dynamics and enhancing urban planning, yet access to such data is frequently hindered by privacy concerns. This research introduces a transformative framework for generating large-scale urban mobility trajectories, employing a novel application of a transformer-based model pre-trained and fine-tuned through a two-phase process. Initially, trajectory generation is conceptualized as an offline reinforcement learning (RL) problem, with a significant reduction in vocabulary space achieved during tokenization. The integration of Inverse Reinforcement Learning (IRL) allows for the capture of trajectory-wise reward signals, leveraging historical data to infer individual mobility preferences. Subsequently, the pre-trained model is fine-tuned using the constructed reward model, effectively addressing the challenges inherent in traditional RL-based autoregressive methods, such as long-term credit assignment and handling of sparse reward environments. Comprehensive evaluations on multiple datasets illustrate that our framework markedly surpasses existing models in terms of reliability and diversity. Our findings not only advance the field of urban mobility modeling but also provide a robust methodology for simulating urban data, with significant implications for traffic management and urban development planning. The implementation is publicly available at https://github.com/Wangjw6/TrajGPT_R.
Manifold-Aware Temporal Domain Generalization for Large Language Models
Feb 12, 2026Temporal distribution shifts are pervasive in real-world deployments of Large Language Models (LLMs), where data evolves continuously over time. While Temporal Domain Generalization (TDG) seeks to model such structured evolution, existing approaches characterize model adaptation in the full parameter space. This formulation becomes computationally infeasible for modern LLMs. This paper introduces a geometric reformulation of TDG under parameter-efficient fine-tuning. We establish that the low-dimensional temporal structure underlying model evolution can be preserved under parameter-efficient reparameterization, enabling temporal modeling without operating in the ambient parameter space. Building on this principle, we propose Manifold-aware Temporal LoRA (MaT-LoRA), which constrains temporal updates to a shared low-dimensional manifold within a low-rank adaptation subspace, and models its evolution through a structured temporal core. This reparameterization dramatically reduces temporal modeling complexity while retaining expressive power. Extensive experiments on synthetic and real-world datasets, including scientific documents, news publishers, and review ratings, demonstrate that MaT-LoRA achieves superior temporal generalization performance with practical scalability for LLMs.
Blurred Encoding for Trajectory Representation Learning
Nov 12, 2025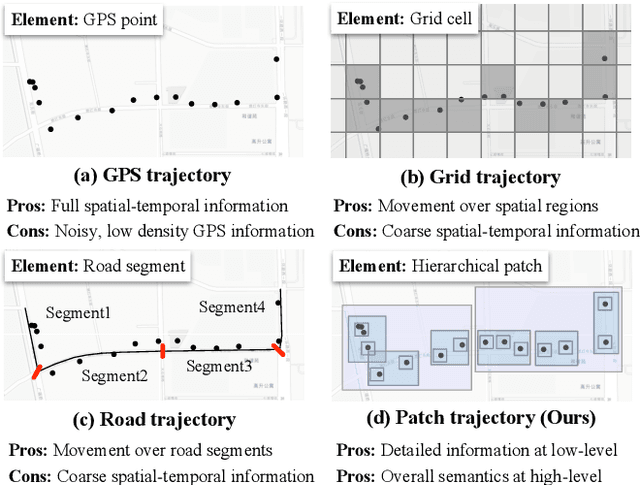

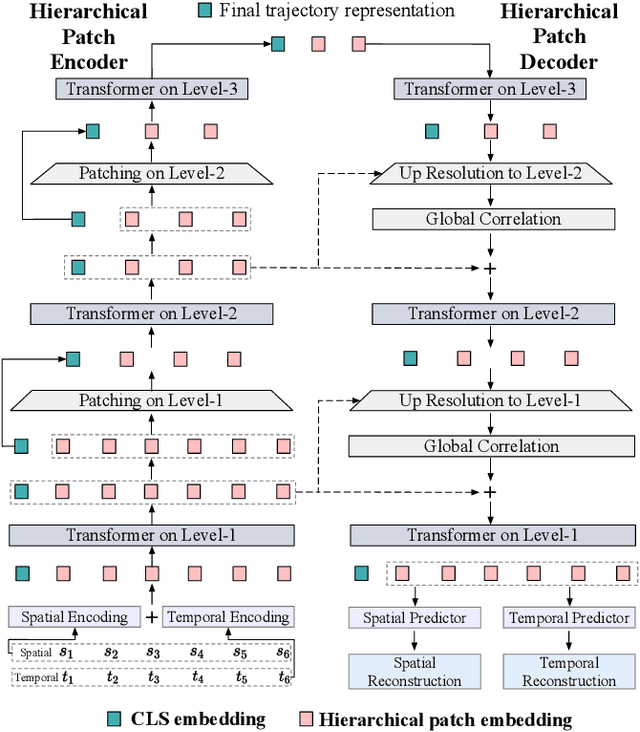
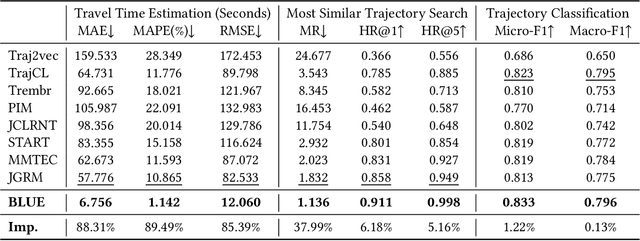
Trajectory representation learning (TRL) maps trajectories to vector embeddings and facilitates tasks such as trajectory classification and similarity search. State-of-the-art (SOTA) TRL methods transform raw GPS trajectories to grid or road trajectories to capture high-level travel semantics, i.e., regions and roads. However, they lose fine-grained spatial-temporal details as multiple GPS points are grouped into a single grid cell or road segment. To tackle this problem, we propose the BLUrred Encoding method, dubbed BLUE, which gradually reduces the precision of GPS coordinates to create hierarchical patches with multiple levels. The low-level patches are small and preserve fine-grained spatial-temporal details, while the high-level patches are large and capture overall travel patterns. To complement different patch levels with each other, our BLUE is an encoder-decoder model with a pyramid structure. At each patch level, a Transformer is used to learn the trajectory embedding at the current level, while pooling prepares inputs for the higher level in the encoder, and up-resolution provides guidance for the lower level in the decoder. BLUE is trained using the trajectory reconstruction task with the MSE loss. We compare BLUE with 8 SOTA TRL methods for 3 downstream tasks, the results show that BLUE consistently achieves higher accuracy than all baselines, outperforming the best-performing baselines by an average of 30.90%. Our code is available at https://github.com/slzhou-xy/BLUE.
CausalMob: Causal Human Mobility Prediction with LLMs-derived Human Intentions toward Public Events
Dec 03, 2024
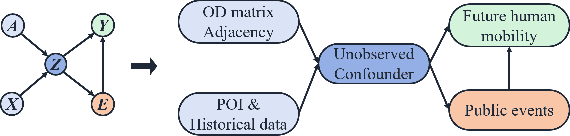
Large-scale human mobility exhibits spatial and temporal patterns that can assist policymakers in decision making. Although traditional prediction models attempt to capture these patterns, they often interfered by non-periodic public events, such as disasters and occasional celebrations. Since regular human mobility patterns are heavily affected by these events, estimating their causal effects is critical to accurate mobility predictions. Although news articles provide unique perspectives on these events in an unstructured format, processing is a challenge. In this study, we propose a causality-augmented prediction model, called \textbf{CausalMob}, to analyze the causal effects of public events. We first utilize large language models (LLMs) to extract human intentions from news articles and transform them into features that act as causal treatments. Next, the model learns representations of spatio-temporal regional covariates from multiple data sources to serve as confounders for causal inference. Finally, we present a causal effect estimation framework to ensure event features remain independent of confounders during prediction. Based on large-scale real-world data, the experimental results show that the proposed model excels in human mobility prediction, outperforming state-of-the-art models.
Large Language Models as Urban Residents: An LLM Agent Framework for Personal Mobility Generation
Feb 22, 2024This paper introduces a novel approach using Large Language Models (LLMs) integrated into an agent framework for flexible and efficient personal mobility generation. LLMs overcome the limitations of previous models by efficiently processing semantic data and offering versatility in modeling various tasks. Our approach addresses the critical need to align LLMs with real-world urban mobility data, focusing on three research questions: aligning LLMs with rich activity data, developing reliable activity generation strategies, and exploring LLM applications in urban mobility. The key technical contribution is a novel LLM agent framework that accounts for individual activity patterns and motivations, including a self-consistency approach to align LLMs with real-world activity data and a retrieval-augmented strategy for interpretable activity generation. In experimental studies, comprehensive validation is performed using real-world data. This research marks the pioneering work of designing an LLM agent framework for activity generation based on real-world human activity data, offering a promising tool for urban mobility analysis.
MemDA: Forecasting Urban Time Series with Memory-based Drift Adaptation
Sep 25, 2023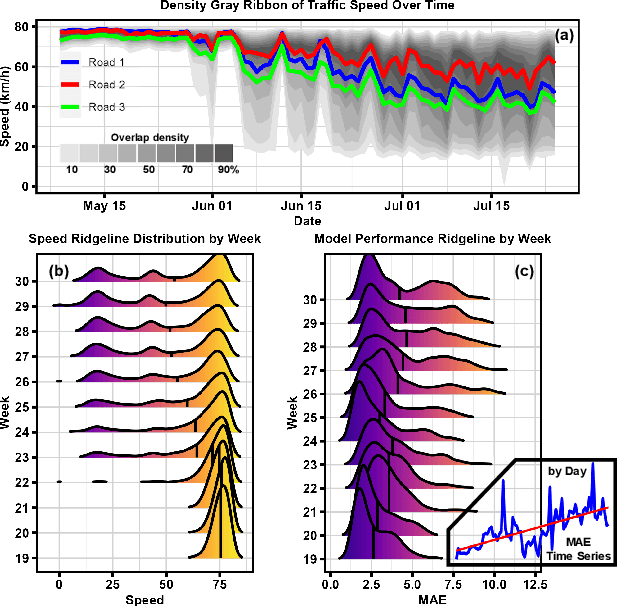



Urban time series data forecasting featuring significant contributions to sustainable development is widely studied as an essential task of the smart city. However, with the dramatic and rapid changes in the world environment, the assumption that data obey Independent Identically Distribution is undermined by the subsequent changes in data distribution, known as concept drift, leading to weak replicability and transferability of the model over unseen data. To address the issue, previous approaches typically retrain the model, forcing it to fit the most recent observed data. However, retraining is problematic in that it leads to model lag, consumption of resources, and model re-invalidation, causing the drift problem to be not well solved in realistic scenarios. In this study, we propose a new urban time series prediction model for the concept drift problem, which encodes the drift by considering the periodicity in the data and makes on-the-fly adjustments to the model based on the drift using a meta-dynamic network. Experiments on real-world datasets show that our design significantly outperforms state-of-the-art methods and can be well generalized to existing prediction backbones by reducing their sensitivity to distribution changes.
Hybrid Feature Embedding For Automatic Building Outline Extraction
Jul 20, 2023
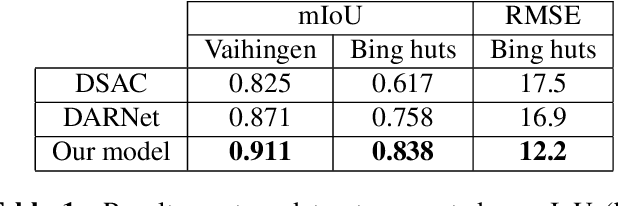

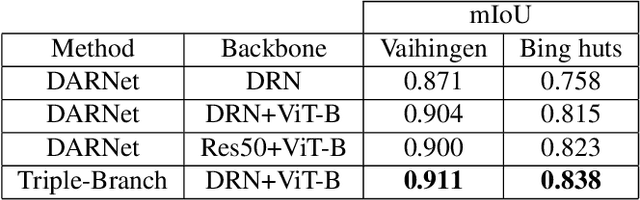
Building outline extracted from high-resolution aerial images can be used in various application fields such as change detection and disaster assessment. However, traditional CNN model cannot recognize contours very precisely from original images. In this paper, we proposed a CNN and Transformer based model together with active contour model to deal with this problem. We also designed a triple-branch decoder structure to handle different features generated by encoder. Experiment results show that our model outperforms other baseline model on two datasets, achieving 91.1% mIoU on Vaihingen and 83.8% on Bing huts.
Enhancing Building Semantic Segmentation Accuracy with Super Resolution and Deep Learning: Investigating the Impact of Spatial Resolution on Various Datasets
Jul 09, 2023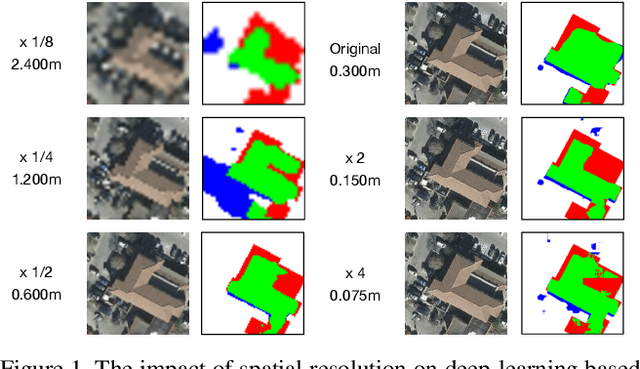
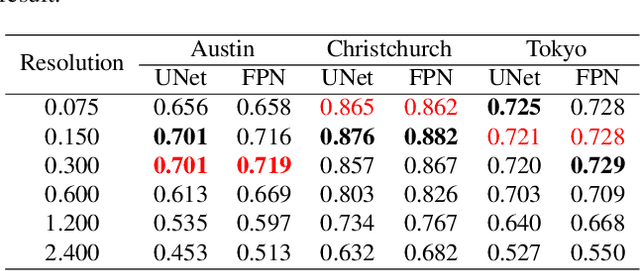

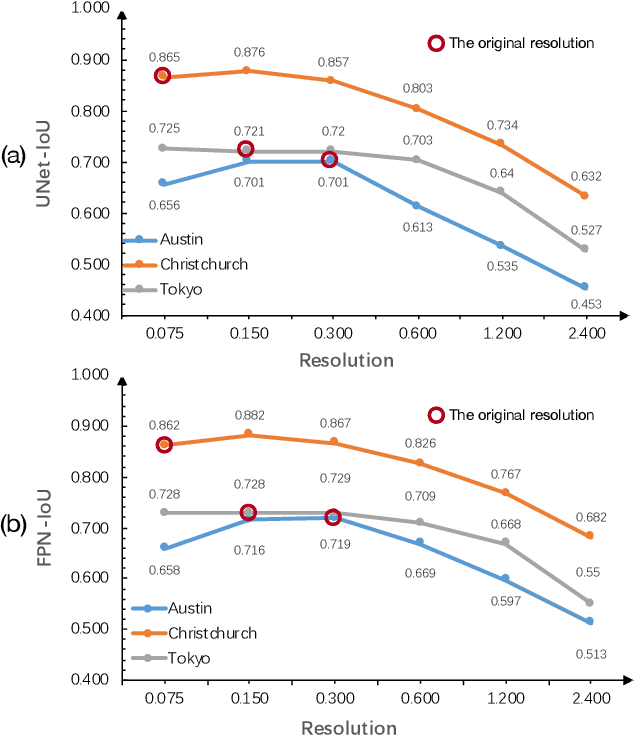
The development of remote sensing and deep learning techniques has enabled building semantic segmentation with high accuracy and efficiency. Despite their success in different tasks, the discussions on the impact of spatial resolution on deep learning based building semantic segmentation are quite inadequate, which makes choosing a higher cost-effective data source a big challenge. To address the issue mentioned above, in this study, we create remote sensing images among three study areas into multiple spatial resolutions by super-resolution and down-sampling. After that, two representative deep learning architectures: UNet and FPN, are selected for model training and testing. The experimental results obtained from three cities with two deep learning models indicate that the spatial resolution greatly influences building segmentation results, and with a better cost-effectiveness around 0.3m, which we believe will be an important insight for data selection and preparation.
Real-World Video for Zoom Enhancement based on Spatio-Temporal Coupling
Jun 24, 2023



In recent years, single-frame image super-resolution (SR) has become more realistic by considering the zooming effect and using real-world short- and long-focus image pairs. In this paper, we further investigate the feasibility of applying realistic multi-frame clips to enhance zoom quality via spatio-temporal information coupling. Specifically, we first built a real-world video benchmark, VideoRAW, by a synchronized co-axis optical system. The dataset contains paired short-focus raw and long-focus sRGB videos of different dynamic scenes. Based on VideoRAW, we then presented a Spatio-Temporal Coupling Loss, termed as STCL. The proposed STCL is intended for better utilization of information from paired and adjacent frames to align and fuse features both temporally and spatially at the feature level. The outperformed experimental results obtained in different zoom scenarios demonstrate the superiority of integrating real-world video dataset and STCL into existing SR models for zoom quality enhancement, and reveal that the proposed method can serve as an advanced and viable tool for video zoom.
Multitask Weakly Supervised Learning for Origin Destination Travel Time Estimation
Jan 13, 2023



Travel time estimation from GPS trips is of great importance to order duration, ridesharing, taxi dispatching, etc. However, the dense trajectory is not always available due to the limitation of data privacy and acquisition, while the origin destination (OD) type of data, such as NYC taxi data, NYC bike data, and Capital Bikeshare data, is more accessible. To address this issue, this paper starts to estimate the OD trips travel time combined with the road network. Subsequently, a Multitask Weakly Supervised Learning Framework for Travel Time Estimation (MWSL TTE) has been proposed to infer transition probability between roads segments, and the travel time on road segments and intersection simultaneously. Technically, given an OD pair, the transition probability intends to recover the most possible route. And then, the output of travel time is equal to the summation of all segments' and intersections' travel time in this route. A novel route recovery function has been proposed to iteratively maximize the current route's co occurrence probability, and minimize the discrepancy between routes' probability distribution and the inverse distribution of routes' estimation loss. Moreover, the expected log likelihood function based on a weakly supervised framework has been deployed in optimizing the travel time from road segments and intersections concurrently. We conduct experiments on a wide range of real world taxi datasets in Xi'an and Chengdu and demonstrate our method's effectiveness on route recovery and travel time estimation.