 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmoQ: Harmonized Post-Training Quantization for High-Fidelity Image
Nov 11, 2025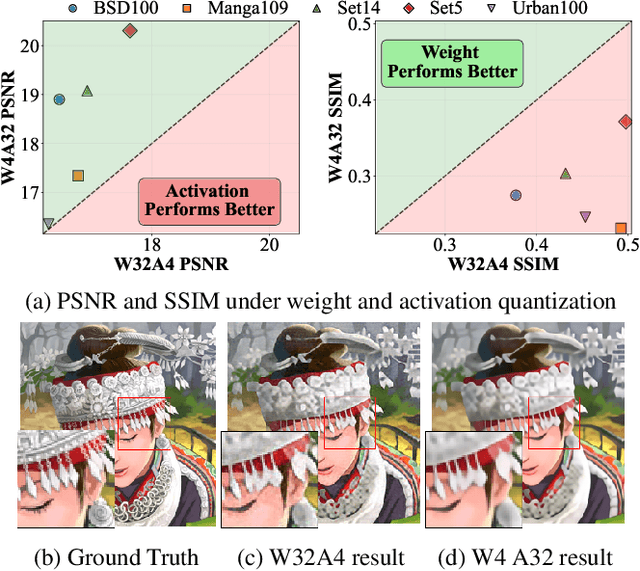
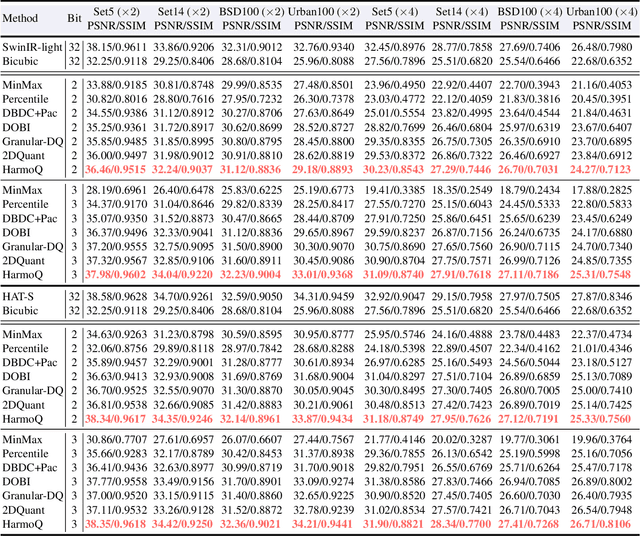
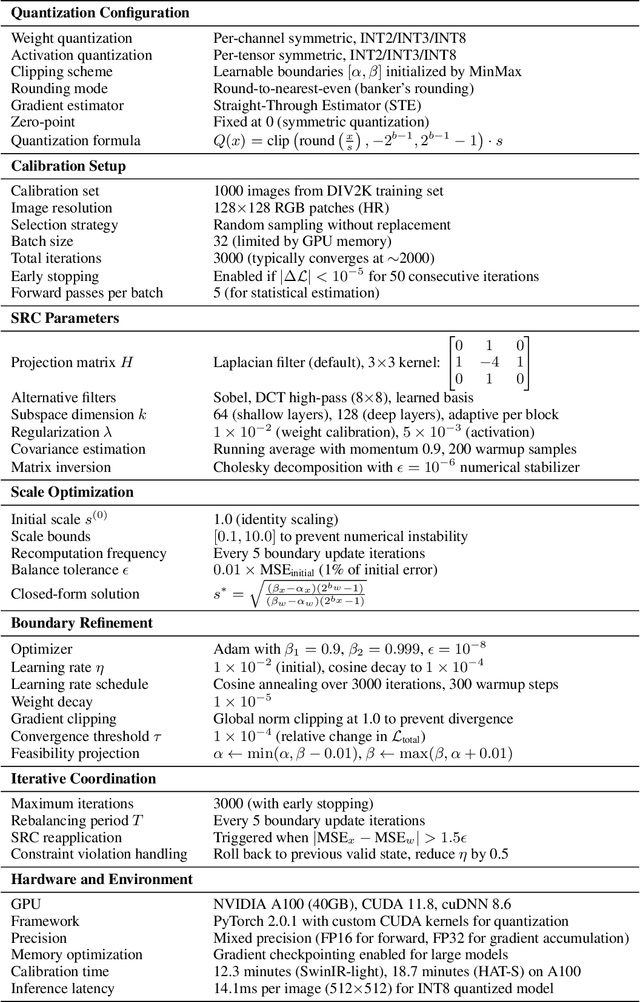
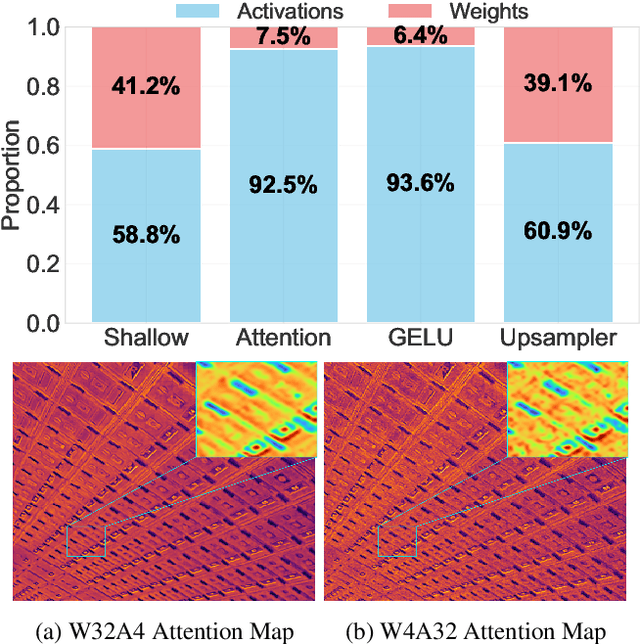
Post-training quantization offers an efficient pathway to deploy super-resolution models, yet existing methods treat weight and activation quantization independently, missing their critical interplay. Through controlled experiments on SwinIR, we uncover a striking asymmetry: weight quantization primarily degrades structural similarity, while activation quantization disproportionately affects pixel-level accuracy. This stems from their distinct roles--weights encode learned restoration priors for textures and edges, whereas activations carry input-specific intensity information. Building on this insight, we propose HarmoQ, a unified framework that harmonizes quantization across components through three synergistic steps: structural residual calibration proactively adjusts weights to compensate for activation-induced detail loss, harmonized scale optimization analytically balances quantization difficulty via closed-form solutions, and adaptive boundary refinement iteratively maintains this balance during optimization. Experiments show HarmoQ achieves substantial gains under aggressive compression, outperforming prior art by 0.46 dB on Set5 at 2-bit while delivering 3.2x speedup and 4x memory reduction on A100 GPUs. This work provides the first systematic analysis of weight-activation coupling in super-resolution quantization and establishes a principled solution for efficient high-quality image restoration.
Resilience Inference for Supply Chains with Hypergraph Neural Network
Nov 09, 2025Supply chains are integral to global economic stability, yet disruptions can swiftly propagate through interconnected networks, resulting in substantial economic impacts. Accurate and timely inference of supply chain resilience the capability to maintain core functions during disruptions is crucial for proactive risk mitigation and robust network design. However, existing approaches lack effective mechanisms to infer supply chain resilience without explicit system dynamics and struggle to represent the higher-order, multi-entity dependencies inherent in supply chain networks. These limitations motivate the definition of a novel problem and the development of targeted modeling solutions. To address these challenges, we formalize a novel problem: Supply Chain Resilience Inference (SCRI), defined as predicting supply chain resilience using hypergraph topology and observed inventory trajectories without explicit dynamic equations. To solve this problem, we propose the Supply Chain Resilience Inference Hypergraph Network (SC-RIHN), a novel hypergraph-based model leveraging set-based encoding and hypergraph message passing to capture multi-party firm-product interactions. Comprehensive experiments demonstrate that SC-RIHN significantly outperforms traditional MLP, representative graph neural network variants, and ResInf baselines across synthetic benchmarks, underscoring its potential for practical, early-warning risk assessment in complex supply chain systems.
Not All Degradations Are Equal: A Targeted Feature Denoising Framework for Generalizable Image Super-Resolution
Sep 18, 2025Generalizable Image Super-Resolution aims to enhance model generalization capabilities under unknown degradations. To achieve this goal, the models are expected to focus only on image content-related features instead of overfitting degradations. Recently, numerous approaches such as Dropout and Feature Alignment have been proposed to suppress models' natural tendency to overfit degradations and yield promising results. Nevertheless, these works have assumed that models overfit to all degradation types (e.g., blur, noise, JPEG), while through careful investigations in this paper, we discover that models predominantly overfit to noise, largely attributable to its distinct degradation pattern compared to other degradation types. In this paper, we propose a targeted feature denoising framework, comprising noise detection and denoising modules. Our approach presents a general solution that can be seamlessly integrated with existing super-resolution models without requiring architectural modifications. Our framework demonstrates superior performance compared to previous regularization-based methods across five traditional benchmarks and datasets, encompassing both synthetic and real-world scenarios.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Unveiling the Inflexibility of Adaptive Embedding in Traffic Forecasting
Nov 18, 2024



Spatiotemporal Graph Neural Networks (ST-GNNs) and Transformers have shown significant promise in traffic forecasting by effectively modeling temporal and spatial correlations. However, rapid urbanization in recent years has led to dynamic shifts in traffic patterns and travel demand, posing major challenges for accurate long-term traffic prediction. The generalization capability of ST-GNNs in extended temporal scenarios and cross-city applications remains largely unexplored. In this study, we evaluate state-of-the-art models on an extended traffic benchmark and observe substantial performance degradation in existing ST-GNNs over time, which we attribute to their limited inductive capabilities. Our analysis reveals that this degradation stems from an inability to adapt to evolving spatial relationships within urban environments. To address this limitation, we reconsider the design of adaptive embeddings and propose a Principal Component Analysis (PCA) embedding approach that enables models to adapt to new scenarios without retraining. We incorporate PCA embeddings into existing ST-GNN and Transformer architectures, achieving marked improvements in performance. Notably, PCA embeddings allow for flexibility in graph structures between training and testing, enabling models trained on one city to perform zero-shot predictions on other cities. This adaptability demonstrates the potential of PCA embeddings in enhancing the robustness and generalization of spatiotemporal models.
Learning to Balance: Diverse Normalization for Cloth-Changing Person Re-Identification
Oct 14, 2024


Cloth-Changing Person Re-Identification (CC-ReID) involves recognizing individuals in images regardless of clothing status. In this paper, we empirically and experimentally demonstrate that completely eliminating or fully retaining clothing features is detrimental to the task. Existing work, either relying on clothing labels, silhouettes, or other auxiliary data, fundamentally aim to balance the learning of clothing and identity features. However, we practically find that achieving this balance is challenging and nuanced. In this study, we introduce a novel module called Diverse Norm, which expands personal features into orthogonal spaces and employs channel attention to separate clothing and identity features. A sample re-weighting optimization strategy is also introduced to guarantee the opposite optimization direction. Diverse Norm presents a simple yet effective approach that does not require additional data. Furthermore, Diverse Norm can be seamlessly integrated ResNet50 and significantly outperforms the state-of-the-art methods.
On Feature Decorrelation in Cloth-Changing Person Re-identification
Oct 07, 2024
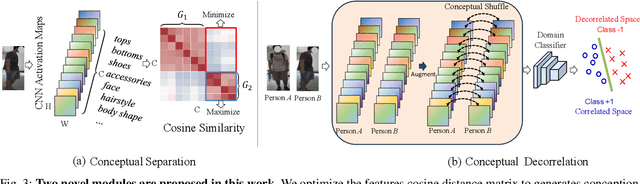
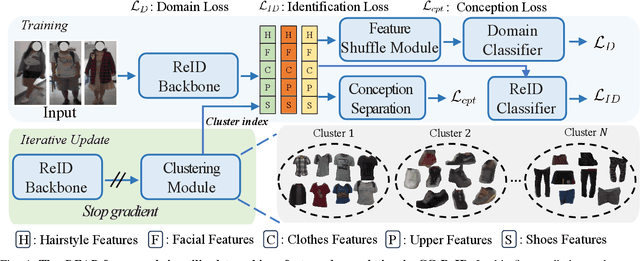
Cloth-changing person re-identification (CC-ReID) poses a significant challenge in computer vision. A prevailing approach is to prompt models to concentrate on causal attributes, like facial features and hairstyles, rather than confounding elements such as clothing appearance. Traditional methods to achieve this involve integrating multi-modality data or employing manually annotated clothing labels, which tend to complicate the model and require extensive human effort. In our study, we demonstrate that simply reducing feature correlations during training can significantly enhance the baseline model's performance. We theoretically elucidate this effect and introduce a novel regularization technique based on density ratio estimation. This technique aims to minimize feature correlation in the training process of cloth-changing ReID baselines. Our approach is model-independent, offering broad enhancements without needing additional data or labels. We validate our method through comprehensive experiments on prevalent CC-ReID datasets, showing its effectiveness in improving baseline models' generalization capabilities.
Robust Traffic Forecasting against Spatial Shift over Years
Oct 01, 2024



Recent advancements in Spatiotemporal Graph Neural Networks (ST-GNNs) and Transformers have demonstrated promising potential for traffic forecasting by effectively capturing both temporal and spatial correlations. The generalization ability of spatiotemporal models has received considerable attention in recent scholarly discourse. However, no substantive datasets specifically addressing traffic out-of-distribution (OOD) scenarios have been proposed. Existing ST-OOD methods are either constrained to testing on extant data or necessitate manual modifications to the dataset. Consequently, the generalization capacity of current spatiotemporal models in OOD scenarios remains largely underexplored. In this paper, we investigate state-of-the-art models using newly proposed traffic OOD benchmarks and, surprisingly, find that these models experience a significant decline in performance. Through meticulous analysis, we attribute this decline to the models' inability to adapt to previously unobserved spatial relationships. To address this challenge, we propose a novel Mixture of Experts (MoE) framework, which learns a set of graph generators (i.e., graphons) during training and adaptively combines them to generate new graphs based on novel environmental conditions to handle spatial distribution shifts during testing. We further extend this concept to the Transformer architecture, achieving substantial improvements. Our method is both parsimonious and efficacious, and can be seamlessly integrated into any spatiotemporal model, outperforming current state-of-the-art approaches in addressing spatial dynamics.
STGformer: Efficient Spatiotemporal Graph Transformer for Traffic Forecasting
Oct 01, 2024



Traffic forecasting is a cornerstone of smart city management, enabling efficient resource allocation and transportation planning. Deep learning, with its ability to capture complex nonlinear patterns in spatiotemporal (ST) data, has emerged as a powerful tool for traffic forecasting. While graph neural networks (GCNs) and transformer-based models have shown promise, their computational demands often hinder their application to real-world road networks, particularly those with large-scale spatiotemporal interactions. To address these challenges, we propose a novel spatiotemporal graph transformer (STGformer) architecture. STGformer effectively balances the strengths of GCNs and Transformers, enabling efficient modeling of both global and local traffic patterns while maintaining a manageable computational footprint. Unlike traditional approaches that require multiple attention layers, STG attention block captures high-order spatiotemporal interactions in a single layer, significantly reducing computational cost. In particular, STGformer achieves a 100x speedup and a 99.8\% reduction in GPU memory usage compared to STAEformer during batch inference on a California road graph with 8,600 sensors. We evaluate STGformer on the LargeST benchmark and demonstrate its superiority over state-of-the-art Transformer-based methods such as PDFormer and STAEformer, which underline STGformer's potential to revolutionize traffic forecasting by overcoming the computational and memory limitations of existing approaches, making it a promising foundation for future spatiotemporal modeling tasks.
Navigating Beyond Dropout: An Intriguing Solution Towards Generalizable Image Super Resolution
Mar 01, 2024Deep learning has led to a dramatic leap on Single Image Super-Resolution (SISR) performances in recent years. %Despite the substantial advancement% While most existing work assumes a simple and fixed degradation model (e.g., bicubic downsampling), the research of Blind SR seeks to improve model generalization ability with unknown degradation. Recently, Kong et al pioneer the investigation of a more suitable training strategy for Blind SR using Dropout. Although such method indeed brings substantial generalization improvements via mitigating overfitting, we argue that Dropout simultaneously introduces undesirable side-effect that compromises model's capacity to faithfully reconstruct fine details. We show both the theoretical and experimental analyses in our paper, and furthermore, we present another easy yet effective training strategy that enhances the generalization ability of the model by simply modulating its first and second-order features statistics. Experimental results have shown that our method could serve as a model-agnostic regularization and outperforms Dropout on seven benchmark datasets including both synthetic and real-world scenarios.