 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriply Laplacian Scale Mixture Modeling for Seismic Data Noise Suppression
Feb 20, 2025Sparsity-based tensor recovery methods have shown great potential in suppressing seismic data noise. These methods exploit tensor sparsity measures capturing the low-dimensional structures inherent in seismic data tensors to remove noise by applying sparsity constraints through soft-thresholding or hard-thresholding operators. However, in these methods, considering that real seismic data are non-stationary and affected by noise, the variances of tensor coefficients are unknown and may be difficult to accurately estimate from the degraded seismic data, leading to undesirable noise suppression performance. In this paper, we propose a novel triply Laplacian scale mixture (TLSM) approach for seismic data noise suppression, which significantly improves the estimation accuracy of both the sparse tensor coefficients and hidden scalar parameters. To make the optimization problem manageable, an alternating direction method of multipliers (ADMM) algorithm is employed to solve the proposed TLSM-based seismic data noise suppression problem. Extensive experimental results on synthetic and field seismic data demonstrate that the proposed TLSM algorithm outperforms many state-of-the-art seismic data noise suppression methods in both quantitative and qualitative evaluations while providing exceptional computational efficiency.
CausalMob: Causal Human Mobility Prediction with LLMs-derived Human Intentions toward Public Events
Dec 03, 2024
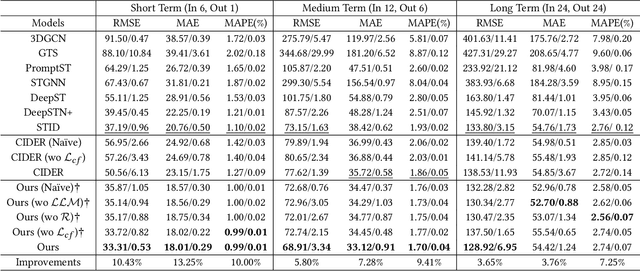
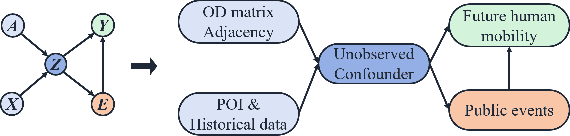
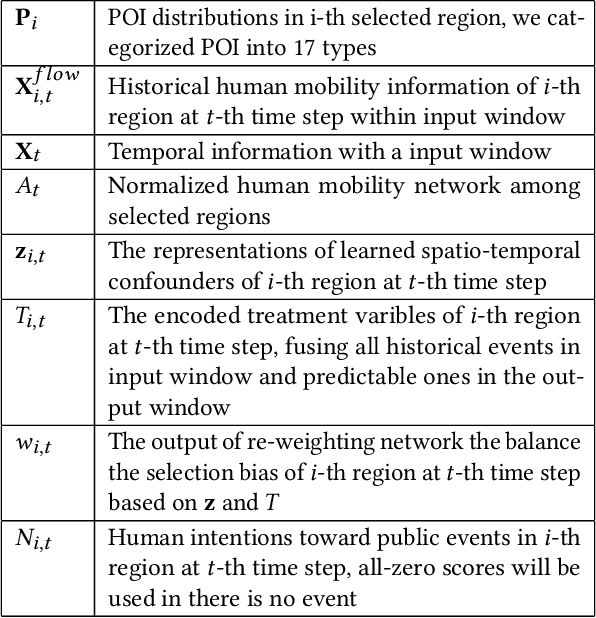
Large-scale human mobility exhibits spatial and temporal patterns that can assist policymakers in decision making. Although traditional prediction models attempt to capture these patterns, they often interfered by non-periodic public events, such as disasters and occasional celebrations. Since regular human mobility patterns are heavily affected by these events, estimating their causal effects is critical to accurate mobility predictions. Although news articles provide unique perspectives on these events in an unstructured format, processing is a challenge. In this study, we propose a causality-augmented prediction model, called \textbf{CausalMob}, to analyze the causal effects of public events. We first utilize large language models (LLMs) to extract human intentions from news articles and transform them into features that act as causal treatments. Next, the model learns representations of spatio-temporal regional covariates from multiple data sources to serve as confounders for causal inference. Finally, we present a causal effect estimation framework to ensure event features remain independent of confounders during prediction. Based on large-scale real-world data, the experimental results show that the proposed model excels in human mobility prediction, outperforming state-of-the-art models.
Taming the Long Tail in Human Mobility Prediction
Oct 19, 2024



With the popularity of location-based services, human mobility prediction plays a key role in enhancing personalized navigation, optimizing recommendation systems, and facilitating urban mobility and planning. This involves predicting a user's next POI (point-of-interest) visit using their past visit history. However, the uneven distribution of visitations over time and space, namely the long-tail problem in spatial distribution, makes it difficult for AI models to predict those POIs that are less visited by humans. In light of this issue, we propose the Long-Tail Adjusted Next POI Prediction (LoTNext) framework for mobility prediction, combining a Long-Tailed Graph Adjustment module to reduce the impact of the long-tailed nodes in the user-POI interaction graph and a novel Long-Tailed Loss Adjustment module to adjust loss by logit score and sample weight adjustment strategy. Also, we employ the auxiliary prediction task to enhance generalization and accuracy. Our experiments with two real-world trajectory datasets demonstrate that LoTNext significantly surpasses existing state-of-the-art works. Our code is available at https://github.com/Yukayo/LoTNext.
FANNO: Augmenting High-Quality Instruction Data with Open-Sourced LLMs Only
Aug 02, 2024
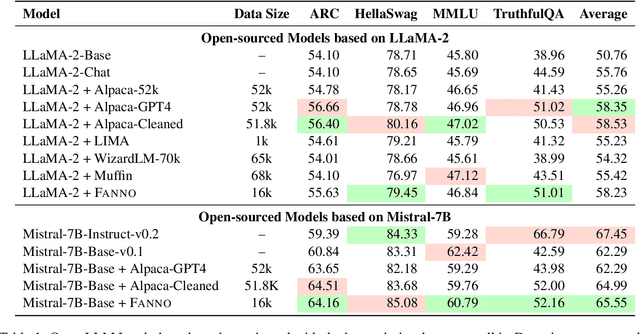
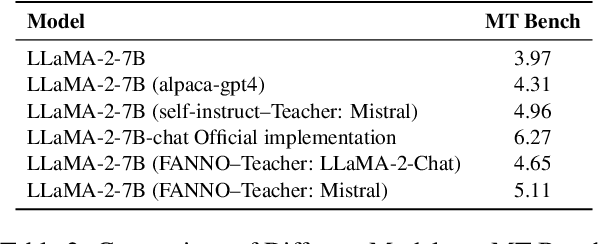
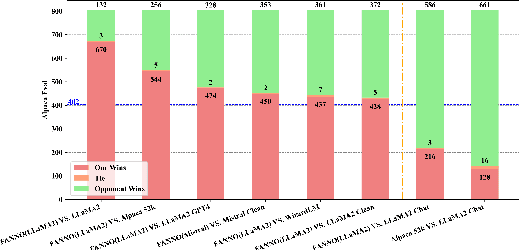
Instruction fine-tuning stands as a crucial advancement in leveraging large language models (LLMs) for enhanced task performance. However, the annotation of instruction datasets has traditionally been expensive and laborious, often relying on manual annotations or costly API calls of proprietary LLMs. To address these challenges, we introduce FANNO, a fully autonomous, open-sourced framework that revolutionizes the annotation process without the need for pre-existing annotated data. Utilizing a Mistral-7b-instruct model, FANNO efficiently produces diverse and high-quality datasets through a structured process involving document pre-screening, instruction generation, and response generation. Experiments on Open LLM Leaderboard and AlpacaEval benchmark show that the FANNO can generate high-quality data with diversity and complexity for free, comparable to human-annotated or cleaned datasets like Alpaca-GPT4-Cleaned.
TrafPS: A Shapley-based Visual Analytics Approach to Interpret Traffic
Mar 07, 2024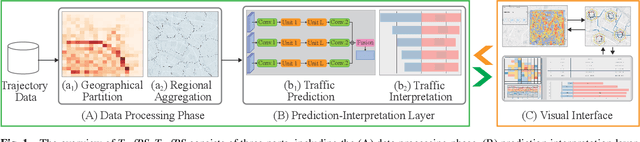

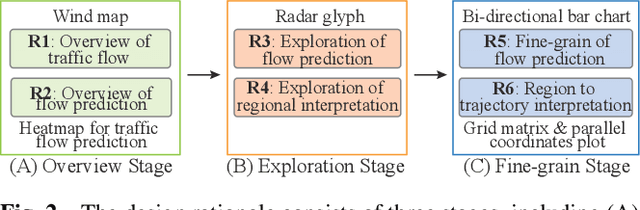

Recent achievements in deep learning (DL) have shown its potential for predicting traffic flows. Such predictions are beneficial for understanding the situation and making decisions in traffic control. However, most state-of-the-art DL models are considered "black boxes" with little to no transparency for end users with respect to the underlying mechanisms. Some previous work tried to "open the black boxes" and increase the interpretability of how predictions are generated. However, it still remains challenging to handle complex models on large-scale spatio-temporal data and discover salient spatial and temporal patterns that significantly influence traffic flows. To overcome the challenges, we present TrafPS, a visual analytics approach for interpreting traffic prediction outcomes to support decision-making in traffic management and urban planning. The measurements, region SHAP and trajectory SHAP, are proposed to quantify the impact of flow patterns on urban traffic at different levels. Based on the task requirement from the domain experts, we employ an interactive visual interface for multi-aspect exploration and analysis of significant flow patterns. Two real-world case studies demonstrate the effectiveness of TrafPS in identifying key routes and decision-making support for urban planning.
PlanGPT: Enhancing Urban Planning with Tailored Language Model and Efficient Retrieval
Feb 29, 2024
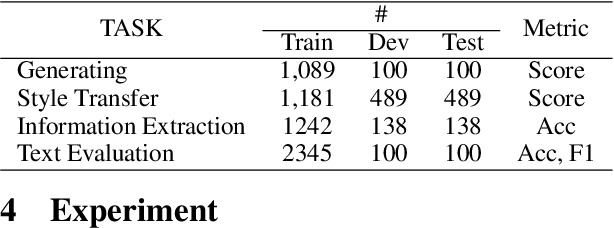
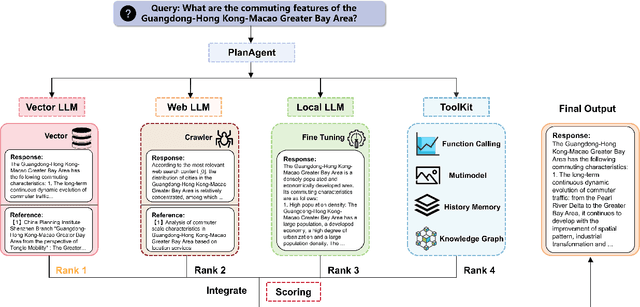
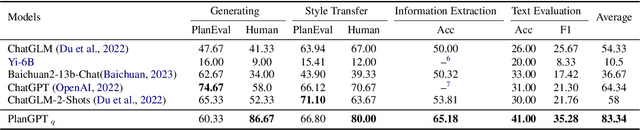
In the field of urban planning, general-purpose large language models often struggle to meet the specific needs of planners. Tasks like generating urban planning texts, retrieving related information, and evaluating planning documents pose unique challenges. To enhance the efficiency of urban professionals and overcome these obstacles, we introduce PlanGPT, the first specialized Large Language Model tailored for urban and spatial planning. Developed through collaborative efforts with institutions like the Chinese Academy of Urban Planning, PlanGPT leverages a customized local database retrieval framework, domain-specific fine-tuning of base models, and advanced tooling capabilities. Empirical tests demonstrate that PlanGPT has achieved advanced performance, delivering responses of superior quality precisely tailored to the intricacies of urban planning.
Hyper-Relational Knowledge Graph Neural Network for Next POI
Nov 28, 2023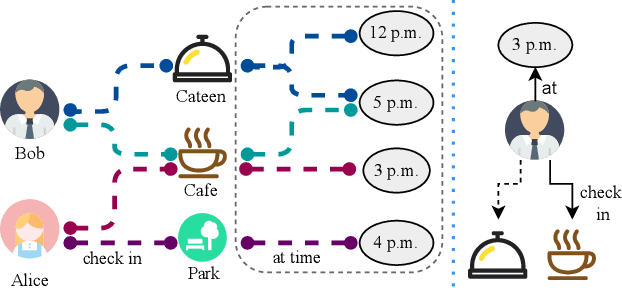
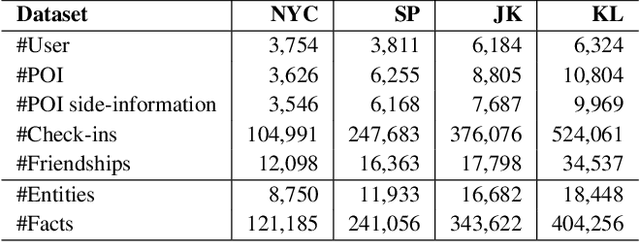

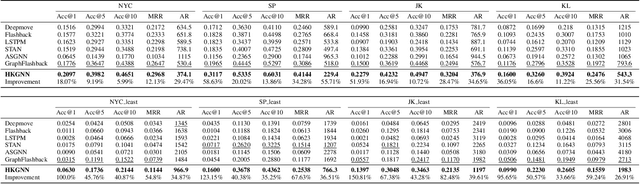
With the advancement of mobile technology, Point of Interest (POI) recommendation systems in Location-based Social Networks (LBSN) have brought numerous benefits to both users and companies. Many existing works employ Knowledge Graph (KG) to alleviate the data sparsity issue in LBSN. These approaches primarily focus on modeling the pair-wise relations in LBSN to enrich the semantics and thereby relieve the data sparsity issue. However, existing approaches seldom consider the hyper-relations in LBSN, such as the mobility relation (a 3-ary relation: user-POI-time). This makes the model hard to exploit the semantics accurately. In addition, prior works overlook the rich structural information inherent in KG, which consists of higher-order relations and can further alleviate the impact of data sparsity.To this end, we propose a Hyper-Relational Knowledge Graph Neural Network (HKGNN) model. In HKGNN, a Hyper-Relational Knowledge Graph (HKG) that models the LBSN data is constructed to maintain and exploit the rich semantics of hyper-relations. Then we proposed a Hypergraph Neural Network to utilize the structural information of HKG in a cohesive way. In addition, a self-attention network is used to leverage sequential information and make personalized recommendations. Furthermore, side information, essential in reducing data sparsity by providing background knowledge of POIs, is not fully utilized in current methods. In light of this, we extended the current dataset with available side information to further lessen the impact of data sparsity. Results of experiments on four real-world LBSN datasets demonstrate the effectiveness of our approach compared to existing state-of-the-art methods.
Hybrid Feature Embedding For Automatic Building Outline Extraction
Jul 20, 2023
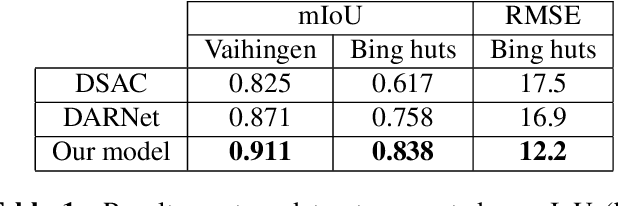

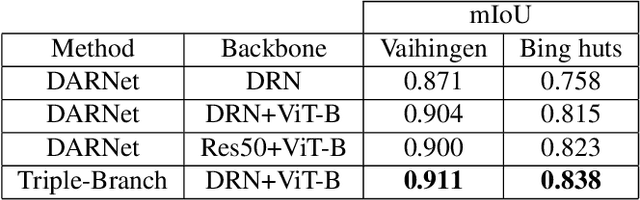
Building outline extracted from high-resolution aerial images can be used in various application fields such as change detection and disaster assessment. However, traditional CNN model cannot recognize contours very precisely from original images. In this paper, we proposed a CNN and Transformer based model together with active contour model to deal with this problem. We also designed a triple-branch decoder structure to handle different features generated by encoder. Experiment results show that our model outperforms other baseline model on two datasets, achieving 91.1% mIoU on Vaihingen and 83.8% on Bing huts.
Multitask Weakly Supervised Learning for Origin Destination Travel Time Estimation
Jan 13, 2023



Travel time estimation from GPS trips is of great importance to order duration, ridesharing, taxi dispatching, etc. However, the dense trajectory is not always available due to the limitation of data privacy and acquisition, while the origin destination (OD) type of data, such as NYC taxi data, NYC bike data, and Capital Bikeshare data, is more accessible. To address this issue, this paper starts to estimate the OD trips travel time combined with the road network. Subsequently, a Multitask Weakly Supervised Learning Framework for Travel Time Estimation (MWSL TTE) has been proposed to infer transition probability between roads segments, and the travel time on road segments and intersection simultaneously. Technically, given an OD pair, the transition probability intends to recover the most possible route. And then, the output of travel time is equal to the summation of all segments' and intersections' travel time in this route. A novel route recovery function has been proposed to iteratively maximize the current route's co occurrence probability, and minimize the discrepancy between routes' probability distribution and the inverse distribution of routes' estimation loss. Moreover, the expected log likelihood function based on a weakly supervised framework has been deployed in optimizing the travel time from road segments and intersections concurrently. We conduct experiments on a wide range of real world taxi datasets in Xi'an and Chengdu and demonstrate our method's effectiveness on route recovery and travel time estimation.
Easy Begun is Half Done: Spatial-Temporal Graph Modeling with ST-Curriculum Dropout
Nov 28, 2022



Spatial-temporal (ST) graph modeling, such as traffic speed forecasting and taxi demand prediction, is an important task in deep learning area. However, for the nodes in graph, their ST patterns can vary greatly in difficulties for modeling, owning to the heterogeneous nature of ST data. We argue that unveiling the nodes to the model in a meaningful order, from easy to complex, can provide performance improvements over traditional training procedure. The idea has its root in Curriculum Learning which suggests in the early stage of training models can be sensitive to noise and difficult samples. In this paper, we propose ST-Curriculum Dropout, a novel and easy-to-implement strategy for spatial-temporal graph modeling. Specifically, we evaluate the learning difficulty of each node in high-level feature space and drop those difficult ones out to ensure the model only needs to handle fundamental ST relations at the beginning, before gradually moving to hard ones. Our strategy can be applied to any canonical deep learning architecture without extra trainable parameters, and extensive experiments on a wide range of datasets are conducted to illustrate that, by controlling the difficulty level of ST relations as the training progresses, the model is able to capture better representation of the data and thus yields better generalization.