 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAG-INSTRUCT: Controlled Instruction Complexity Enhancement through Structure-based Augmentation
May 24, 2025High-quality instruction data is crucial for developing large language models (LLMs), yet existing approaches struggle to effectively control instruction complexity. We present TAG-INSTRUCT, a novel framework that enhances instruction complexity through structured semantic compression and controlled difficulty augmentation. Unlike previous prompt-based methods operating on raw text, TAG-INSTRUCT compresses instructions into a compact tag space and systematically enhances complexity through RL-guided tag expansion. Through extensive experiments, we show that TAG-INSTRUCT outperforms existing instruction complexity augmentation approaches. Our analysis reveals that operating in tag space provides superior controllability and stability across different instruction synthesis frameworks.
PlanGPT-VL: Enhancing Urban Planning with Domain-Specific Vision-Language Models
May 21, 2025In the field of urban planning, existing Vision-Language Models (VLMs) frequently fail to effectively analyze and evaluate planning maps, despite the critical importance of these visual elements for urban planners and related educational contexts. Planning maps, which visualize land use, infrastructure layouts, and functional zoning, require specialized understanding of spatial configurations, regulatory requirements, and multi-scale analysis. To address this challenge, we introduce PlanGPT-VL, the first domain-specific Vision-Language Model tailored specifically for urban planning maps. PlanGPT-VL employs three innovative approaches: (1) PlanAnno-V framework for high-quality VQA data synthesis, (2) Critical Point Thinking to reduce hallucinations through structured verification, and (3) comprehensive training methodology combining Supervised Fine-Tuning with frozen vision encoder parameters. Through systematic evaluation on our proposed PlanBench-V benchmark, we demonstrate that PlanGPT-VL significantly outperforms general-purpose state-of-the-art VLMs in specialized planning map interpretation tasks, offering urban planning professionals a reliable tool for map analysis, assessment, and educational applications while maintaining high factual accuracy. Our lightweight 7B parameter model achieves comparable performance to models exceeding 72B parameters, demonstrating efficient domain specialization without sacrificing performance.
FANNO: Augmenting High-Quality Instruction Data with Open-Sourced LLMs Only
Aug 02, 2024
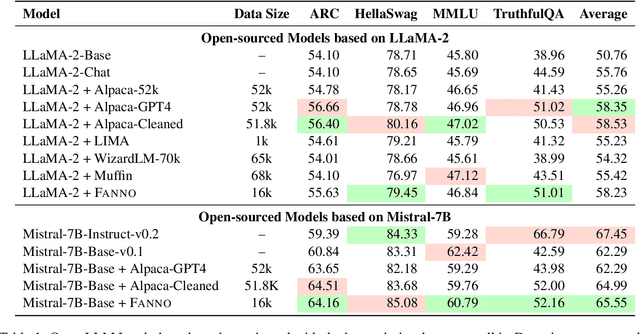
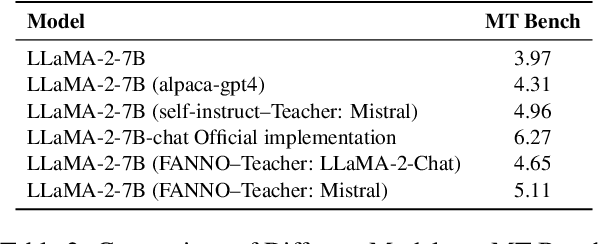
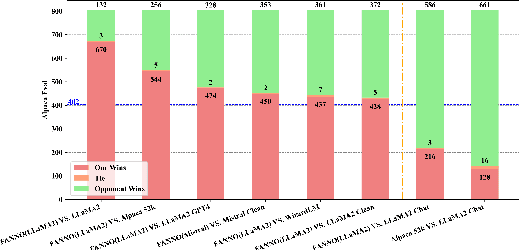
Instruction fine-tuning stands as a crucial advancement in leveraging large language models (LLMs) for enhanced task performance. However, the annotation of instruction datasets has traditionally been expensive and laborious, often relying on manual annotations or costly API calls of proprietary LLMs. To address these challenges, we introduce FANNO, a fully autonomous, open-sourced framework that revolutionizes the annotation process without the need for pre-existing annotated data. Utilizing a Mistral-7b-instruct model, FANNO efficiently produces diverse and high-quality datasets through a structured process involving document pre-screening, instruction generation, and response generation. Experiments on Open LLM Leaderboard and AlpacaEval benchmark show that the FANNO can generate high-quality data with diversity and complexity for free, comparable to human-annotated or cleaned datasets like Alpaca-GPT4-Cleaned.
Multi-Layer Ranking with Large Language Models for News Source Recommendation
Jun 17, 2024To seek reliable information sources for news events, we introduce a novel task of expert recommendation, which aims to identify trustworthy sources based on their previously quoted statements. To achieve this, we built a novel dataset, called NewsQuote, consisting of 23,571 quote-speaker pairs sourced from a collection of news articles. We formulate the recommendation task as the retrieval of experts based on their likelihood of being associated with a given query. We also propose a multi-layer ranking framework employing Large Language Models to improve the recommendation performance. Our results show that employing an in-context learning based LLM ranker and a multi-layer ranking-based filter significantly improve both the predictive quality and behavioural quality of the recommender system.
PlanGPT: Enhancing Urban Planning with Tailored Language Model and Efficient Retrieval
Feb 29, 2024
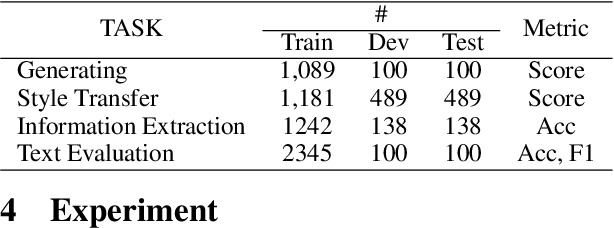
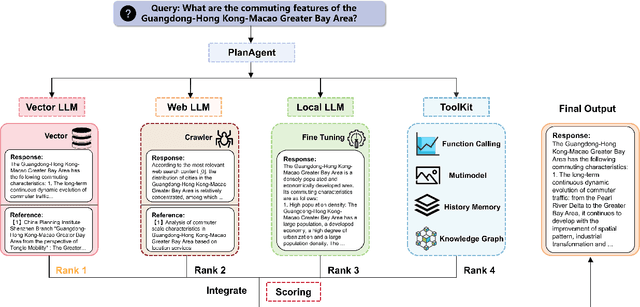
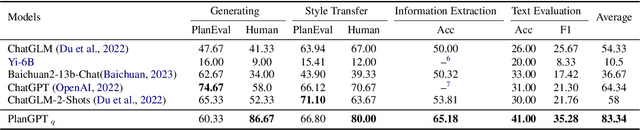
In the field of urban planning, general-purpose large language models often struggle to meet the specific needs of planners. Tasks like generating urban planning texts, retrieving related information, and evaluating planning documents pose unique challenges. To enhance the efficiency of urban professionals and overcome these obstacles, we introduce PlanGPT, the first specialized Large Language Model tailored for urban and spatial planning. Developed through collaborative efforts with institutions like the Chinese Academy of Urban Planning, PlanGPT leverages a customized local database retrieval framework, domain-specific fine-tuning of base models, and advanced tooling capabilities. Empirical tests demonstrate that PlanGPT has achieved advanced performance, delivering responses of superior quality precisely tailored to the intricacies of urban planning.
NarrativePlay: Interactive Narrative Understanding
Oct 02, 2023

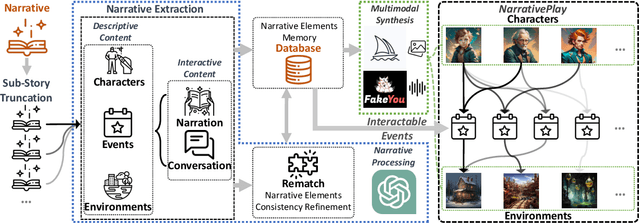
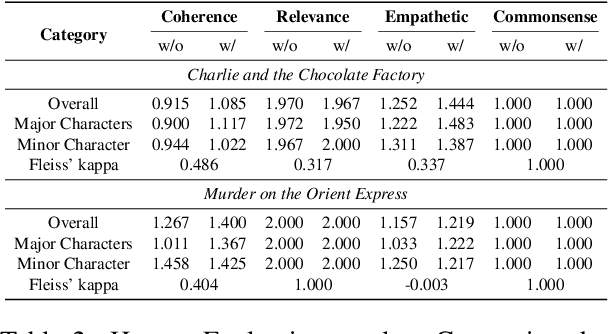
In this paper, we introduce NarrativePlay, a novel system that allows users to role-play a fictional character and interact with other characters in narratives such as novels in an immersive environment. We leverage Large Language Models (LLMs) to generate human-like responses, guided by personality traits extracted from narratives. The system incorporates auto-generated visual display of narrative settings, character portraits, and character speech, greatly enhancing user experience. Our approach eschews predefined sandboxes, focusing instead on main storyline events extracted from narratives from the perspective of a user-selected character. NarrativePlay has been evaluated on two types of narratives, detective and adventure stories, where users can either explore the world or improve their favorability with the narrative characters through conversations.
Look Beneath the Surface: Exploiting Fundamental Symmetry for Sample-Efficient Offline RL
Jun 08, 2023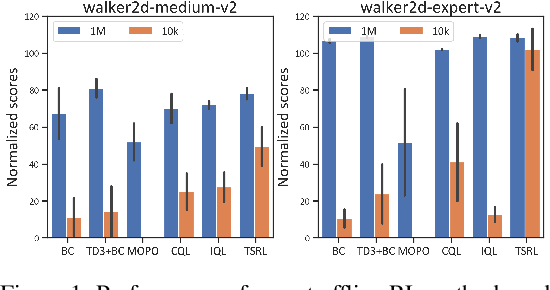
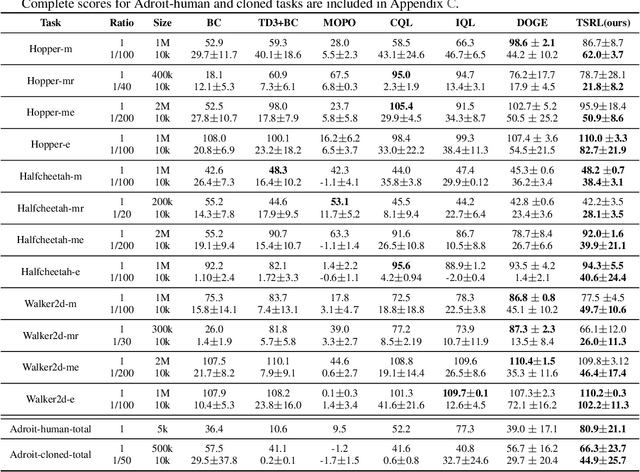


Offline reinforcement learning (RL) offers an appealing approach to real-world tasks by learning policies from pre-collected datasets without interacting with the environment. However, the performance of existing offline RL algorithms heavily depends on the scale and state-action space coverage of datasets. Real-world data collection is often expensive and uncontrollable, leading to small and narrowly covered datasets and posing significant challenges for practical deployments of offline RL. In this paper, we provide a new insight that leveraging the fundamental symmetry of system dynamics can substantially enhance offline RL performance under small datasets. Specifically, we propose a Time-reversal symmetry (T-symmetry) enforced Dynamics Model (TDM), which establishes consistency between a pair of forward and reverse latent dynamics. TDM provides both well-behaved representations for small datasets and a new reliability measure for OOD samples based on compliance with the T-symmetry. These can be readily used to construct a new offline RL algorithm (TSRL) with less conservative policy constraints and a reliable latent space data augmentation procedure. Based on extensive experiments, we find TSRL achieves great performance on small benchmark datasets with as few as 1% of the original samples, which significantly outperforms the recent offline RL algorithms in terms of data efficiency and generalizability.
NewsQuote: A Dataset Built on Quote Extraction and Attribution for Expert Recommendation in Fact-Checking
May 05, 2023



To enhance the ability to find credible evidence in news articles, we propose a novel task of expert recommendation, which aims to identify trustworthy experts on a specific news topic. To achieve the aim, we describe the construction of a novel NewsQuote dataset consisting of 24,031 quote-speaker pairs that appeared on a COVID-19 news corpus. We demonstrate an automatic pipeline for speaker and quote extraction via a BERT-based Question Answering model. Then, we formulate expert recommendations as document retrieval task by retrieving relevant quotes first as an intermediate step for expert identification, and expert retrieval by directly retrieving sources based on the probability of a query conditional on a candidate expert. Experimental results on NewsQuote show that document retrieval is more effective in identifying relevant experts for a given news topic compared to expert retrieval
Discriminator-Guided Model-Based Offline Imitation Learning
Jul 05, 2022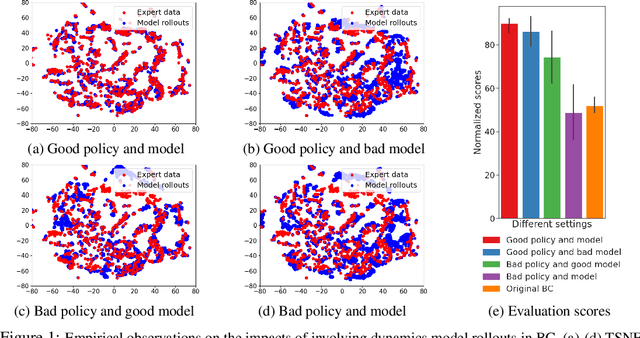

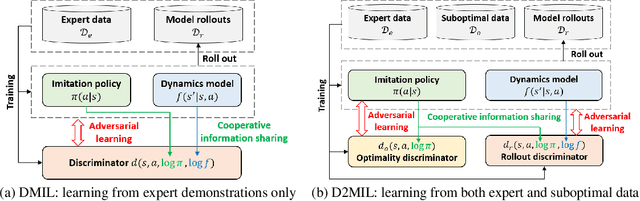

Offline imitation learning (IL) is a powerful method to solve decision-making problems from expert demonstrations without reward labels. Existing offline IL methods suffer from severe performance degeneration under limited expert data due to covariate shift. Including a learned dynamics model can potentially improve the state-action space coverage of expert data, however, it also faces challenging issues like model approximation/generalization errors and suboptimality of rollout data. In this paper, we propose the Discriminator-guided Model-based offline Imitation Learning (DMIL) framework, which introduces a discriminator to simultaneously distinguish the dynamics correctness and suboptimality of model rollout data against real expert demonstrations. DMIL adopts a novel cooperative-yet-adversarial learning strategy, which uses the discriminator to guide and couple the learning process of the policy and dynamics model, resulting in improved model performance and robustness. Our framework can also be extended to the case when demonstrations contain a large proportion of suboptimal data. Experimental results show that DMIL and its extension achieve superior performance and robustness compared to state-of-the-art offline IL methods under small datasets.
A Manifold View of Adversarial Risk
Apr 08, 2022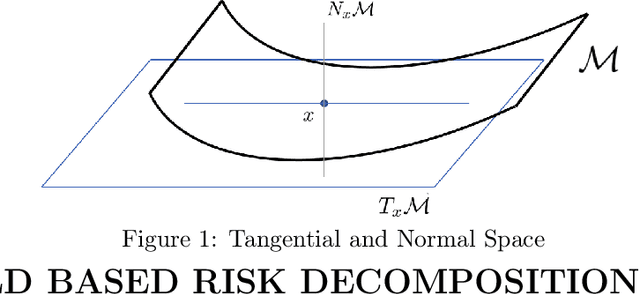
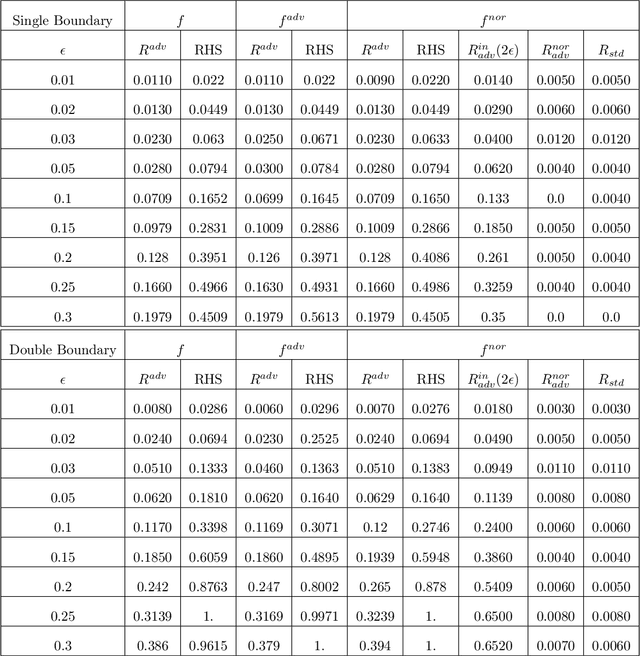
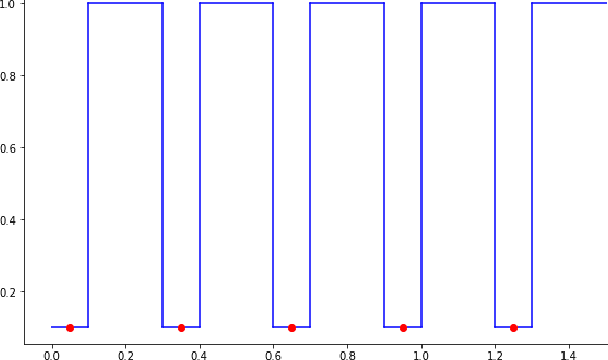
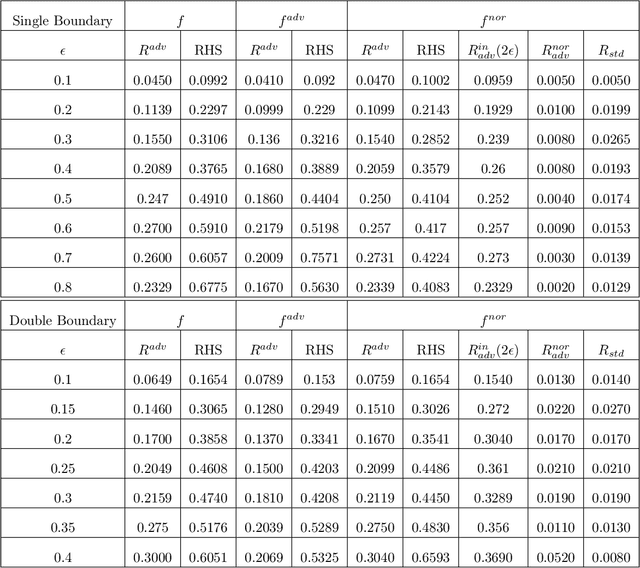
The adversarial risk of a machine learning model has been widely studied. Most previous works assume that the data lies in the whole ambient space. We propose to take a new angle and take the manifold assumption into consideration. Assuming data lies in a manifold, we investigate two new types of adversarial risk, the normal adversarial risk due to perturbation along normal direction, and the in-manifold adversarial risk due to perturbation within the manifold. We prove that the classic adversarial risk can be bounded from both sides using the normal and in-manifold adversarial risks. We also show with a surprisingly pessimistic case that the standard adversarial risk can be nonzero even when both normal and in-manifold risks are zero. We finalize the paper with empirical studies supporting our theoretical results. Our results suggest the possibility of improving the robustness of a classifier by only focusing on the normal adversarial risk.