 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDIT: Evidence-Diagnosed Intervention Training for Rule-Faithful LLM Grading
Jun 04, 2026Reliable rubric grading requires more than accurate score prediction. Each judgement must be grounded in the mark scheme and evidence from the student answer. Existing credit-assignment and intervention methods, primarily designed for self-contained reasoning tasks such as mathematics reasoning, struggle in this setting because they do not identify where grading reasoning goes wrong or how the model's belief about the final mark changes during reasoning. We propose Evidence-Diagnosed Intervention Training (EDIT), a two-phase framework for training more rubric-faithful LLM graders. First, EDIT-SFT locates problematic reasoning steps using internal model signals: posterior belief over the final mark and input-grounding scores. It then revises only these local steps with help from a rubric checklist. Second, EDIT-RL calibrates the grader with belief-guided reward shaping, penalising large harmful belief drifts while still allowing helpful exploration. Experiments on two real-world, multi-subject grading benchmarks demonstrate that EDIT consistently outperforms strong supervised fine-tuning and reinforcement learning baselines on both in-domain and out-of-domain splits, with ablation studies confirming that internal-state diagnostics drive these gains.
Linear Ensembles Wash Away Watermarks: On the Fragility of Distributional Perturbations in LLMs
May 28, 2026Watermarking embeds statistical signatures in AI-generated text for detection and attribution. We reveal a fundamental vulnerability: when users access multiple models (today's reality), watermarks trivially fail. Watermarks perturb output distributions away from the original, and in competitive markets, these perturbations are typically independent across providers. We theoretically prove that averaging output probability distributions recovers the unwatermarked distribution with up to a second-order error term. Empirically, simply averaging 3-5 models cancels out these perturbations. We introduce WASH (Watermark Attenuation via Statistical Hybridisation), which solves practical challenges in ensemble generation: vocabulary misalignment and tokenisation differences across heterogeneous models. Experiments across six watermarking schemes and three LLMs show that averaging across 3 models suppresses detection z-scores from 5-300 to below 2 (below the detection threshold of 4) and reduces TPR at 5% FPR to below 50%, while improving quality by 27.5% and running 6 times faster than the best baseline on the long sequence generation. Our results suggest that robust AI-text detection via watermarking requires either accepting this fundamental vulnerability or unprecedented coordination among model providers.
Pull Requests as a Training Signal for Repo-Level Code Editing
Feb 07, 2026Repository-level code editing requires models to understand complex dependencies and execute precise multi-file modifications across a large codebase. While recent gains on SWE-bench rely heavily on complex agent scaffolding, it remains unclear how much of this capability can be internalised via high-quality training signals. To address this, we propose Clean Pull Request (Clean-PR), a mid-training paradigm that leverages real-world GitHub pull requests as a training signal for repository-level editing. We introduce a scalable pipeline that converts noisy pull request diffs into Search/Replace edit blocks through reconstruction and validation, resulting in the largest publicly available corpus of 2 million pull requests spanning 12 programming languages. Using this training signal, we perform a mid-training stage followed by an agentless-aligned supervised fine-tuning process with error-driven data augmentation. On SWE-bench, our model significantly outperforms the instruction-tuned baseline, achieving absolute improvements of 13.6% on SWE-bench Lite and 12.3% on SWE-bench Verified. These results demonstrate that repository-level code understanding and editing capabilities can be effectively internalised into model weights under a simplified, agentless protocol, without relying on heavy inference-time scaffolding.
Soft Reasoning: Navigating Solution Spaces in Large Language Models through Controlled Embedding Exploration
May 30, 2025Large Language Models (LLMs) struggle with complex reasoning due to limited diversity and inefficient search. We propose Soft Reasoning, an embedding-based search framework that optimises the embedding of the first token to guide generation. It combines (1) embedding perturbation for controlled exploration and (2) Bayesian optimisation to refine embeddings via a verifier-guided objective, balancing exploration and exploitation. This approach improves reasoning accuracy and coherence while avoiding reliance on heuristic search. Experiments demonstrate superior correctness with minimal computation, making it a scalable, model-agnostic solution.
Sparse Activation Editing for Reliable Instruction Following in Narratives
May 22, 2025

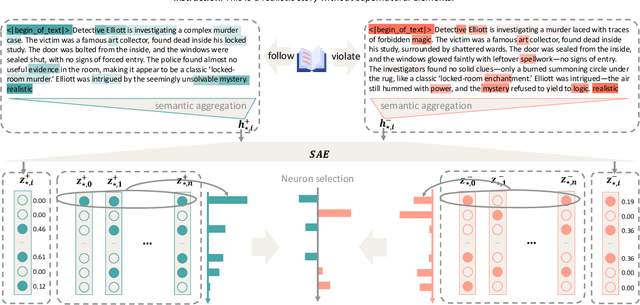

Complex narrative contexts often challenge language models' ability to follow instructions, and existing benchmarks fail to capture these difficulties. To address this, we propose Concise-SAE, a training-free framework that improves instruction following by identifying and editing instruction-relevant neurons using only natural language instructions, without requiring labelled data. To thoroughly evaluate our method, we introduce FreeInstruct, a diverse and realistic benchmark of 1,212 examples that highlights the challenges of instruction following in narrative-rich settings. While initially motivated by complex narratives, Concise-SAE demonstrates state-of-the-art instruction adherence across varied tasks without compromising generation quality.
PLAYER*: Enhancing LLM-based Multi-Agent Communication and Interaction in Murder Mystery Games
Apr 26, 2024Recent advancements in Large Language Models (LLMs) have enhanced the efficacy of agent communication and social interactions. Despite these advancements, building LLM-based agents for reasoning in dynamic environments involving competition and collaboration remains challenging due to the limitations of informed graph-based search methods. We propose PLAYER*, a novel framework based on an anytime sampling-based planner, which utilises sensors and pruners to enable a purely question-driven searching framework for complex reasoning tasks. We also introduce a quantifiable evaluation method using multiple-choice questions and construct the WellPlay dataset with 1,482 QA pairs. Experiments demonstrate PLAYER*'s efficiency and performance enhancements compared to existing methods in complex, dynamic environments with quantifiable results.
Large Language Models Fall Short: Understanding Complex Relationships in Detective Narratives
Feb 16, 2024



Existing datasets for narrative understanding often fail to represent the complexity and uncertainty of relationships in real-life social scenarios. To address this gap, we introduce a new benchmark, Conan, designed for extracting and analysing intricate character relation graphs from detective narratives. Specifically, we designed hierarchical relationship categories and manually extracted and annotated role-oriented relationships from the perspectives of various characters, incorporating both public relationships known to most characters and secret ones known to only a few. Our experiments with advanced Large Language Models (LLMs) like GPT-3.5, GPT-4, and Llama2 reveal their limitations in inferencing complex relationships and handling longer narratives. The combination of the Conan dataset and our pipeline strategy is geared towards understanding the ability of LLMs to comprehend nuanced relational dynamics in narrative contexts.
OpenToM: A Comprehensive Benchmark for Evaluating Theory-of-Mind Reasoning Capabilities of Large Language Models
Feb 14, 2024



Neural Theory-of-Mind (N-ToM), machine's ability to understand and keep track of the mental states of others, is pivotal in developing socially intelligent agents. However, prevalent N-ToM benchmarks have several shortcomings, including the presence of ambiguous and artificial narratives, absence of personality traits and preferences, a lack of questions addressing characters' psychological mental states, and limited diversity in the questions posed. In response to these issues, we construct OpenToM, a new benchmark for assessing N-ToM with (1) longer and clearer narrative stories, (2) characters with explicit personality traits, (3) actions that are triggered by character intentions, and (4) questions designed to challenge LLMs' capabilities of modeling characters' mental states of both the physical and psychological world. Using OpenToM, we reveal that state-of-the-art LLMs thrive at modeling certain aspects of mental states in the physical world but fall short when tracking characters' mental states in the psychological world.
Are NLP Models Good at Tracing Thoughts: An Overview of Narrative Understanding
Oct 28, 2023Narrative understanding involves capturing the author's cognitive processes, providing insights into their knowledge, intentions, beliefs, and desires. Although large language models (LLMs) excel in generating grammatically coherent text, their ability to comprehend the author's thoughts remains uncertain. This limitation hinders the practical applications of narrative understanding. In this paper, we conduct a comprehensive survey of narrative understanding tasks, thoroughly examining their key features, definitions, taxonomy, associated datasets, training objectives, evaluation metrics, and limitations. Furthermore, we explore the potential of expanding the capabilities of modularized LLMs to address novel narrative understanding tasks. By framing narrative understanding as the retrieval of the author's imaginative cues that outline the narrative structure, our study introduces a fresh perspective on enhancing narrative comprehension.
NarrativePlay: Interactive Narrative Understanding
Oct 02, 2023

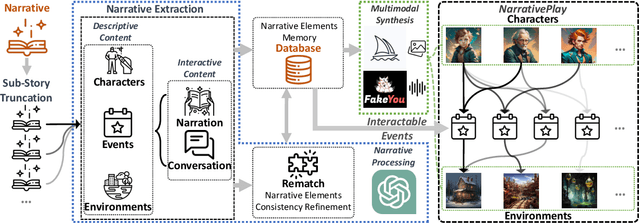
In this paper, we introduce NarrativePlay, a novel system that allows users to role-play a fictional character and interact with other characters in narratives such as novels in an immersive environment. We leverage Large Language Models (LLMs) to generate human-like responses, guided by personality traits extracted from narratives. The system incorporates auto-generated visual display of narrative settings, character portraits, and character speech, greatly enhancing user experience. Our approach eschews predefined sandboxes, focusing instead on main storyline events extracted from narratives from the perspective of a user-selected character. NarrativePlay has been evaluated on two types of narratives, detective and adventure stories, where users can either explore the world or improve their favorability with the narrative characters through conversations.