 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill and Align Decomposition for Enhanced Claim Verification
Feb 25, 2026Complex claim verification requires decomposing sentences into verifiable subclaims, yet existing methods struggle to align decomposition quality with verification performance. We propose a reinforcement learning (RL) approach that jointly optimizes decomposition quality and verifier alignment using Group Relative Policy Optimization (GRPO). Our method integrates: (i) structured sequential reasoning; (ii) supervised finetuning on teacher-distilled exemplars; and (iii) a multi-objective reward balancing format compliance, verifier alignment, and decomposition quality. Across six evaluation settings, our trained 8B decomposer improves downstream verification performance to (71.75%) macro-F1, outperforming prompt-based approaches ((+1.99), (+6.24)) and existing RL methods ((+5.84)). Human evaluation confirms the high quality of the generated subclaims. Our framework enables smaller language models to achieve state-of-the-art claim verification by jointly optimising for verification accuracy and decomposition quality.
A Variational Approach for Mitigating Entity Bias in Relation Extraction
Jun 13, 2025Mitigating entity bias is a critical challenge in Relation Extraction (RE), where models often rely excessively on entities, resulting in poor generalization. This paper presents a novel approach to address this issue by adapting a Variational Information Bottleneck (VIB) framework. Our method compresses entity-specific information while preserving task-relevant features. It achieves state-of-the-art performance on relation extraction datasets across general, financial, and biomedical domains, in both indomain (original test sets) and out-of-domain (modified test sets with type-constrained entity replacements) settings. Our approach offers a robust, interpretable, and theoretically grounded methodology.
FinNLI: Novel Dataset for Multi-Genre Financial Natural Language Inference Benchmarking
Apr 22, 2025We introduce FinNLI, a benchmark dataset for Financial Natural Language Inference (FinNLI) across diverse financial texts like SEC Filings, Annual Reports, and Earnings Call transcripts. Our dataset framework ensures diverse premise-hypothesis pairs while minimizing spurious correlations. FinNLI comprises 21,304 pairs, including a high-quality test set of 3,304 instances annotated by finance experts. Evaluations show that domain shift significantly degrades general-domain NLI performance. The highest Macro F1 scores for pre-trained (PLMs) and large language models (LLMs) baselines are 74.57% and 78.62%, respectively, highlighting the dataset's difficulty. Surprisingly, instruction-tuned financial LLMs perform poorly, suggesting limited generalizability. FinNLI exposes weaknesses in current LLMs for financial reasoning, indicating room for improvement.
Large Language Models as Financial Data Annotators: A Study on Effectiveness and Efficiency
Mar 26, 2024Collecting labeled datasets in finance is challenging due to scarcity of domain experts and higher cost of employing them. While Large Language Models (LLMs) have demonstrated remarkable performance in data annotation tasks on general domain datasets, their effectiveness on domain specific datasets remains underexplored. To address this gap, we investigate the potential of LLMs as efficient data annotators for extracting relations in financial documents. We compare the annotations produced by three LLMs (GPT-4, PaLM 2, and MPT Instruct) against expert annotators and crowdworkers. We demonstrate that the current state-of-the-art LLMs can be sufficient alternatives to non-expert crowdworkers. We analyze models using various prompts and parameter settings and find that customizing the prompts for each relation group by providing specific examples belonging to those groups is paramount. Furthermore, we introduce a reliability index (LLM-RelIndex) used to identify outputs that may require expert attention. Finally, we perform an extensive time, cost and error analysis and provide recommendations for the collection and usage of automated annotations in domain-specific settings.
Sig-Networks Toolkit: Signature Networks for Longitudinal Language Modelling
Dec 06, 2023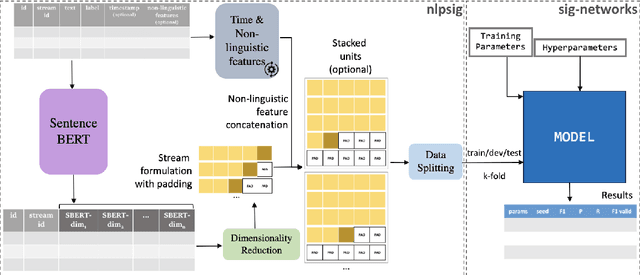
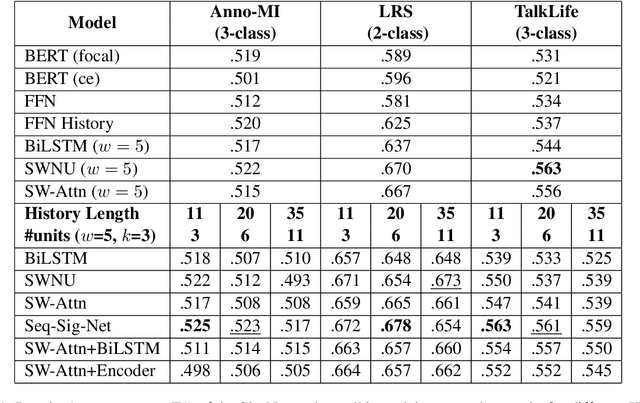
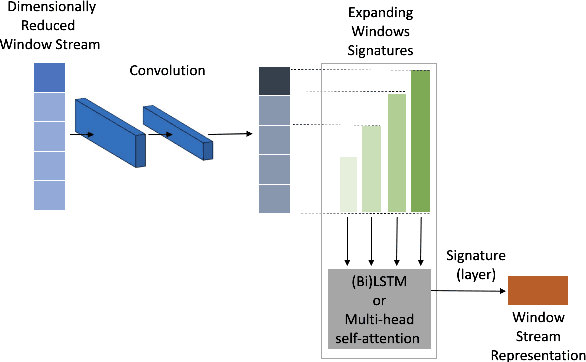
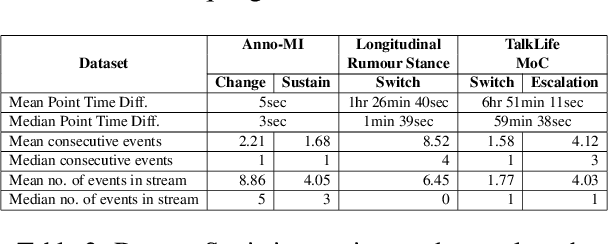
We present an open-source, pip installable toolkit, Sig-Networks, the first of its kind for longitudinal language modelling. A central focus is the incorporation of Signature-based Neural Network models, which have recently shown success in temporal tasks. We apply and extend published research providing a full suite of signature-based models. Their components can be used as PyTorch building blocks in future architectures. Sig-Networks enables task-agnostic dataset plug-in, seamless pre-processing for sequential data, parameter flexibility, automated tuning across a range of models. We examine signature networks under three different NLP tasks of varying temporal granularity: counselling conversations, rumour stance switch and mood changes in social media threads, showing SOTA performance in all three, and provide guidance for future tasks. We release the Toolkit as a PyTorch package with an introductory video, Git repositories for preprocessing and modelling including sample notebooks on the modeled NLP tasks.
PANACEA: An Automated Misinformation Detection System on COVID-19
Feb 28, 2023In this demo, we introduce a web-based misinformation detection system PANACEA on COVID-19 related claims, which has two modules, fact-checking and rumour detection. Our fact-checking module, which is supported by novel natural language inference methods with a self-attention network, outperforms state-of-the-art approaches. It is also able to give automated veracity assessment and ranked supporting evidence with the stance towards the claim to be checked. In addition, PANACEA adapts the bi-directional graph convolutional networks model, which is able to detect rumours based on comment networks of related tweets, instead of relying on the knowledge base. This rumour detection module assists by warning the users in the early stages when a knowledge base may not be available.
PHEMEPlus: Enriching Social Media Rumour Verification with External Evidence
Jul 28, 2022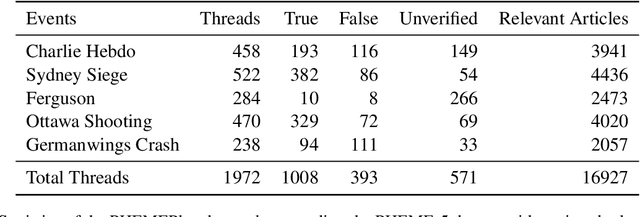


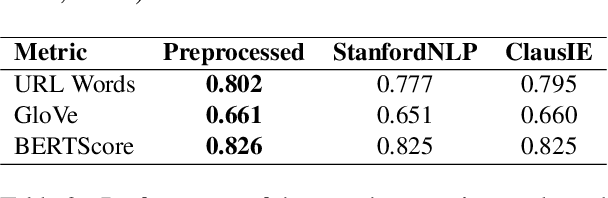
Work on social media rumour verification utilises signals from posts, their propagation and users involved. Other lines of work target identifying and fact-checking claims based on information from Wikipedia, or trustworthy news articles without considering social media context. However works combining the information from social media with external evidence from the wider web are lacking. To facilitate research in this direction, we release a novel dataset, PHEMEPlus, an extension of the PHEME benchmark, which contains social media conversations as well as relevant external evidence for each rumour. We demonstrate the effectiveness of incorporating such evidence in improving rumour verification models. Additionally, as part of the evidence collection, we evaluate various ways of query formulation to identify the most effective method.
Building for Tomorrow: Assessing the Temporal Persistence of Text Classifiers
May 19, 2022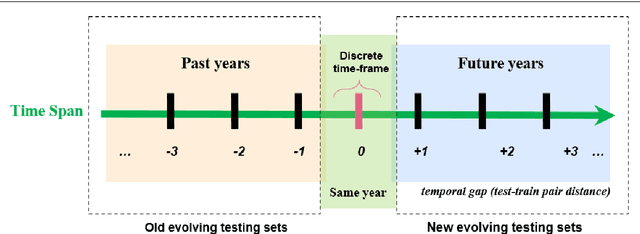
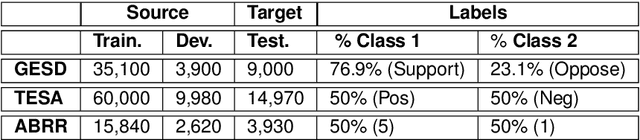
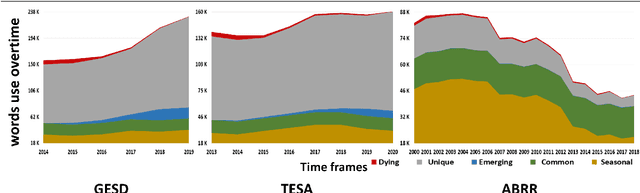
Where performance of text classification models drops over time due to changes in data, development of models whose performance persists over time is important. An ability to predict a model's ability to persist over time can help design models that can be effectively used over a longer period of time. In this paper, we look at this problem from a practical perspective by assessing the ability of a wide range of language models and classification algorithms to persist over time, as well as how dataset characteristics can help predict the temporal stability of different models. We perform longitudinal classification experiments on three datasets spanning between 6 and 19 years, and involving diverse tasks and types of data. We find that one can estimate how a model will retain its performance over time based on (i) how well the model performs over a restricted time period and its extrapolation to a longer time period, and (ii) the linguistic characteristics of the dataset, such as the familiarity score between subsets from different years. Findings from these experiments have important implications for the design of text classification models with the aim of preserving performance over time.
Natural Language Inference with Self-Attention for Veracity Assessment of Pandemic Claims
May 05, 2022
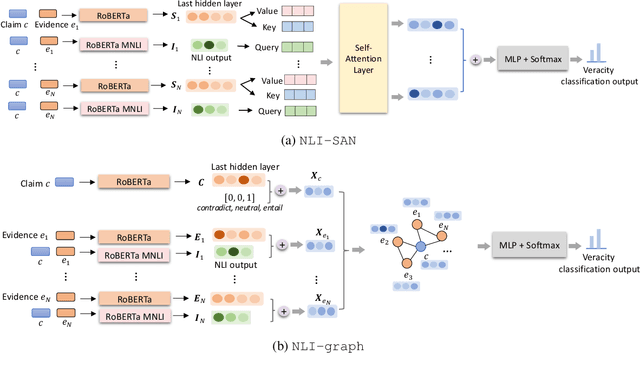

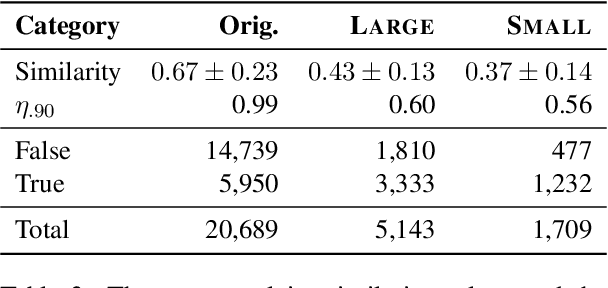
We present a comprehensive work on automated veracity assessment from dataset creation to developing novel methods based on Natural Language Inference (NLI), focusing on misinformation related to the COVID-19 pandemic. We first describe the construction of the novel PANACEA dataset consisting of heterogeneous claims on COVID-19 and their respective information sources. The dataset construction includes work on retrieval techniques and similarity measurements to ensure a unique set of claims. We then propose novel techniques for automated veracity assessment based on Natural Language Inference including graph convolutional networks and attention based approaches. We have carried out experiments on evidence retrieval and veracity assessment on the dataset using the proposed techniques and found them competitive with SOTA methods, and provided a detailed discussion.
Opinions are Made to be Changed: Temporally Adaptive Stance Classification
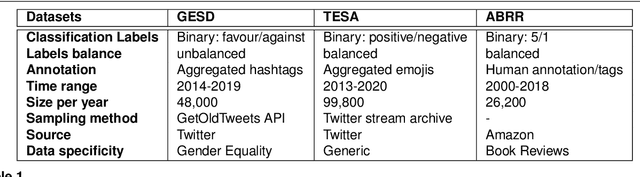
Aug 27, 2021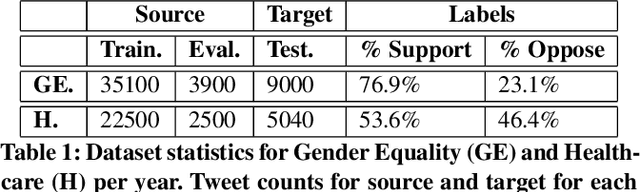
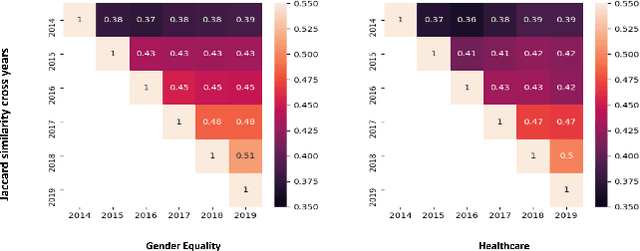
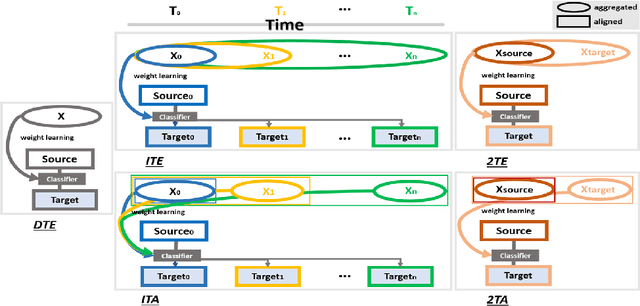
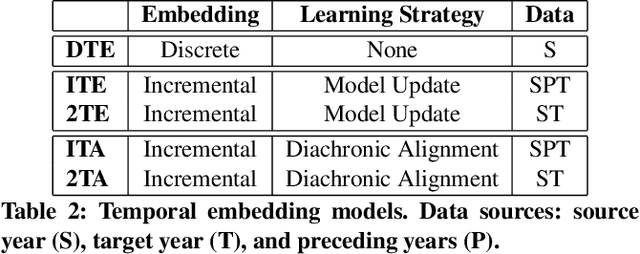
Given the rapidly evolving nature of social media and people's views, word usage changes over time. Consequently, the performance of a classifier trained on old textual data can drop dramatically when tested on newer data. While research in stance classification has advanced in recent years, no effort has been invested in making these classifiers have persistent performance over time. To study this phenomenon we introduce two novel large-scale, longitudinal stance datasets. We then evaluate the performance persistence of stance classifiers over time and demonstrate how it decays as the temporal gap between training and testing data increases. We propose a novel approach to mitigate this performance drop, which is based on temporal adaptation of the word embeddings used for training the stance classifier. This enables us to make use of readily available unlabelled data from the current time period instead of expensive annotation efforts. We propose and compare several approaches to embedding adaptation and find that the Incremental Temporal Alignment (ITA) model leads to the best results in reducing performance drop over time.