 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding for Tomorrow: Assessing the Temporal Persistence of Text Classifiers
May 19, 2022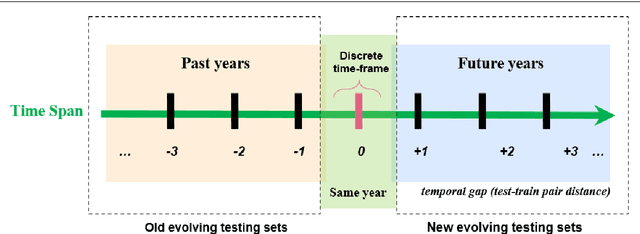
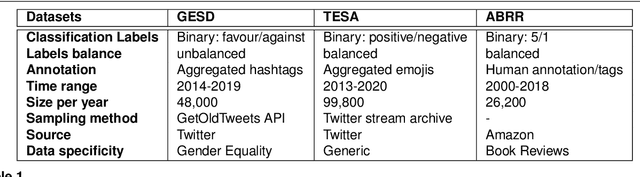
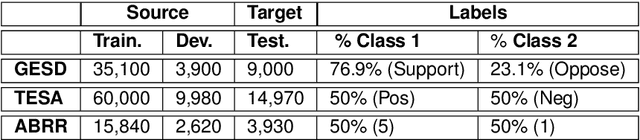
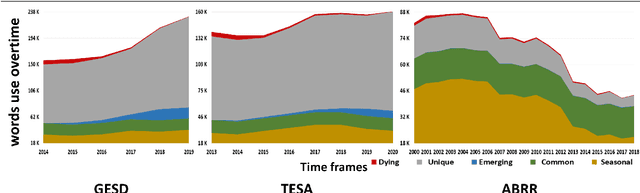
Where performance of text classification models drops over time due to changes in data, development of models whose performance persists over time is important. An ability to predict a model's ability to persist over time can help design models that can be effectively used over a longer period of time. In this paper, we look at this problem from a practical perspective by assessing the ability of a wide range of language models and classification algorithms to persist over time, as well as how dataset characteristics can help predict the temporal stability of different models. We perform longitudinal classification experiments on three datasets spanning between 6 and 19 years, and involving diverse tasks and types of data. We find that one can estimate how a model will retain its performance over time based on (i) how well the model performs over a restricted time period and its extrapolation to a longer time period, and (ii) the linguistic characteristics of the dataset, such as the familiarity score between subsets from different years. Findings from these experiments have important implications for the design of text classification models with the aim of preserving performance over time.
Capturing Stance Dynamics in Social Media: Open Challenges and Research Directions
Sep 01, 2021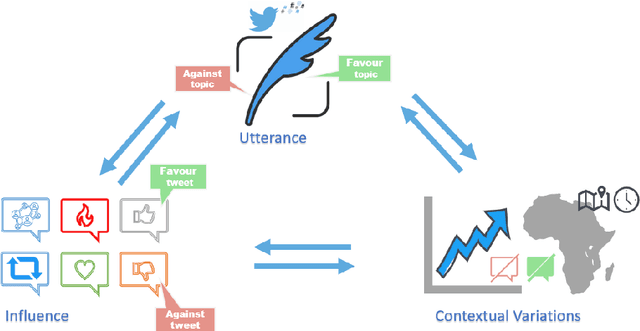
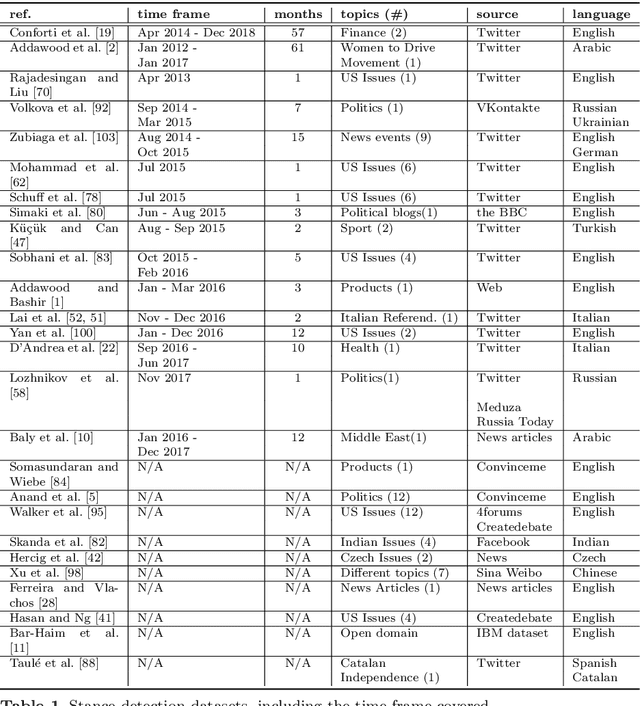
Social media platforms provide a goldmine for mining public opinion on issues of wide societal interest. Opinion mining is a problem that can be operationalised by capturing and aggregating the stance of individual social media posts as supporting, opposing or being neutral towards the issue at hand. While most prior work in stance detection has investigated datasets with limited time coverage, interest in investigating longitudinal datasets has recently increased. Evolving dynamics in linguistic and behavioural patterns observed in new data require in turn adapting stance detection systems to deal with the changes. In this survey paper, we investigate the intersection between computational linguistics and the temporal evolution of human communication in digital media. We perform a critical review in emerging research considering dynamics, exploring different semantic and pragmatic factors that impact linguistic data in general, and stance particularly. We further discuss current directions in capturing stance dynamics in social media. We organise the challenges of dealing with stance dynamics, identify open challenges and discuss future directions in three key dimensions: utterance, context and influence.
The emojification of sentiment on social media: Collection and analysis of a longitudinal Twitter sentiment dataset
Aug 31, 2021

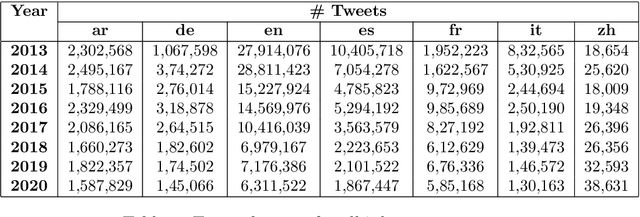

Social media, as a means for computer-mediated communication, has been extensively used to study the sentiment expressed by users around events or topics. There is however a gap in the longitudinal study of how sentiment evolved in social media over the years. To fill this gap, we develop TM-Senti, a new large-scale, distantly supervised Twitter sentiment dataset with over 184 million tweets and covering a time period of over seven years. We describe and assess our methodology to put together a large-scale, emoticon- and emoji-based labelled sentiment analysis dataset, along with an analysis of the resulting dataset. Our analysis highlights interesting temporal changes, among others in the increasing use of emojis over emoticons. We publicly release the dataset for further research in tasks including sentiment analysis and text classification of tweets. The dataset can be fully rehydrated including tweet metadata and without missing tweets thanks to the archive of tweets publicly available on the Internet Archive, which the dataset is based on.
Opinions are Made to be Changed: Temporally Adaptive Stance Classification
Aug 27, 2021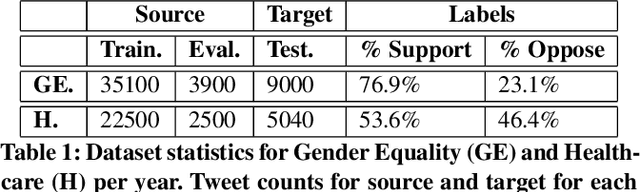
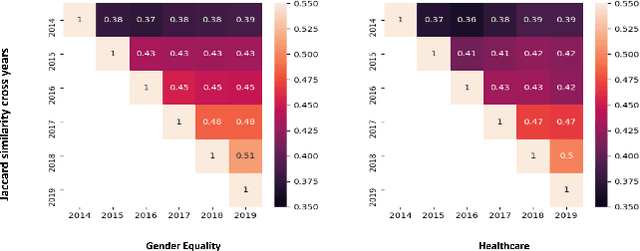
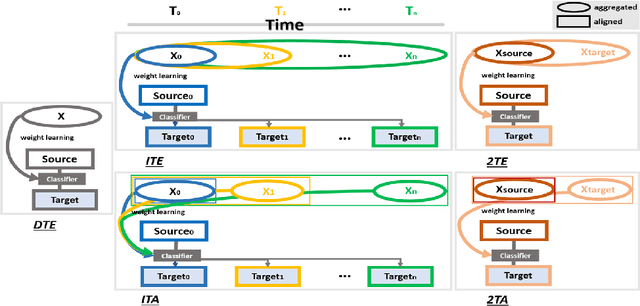
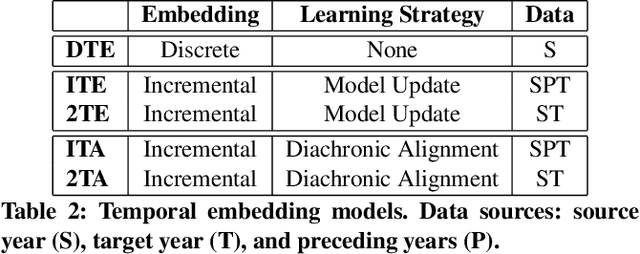
Given the rapidly evolving nature of social media and people's views, word usage changes over time. Consequently, the performance of a classifier trained on old textual data can drop dramatically when tested on newer data. While research in stance classification has advanced in recent years, no effort has been invested in making these classifiers have persistent performance over time. To study this phenomenon we introduce two novel large-scale, longitudinal stance datasets. We then evaluate the performance persistence of stance classifiers over time and demonstrate how it decays as the temporal gap between training and testing data increases. We propose a novel approach to mitigate this performance drop, which is based on temporal adaptation of the word embeddings used for training the stance classifier. This enables us to make use of readily available unlabelled data from the current time period instead of expensive annotation efforts. We propose and compare several approaches to embedding adaptation and find that the Incremental Temporal Alignment (ITA) model leads to the best results in reducing performance drop over time.
QMUL-SDS @ SardiStance: Leveraging Network Interactions to Boost Performance on Stance Detection using Knowledge Graphs
Nov 06, 2020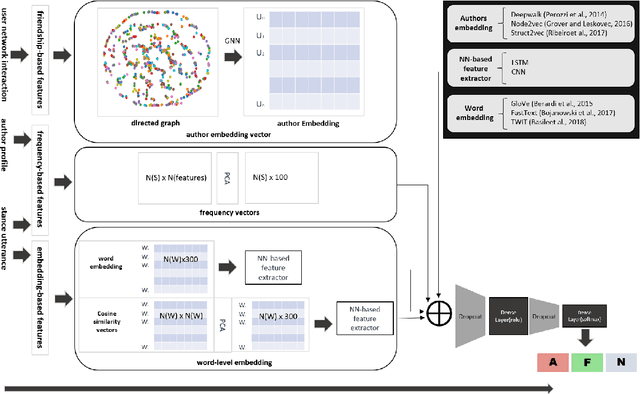
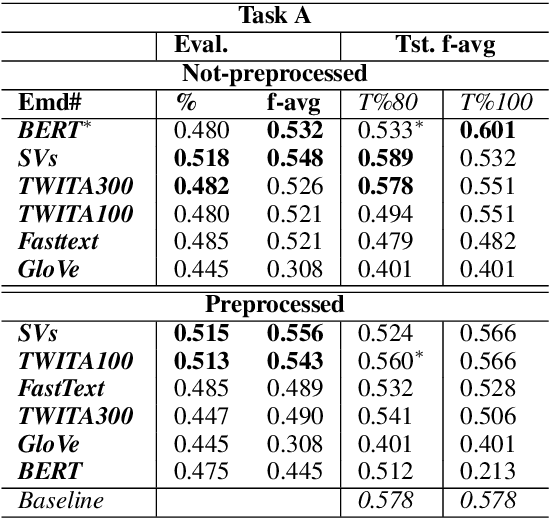
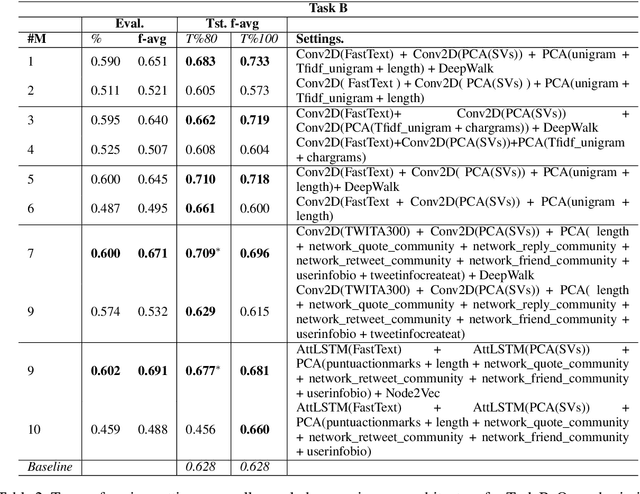
This paper presents our submission to the SardiStance 2020 shared task, describing the architecture used for Task A and Task B. While our submission for Task A did not exceed the baseline, retraining our model using all the training tweets, showed promising results leading to (f-avg 0.601) using bidirectional LSTM with BERT multilingual embedding for Task A. For our submission for Task B, we ranked 6th (f-avg 0.709). With further investigation, our best experimented settings increased performance from (f-avg 0.573) to (f-avg 0.733) with same architecture and parameter settings and after only incorporating social interaction features -- highlighting the impact of social interaction on the model's performance.
QMUL-SDS @ DIACR-Ita: Evaluating Unsupervised Diachronic Lexical Semantics Classification in Italian
Nov 06, 2020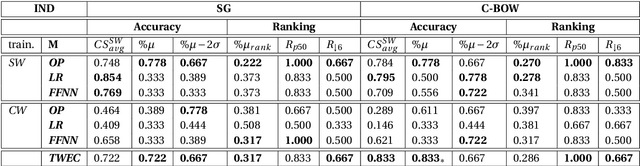
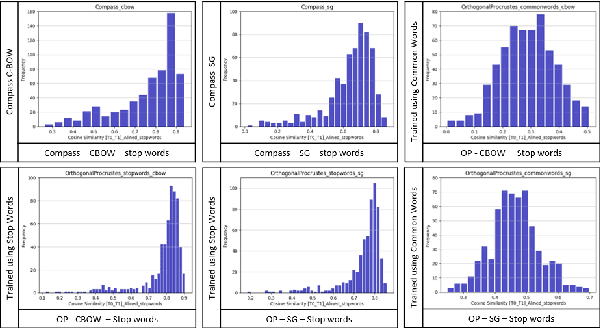
In this paper, we present the results and main findings of our system for the DIACR-ITA 2020 Task. Our system focuses on using variations of training sets and different semantic detection methods. The task involves training, aligning and predicting a word's vector change from two diachronic Italian corpora. We demonstrate that using Temporal Word Embeddings with a Compass C-BOW model is more effective compared to different approaches including Logistic Regression and a Feed Forward Neural Network using accuracy. Our model ranked 3rd with an accuracy of 83.3%.
QMUL-SDS at CheckThat! 2020: Determining COVID-19 Tweet Check-Worthiness Using an Enhanced CT-BERT with Numeric Expressions
Aug 30, 2020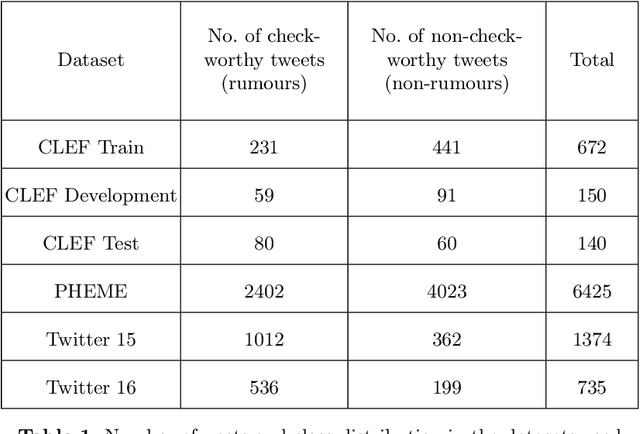
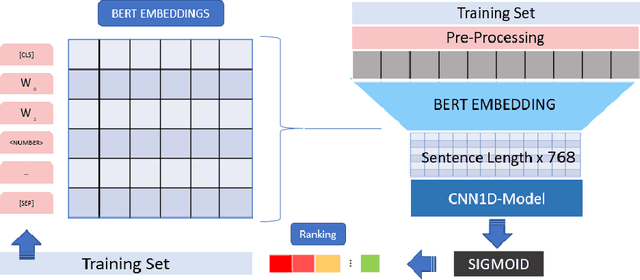
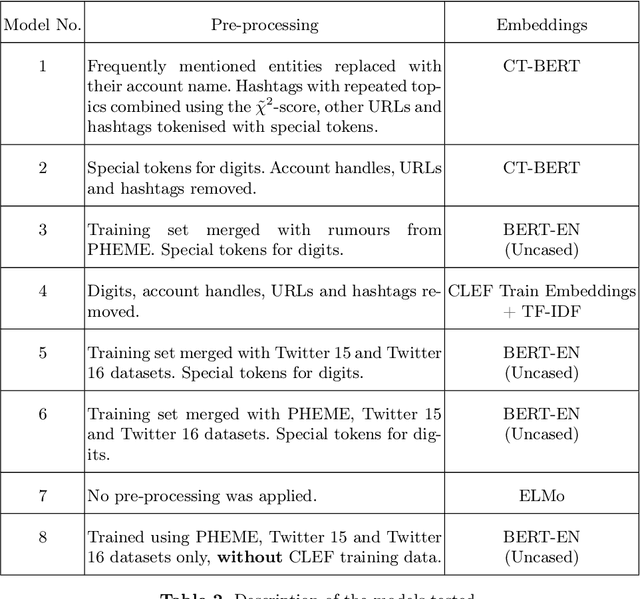
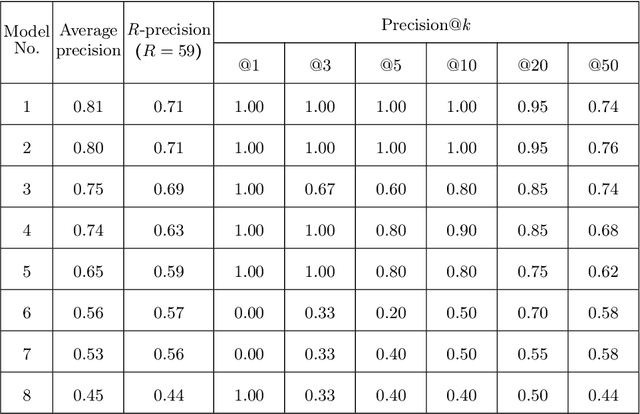
This paper describes the participation of the QMUL-SDS team for Task 1 of the CLEF 2020 CheckThat! shared task. The purpose of this task is to determine the check-worthiness of tweets about COVID-19 to identify and prioritise tweets that need fact-checking. The overarching aim is to further support ongoing efforts to protect the public from fake news and help people find reliable information. We describe and analyse the results of our submissions. We show that a CNN using COVID-Twitter-BERT (CT-BERT) enhanced with numeric expressions can effectively boost performance from baseline results. We also show results of training data augmentation with rumours on other topics. Our best system ranked fourth in the task with encouraging outcomes showing potential for improved results in the future.