 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding for Tomorrow: Assessing the Temporal Persistence of Text Classifiers
Paper and Code
May 19, 2022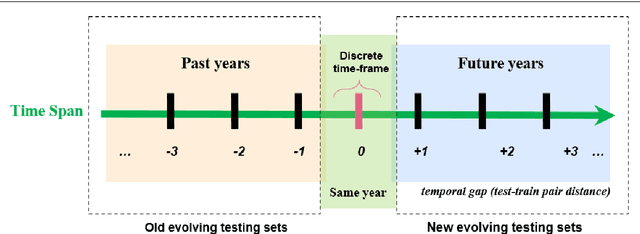
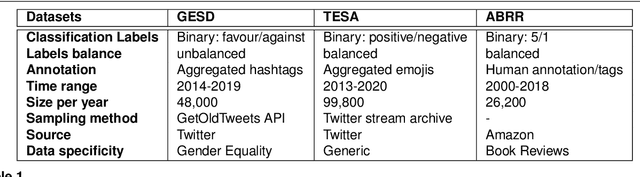
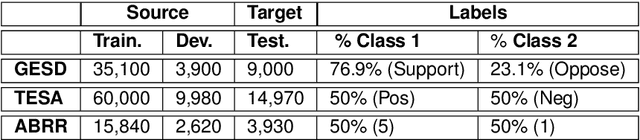
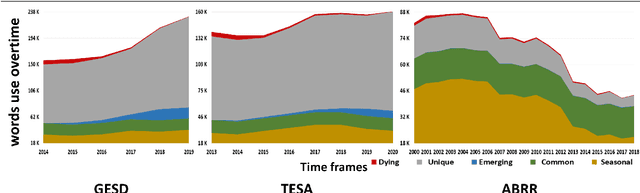
Where performance of text classification models drops over time due to changes in data, development of models whose performance persists over time is important. An ability to predict a model's ability to persist over time can help design models that can be effectively used over a longer period of time. In this paper, we look at this problem from a practical perspective by assessing the ability of a wide range of language models and classification algorithms to persist over time, as well as how dataset characteristics can help predict the temporal stability of different models. We perform longitudinal classification experiments on three datasets spanning between 6 and 19 years, and involving diverse tasks and types of data. We find that one can estimate how a model will retain its performance over time based on (i) how well the model performs over a restricted time period and its extrapolation to a longer time period, and (ii) the linguistic characteristics of the dataset, such as the familiarity score between subsets from different years. Findings from these experiments have important implications for the design of text classification models with the aim of preserving performance over time.