 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe emojification of sentiment on social media: Collection and analysis of a longitudinal Twitter sentiment dataset
Paper and Code


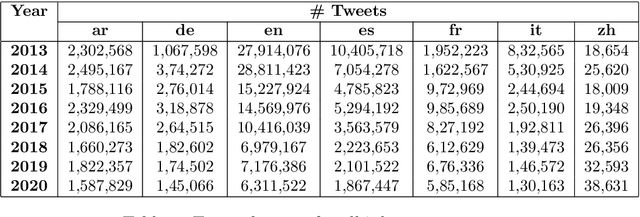

Social media, as a means for computer-mediated communication, has been extensively used to study the sentiment expressed by users around events or topics. There is however a gap in the longitudinal study of how sentiment evolved in social media over the years. To fill this gap, we develop TM-Senti, a new large-scale, distantly supervised Twitter sentiment dataset with over 184 million tweets and covering a time period of over seven years. We describe and assess our methodology to put together a large-scale, emoticon- and emoji-based labelled sentiment analysis dataset, along with an analysis of the resulting dataset. Our analysis highlights interesting temporal changes, among others in the increasing use of emojis over emoticons. We publicly release the dataset for further research in tasks including sentiment analysis and text classification of tweets. The dataset can be fully rehydrated including tweet metadata and without missing tweets thanks to the archive of tweets publicly available on the Internet Archive, which the dataset is based on.