 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep FinResearch Bench: Evaluating AI's Ability to Conduct Professional Financial Investment Research
Apr 22, 2026We introduce Deep FinResearch Bench, a practical and comprehensive evaluation framework for deep research (DR) agents in financial investment research. The benchmark assesses three dimensions of report quality: qualitative rigor, quantitative forecasting and valuation accuracy, and claim credibility and verifiability. Particularly, we define corresponding qualitative and quantitative evaluation metrics and implement an automated scoring procedure to enable scalable assessment. Applying the benchmark to financial reports from frontier DR agents and comparing them with reports authored by financial professionals, we find that AI-generated reports still fall short across these dimensions. These findings underscore the need for domain-specialized DR agents tailored to finance, and we hope the work establishes a foundation for standardized benchmarking of DR agents in financial research.
Distill and Align Decomposition for Enhanced Claim Verification
Feb 25, 2026Complex claim verification requires decomposing sentences into verifiable subclaims, yet existing methods struggle to align decomposition quality with verification performance. We propose a reinforcement learning (RL) approach that jointly optimizes decomposition quality and verifier alignment using Group Relative Policy Optimization (GRPO). Our method integrates: (i) structured sequential reasoning; (ii) supervised finetuning on teacher-distilled exemplars; and (iii) a multi-objective reward balancing format compliance, verifier alignment, and decomposition quality. Across six evaluation settings, our trained 8B decomposer improves downstream verification performance to (71.75%) macro-F1, outperforming prompt-based approaches ((+1.99), (+6.24)) and existing RL methods ((+5.84)). Human evaluation confirms the high quality of the generated subclaims. Our framework enables smaller language models to achieve state-of-the-art claim verification by jointly optimising for verification accuracy and decomposition quality.
ExStrucTiny: A Benchmark for Schema-Variable Structured Information Extraction from Document Images
Feb 12, 2026Enterprise documents, such as forms and reports, embed critical information for downstream applications like data archiving, automated workflows, and analytics. Although generalist Vision Language Models (VLMs) perform well on established document understanding benchmarks, their ability to conduct holistic, fine-grained structured extraction across diverse document types and flexible schemas is not well studied. Existing Key Entity Extraction (KEE), Relation Extraction (RE), and Visual Question Answering (VQA) datasets are limited by narrow entity ontologies, simple queries, or homogeneous document types, often overlooking the need for adaptable and structured extraction. To address these gaps, we introduce ExStrucTiny, a new benchmark dataset for structured Information Extraction (IE) from document images, unifying aspects of KEE, RE, and VQA. Built through a novel pipeline combining manual and synthetic human-validated samples, ExStrucTiny covers more varied document types and extraction scenarios. We analyze open and closed VLMs on this benchmark, highlighting challenges such as schema adaptation, query under-specification, and answer localization. We hope our work provides a bedrock for improving generalist models for structured IE in documents.
A Variational Approach for Mitigating Entity Bias in Relation Extraction
Jun 13, 2025Mitigating entity bias is a critical challenge in Relation Extraction (RE), where models often rely excessively on entities, resulting in poor generalization. This paper presents a novel approach to address this issue by adapting a Variational Information Bottleneck (VIB) framework. Our method compresses entity-specific information while preserving task-relevant features. It achieves state-of-the-art performance on relation extraction datasets across general, financial, and biomedical domains, in both indomain (original test sets) and out-of-domain (modified test sets with type-constrained entity replacements) settings. Our approach offers a robust, interpretable, and theoretically grounded methodology.
FinNLI: Novel Dataset for Multi-Genre Financial Natural Language Inference Benchmarking
Apr 22, 2025We introduce FinNLI, a benchmark dataset for Financial Natural Language Inference (FinNLI) across diverse financial texts like SEC Filings, Annual Reports, and Earnings Call transcripts. Our dataset framework ensures diverse premise-hypothesis pairs while minimizing spurious correlations. FinNLI comprises 21,304 pairs, including a high-quality test set of 3,304 instances annotated by finance experts. Evaluations show that domain shift significantly degrades general-domain NLI performance. The highest Macro F1 scores for pre-trained (PLMs) and large language models (LLMs) baselines are 74.57% and 78.62%, respectively, highlighting the dataset's difficulty. Surprisingly, instruction-tuned financial LLMs perform poorly, suggesting limited generalizability. FinNLI exposes weaknesses in current LLMs for financial reasoning, indicating room for improvement.
Trading Syntax Trees for Wordpieces: Target-oriented Opinion Words Extraction with Wordpieces and Aspect Enhancement
May 18, 2023

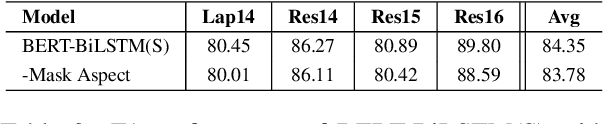

State-of-the-art target-oriented opinion word extraction (TOWE) models typically use BERT-based text encoders that operate on the word level, along with graph convolutional networks (GCNs) that incorporate syntactic information extracted from syntax trees. These methods achieve limited gains with GCNs and have difficulty using BERT wordpieces. Meanwhile, BERT wordpieces are known to be effective at representing rare words or words with insufficient context information. To address this issue, this work trades syntax trees for BERT wordpieces by entirely removing the GCN component from the methods' architectures. To enhance TOWE performance, we tackle the issue of aspect representation loss during encoding. Instead of solely utilizing a sentence as the input, we use a sentence-aspect pair. Our relatively simple approach achieves state-of-the-art results on benchmark datasets and should serve as a strong baseline for further research.
Self-training through Classifier Disagreement for Cross-Domain Opinion Target Extraction
Feb 28, 2023Opinion target extraction (OTE) or aspect extraction (AE) is a fundamental task in opinion mining that aims to extract the targets (or aspects) on which opinions have been expressed. Recent work focus on cross-domain OTE, which is typically encountered in real-world scenarios, where the testing and training distributions differ. Most methods use domain adversarial neural networks that aim to reduce the domain gap between the labelled source and unlabelled target domains to improve target domain performance. However, this approach only aligns feature distributions and does not account for class-wise feature alignment, leading to suboptimal results. Semi-supervised learning (SSL) has been explored as a solution, but is limited by the quality of pseudo-labels generated by the model. Inspired by the theoretical foundations in domain adaptation [2], we propose a new SSL approach that opts for selecting target samples whose model output from a domain-specific teacher and student network disagree on the unlabelled target data, in an effort to boost the target domain performance. Extensive experiments on benchmark cross-domain OTE datasets show that this approach is effective and performs consistently well in settings with large domain shifts.
A Hierarchical N-Gram Framework for Zero-Shot Link Prediction
Apr 16, 2022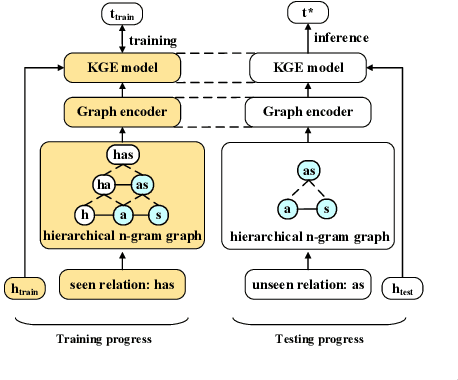
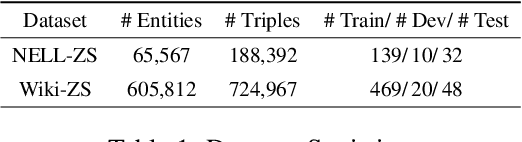
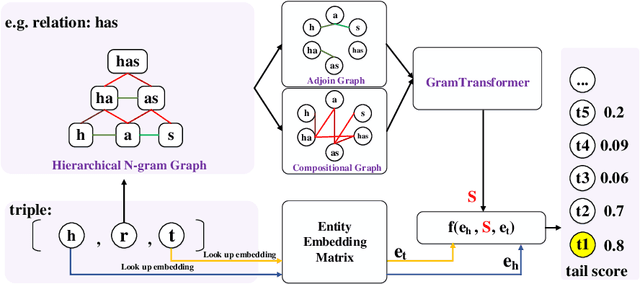
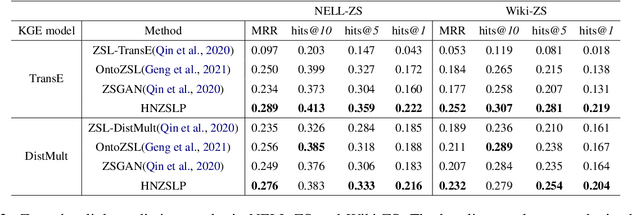
Due to the incompleteness of knowledge graphs (KGs), zero-shot link prediction (ZSLP) which aims to predict unobserved relations in KGs has attracted recent interest from researchers. A common solution is to use textual features of relations (e.g., surface name or textual descriptions) as auxiliary information to bridge the gap between seen and unseen relations. Current approaches learn an embedding for each word token in the text. These methods lack robustness as they suffer from the out-of-vocabulary (OOV) problem. Meanwhile, models built on character n-grams have the capability of generating expressive representations for OOV words. Thus, in this paper, we propose a Hierarchical N-Gram framework for Zero-Shot Link Prediction (HNZSLP), which considers the dependencies among character n-grams of the relation surface name for ZSLP. Our approach works by first constructing a hierarchical n-gram graph on the surface name to model the organizational structure of n-grams that leads to the surface name. A GramTransformer, based on the Transformer is then presented to model the hierarchical n-gram graph to construct the relation embedding for ZSLP. Experimental results show the proposed HNZSLP achieved state-of-the-art performance on two ZSLP datasets.
An Empirical Study on Leveraging Position Embeddings for Target-oriented Opinion Words Extraction
Sep 02, 2021
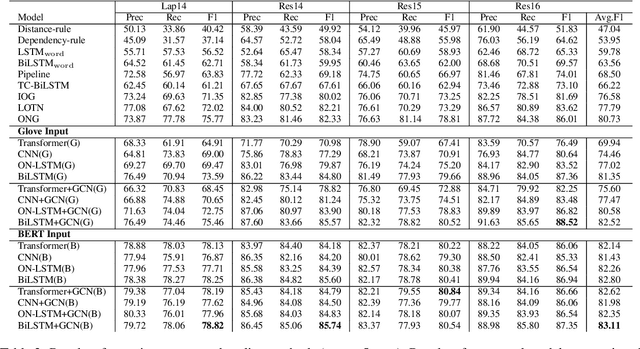

Target-oriented opinion words extraction (TOWE) (Fan et al., 2019b) is a new subtask of target-oriented sentiment analysis that aims to extract opinion words for a given aspect in text. Current state-of-the-art methods leverage position embeddings to capture the relative position of a word to the target. However, the performance of these methods depends on the ability to incorporate this information into word representations. In this paper, we explore a variety of text encoders based on pretrained word embeddings or language models that leverage part-of-speech and position embeddings, aiming to examine the actual contribution of each component in TOWE. We also adapt a graph convolutional network (GCN) to enhance word representations by incorporating syntactic information. Our experimental results demonstrate that BiLSTM-based models can effectively encode position information into word representations while using a GCN only achieves marginal gains. Interestingly, our simple methods outperform several state-of-the-art complex neural structures.
Recurrent Interaction Network for Jointly Extracting Entities and Classifying Relations
May 01, 2020
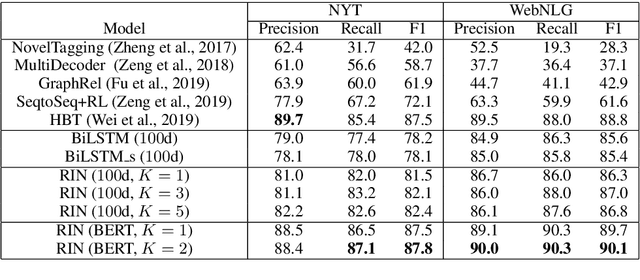
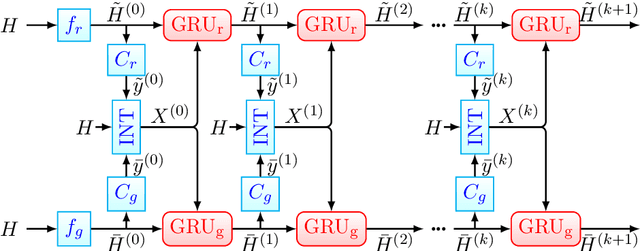
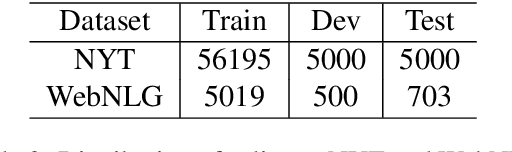
Named entity recognition (NER) and Relation extraction (RE) are two fundamental tasks in natural language processing applications. In practice, these two tasks are often to be solved simultaneously. Traditional multi-task learning models implicitly capture the correlations between NER and RE. However, there exist intrinsic connections between the output of NER and RE. In this study, we argue that an explicit interaction between the NER model and the RE model will better guide the training of both models. Based on the traditional multi-task learning framework, we design an interactive feature encoding method to capture the intrinsic connections between NER and RE tasks. In addition, we propose a recurrent interaction network to progressively capture the correlation between the two models. Empirical studies on two real-world datasets confirm the superiority of the proposed model.