 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Classifier Can Do More: Towards Bridging the Gaps in Classification, Robustness, and Generation
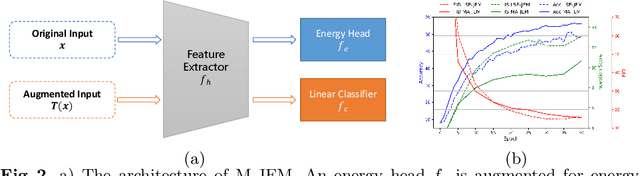
May 26, 2025Joint Energy-based Models (JEMs), a class of hybrid generative-discriminative models, are well known for their ability to achieve both high classification accuracy and generative capability within a single model. However, their robustness still lags significantly behind the classifiers based adversarial training (AT). Conversely, while AT is currently the most effective approach to improving the classifier's robustness, it typically sacrifices accuracy on clean data and lacks generative capability. The triple trade-off between classification accuracy, generative capability and robustness, raises a natural question: Can a single model simultaneously achieve high classification accuracy, adversarial robustness, and generative performance? -- a goal that has been rarely explored. To address this question, we systematically analyze the energy distribution differences of clean, adversarial, and generated samples across various JEM variants and adversarially trained models. We observe that AT tends to reduce the energy gap between clean and adversarial samples, while JEMs reduce the gap between clean and synthetic ones. This observation suggests a key insight: if the energy distributions of all three data types can be aligned, we might unify the strengths of AT and JEMs, resolving their inherent trade-offs. Building on this idea, we propose Energy-based Joint Distribution Adversarial Training (EB-JDAT), to jointly model the clean data distribution, the adversarial distribution, and the classifier by maximizing their joint probability. EB-JDAT is a general and flexible optimization method, compatible with various JEM variants. Extensive experimental results demonstrate that EB-JDAT not only maintains near original accuracy and generative capability of JEMs, but also significantly enhances robustness, even surpassing state-of-the-art ATs.
TransMA: an explainable multi-modal deep learning model for predicting properties of ionizable lipid nanoparticles in mRNA delivery
Jul 08, 2024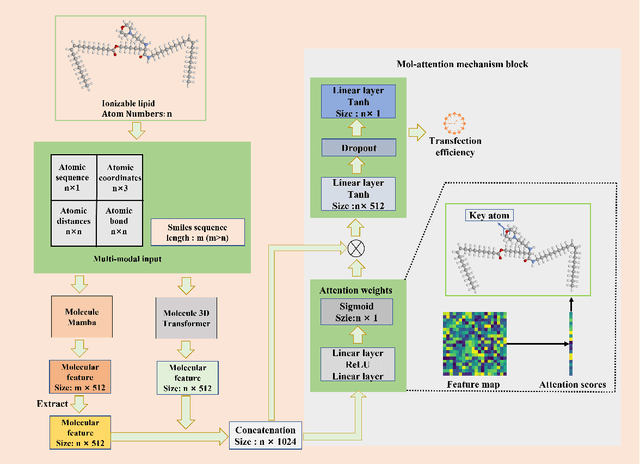
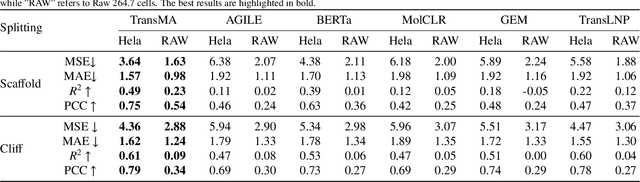


As the primary mRNA delivery vehicles, ionizable lipid nanoparticles (LNPs) exhibit excellent safety, high transfection efficiency, and strong immune response induction. However, the screening process for LNPs is time-consuming and costly. To expedite the identification of high-transfection-efficiency mRNA drug delivery systems, we propose an explainable LNPs transfection efficiency prediction model, called TransMA. TransMA employs a multi-modal molecular structure fusion architecture, wherein the fine-grained atomic spatial relationship extractor named molecule 3D Transformer captures three-dimensional spatial features of the molecule, and the coarse-grained atomic sequence extractor named molecule Mamba captures one-dimensional molecular features. We design the mol-attention mechanism block, enabling it to align coarse and fine-grained atomic features and captures relationships between atomic spatial and sequential structures. TransMA achieves state-of-the-art performance in predicting transfection efficiency using the scaffold and cliff data splitting methods on the current largest LNPs dataset, including Hela and RAW cell lines. Moreover, we find that TransMA captures the relationship between subtle structural changes and significant transfection efficiency variations, providing valuable insights for LNPs design. Additionally, TransMA's predictions on external transfection efficiency data maintain a consistent order with actual transfection efficiencies, demonstrating its robust generalization capability. The code, model and data are made publicly available at https://github.com/wklix/TransMA/tree/master. We hope that high-accuracy transfection prediction models in the future can aid in LNPs design and initial screening, thereby assisting in accelerating the mRNA design process.
M-EBM: Towards Understanding the Manifolds of Energy-Based Models
Mar 08, 2023
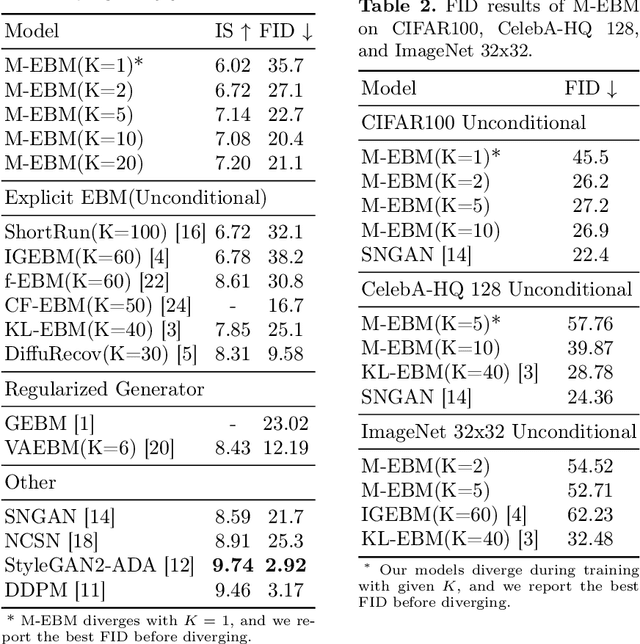

Energy-based models (EBMs) exhibit a variety of desirable properties in predictive tasks, such as generality, simplicity and compositionality. However, training EBMs on high-dimensional datasets remains unstable and expensive. In this paper, we present a Manifold EBM (M-EBM) to boost the overall performance of unconditional EBM and Joint Energy-based Model (JEM). Despite its simplicity, M-EBM significantly improves unconditional EBMs in training stability and speed on a host of benchmark datasets, such as CIFAR10, CIFAR100, CelebA-HQ, and ImageNet 32x32. Once class labels are available, label-incorporated M-EBM (M-JEM) further surpasses M-EBM in image generation quality with an over 40% FID improvement, while enjoying improved accuracy. The code can be found at https://github.com/sndnyang/mebm.
APSNet: Attention Based Point Cloud Sampling
Oct 11, 2022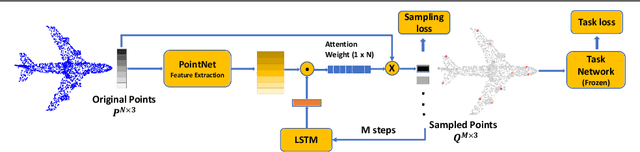
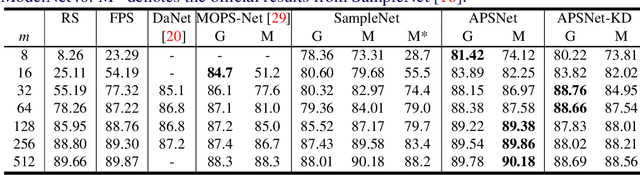
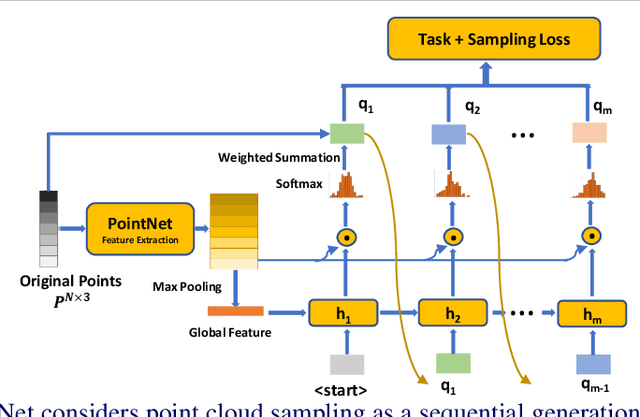
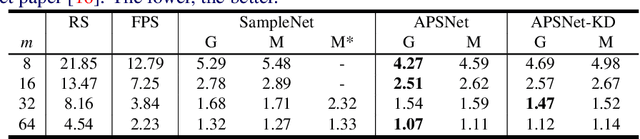
Processing large point clouds is a challenging task. Therefore, the data is often downsampled to a smaller size such that it can be stored, transmitted and processed more efficiently without incurring significant performance degradation. Traditional task-agnostic sampling methods, such as farthest point sampling (FPS), do not consider downstream tasks when sampling point clouds, and thus non-informative points to the tasks are often sampled. This paper explores a task-oriented sampling for 3D point clouds, and aims to sample a subset of points that are tailored specifically to a downstream task of interest. Similar to FPS, we assume that point to be sampled next should depend heavily on the points that have already been sampled. We thus formulate point cloud sampling as a sequential generation process, and develop an attention-based point cloud sampling network (APSNet) to tackle this problem. At each time step, APSNet attends to all the points in a cloud by utilizing the history of previously sampled points, and samples the most informative one. Both supervised learning and knowledge distillation-based self-supervised learning of APSNet are proposed. Moreover, joint training of APSNet over multiple sample sizes is investigated, leading to a single APSNet that can generate arbitrary length of samples with prominent performances. Extensive experiments demonstrate the superior performance of APSNet against state-of-the-arts in various downstream tasks, including 3D point cloud classification, reconstruction, and registration.
Towards Bridging the Performance Gaps of Joint Energy-based Models
Sep 16, 2022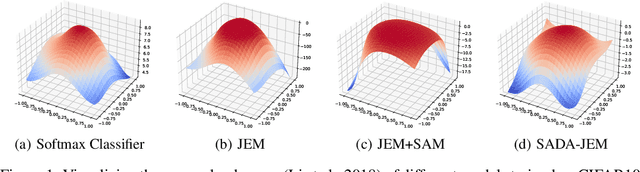

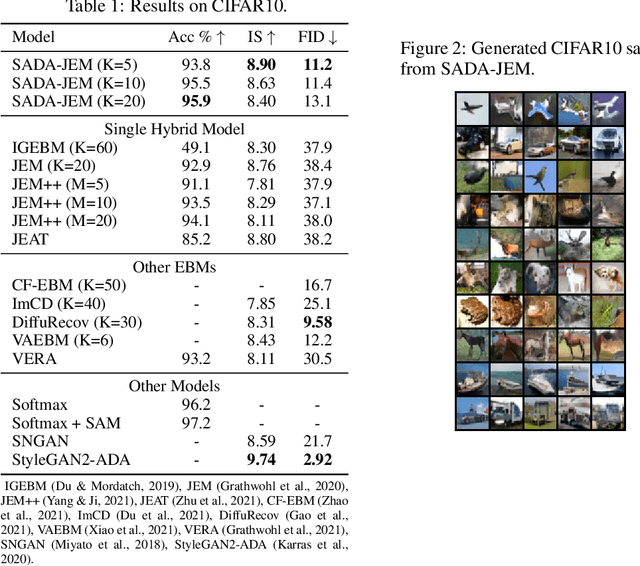
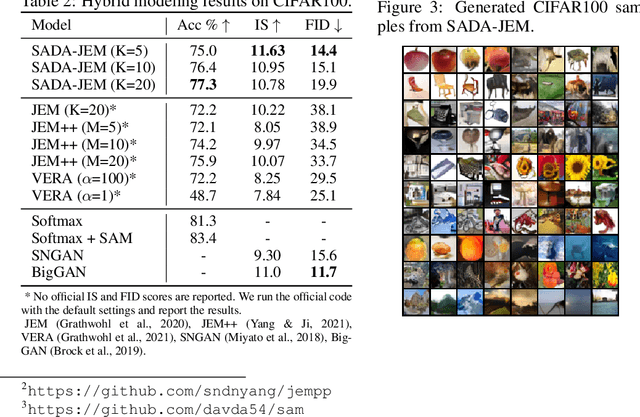
Can we train a hybrid discriminative-generative model within a single network? This question has recently been answered in the affirmative, introducing the field of Joint Energy-based Model (JEM), which achieves high classification accuracy and image generation quality simultaneously. Despite recent advances, there remain two performance gaps: the accuracy gap to the standard softmax classifier, and the generation quality gap to state-of-the-art generative models. In this paper, we introduce a variety of training techniques to bridge the accuracy gap and the generation quality gap of JEM. 1) We incorporate a recently proposed sharpness-aware minimization (SAM) framework to train JEM, which promotes the energy landscape smoothness and the generalizability of JEM. 2) We exclude data augmentation from the maximum likelihood estimate pipeline of JEM, and mitigate the negative impact of data augmentation to image generation quality. Extensive experiments on multiple datasets demonstrate that our SADA-JEM achieves state-of-the-art performances and outperforms JEM in image classification, image generation, calibration, out-of-distribution detection and adversarial robustness by a notable margin.
Your ViT is Secretly a Hybrid Discriminative-Generative Diffusion Model
Aug 16, 2022
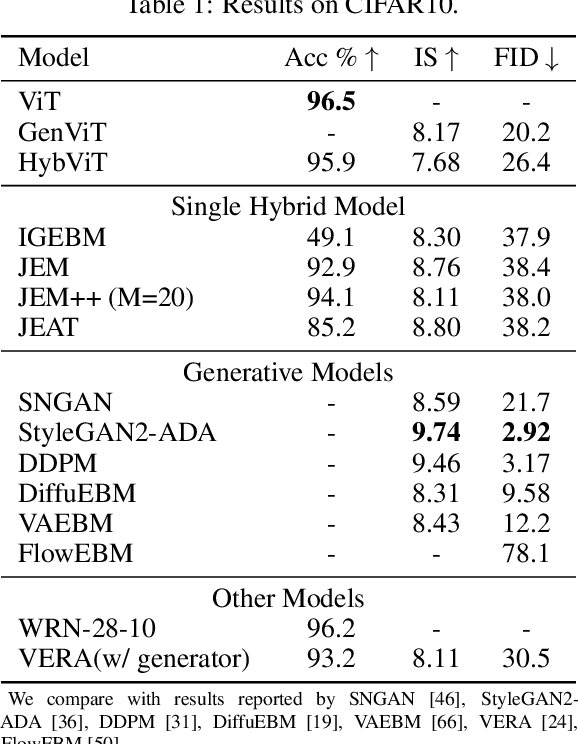
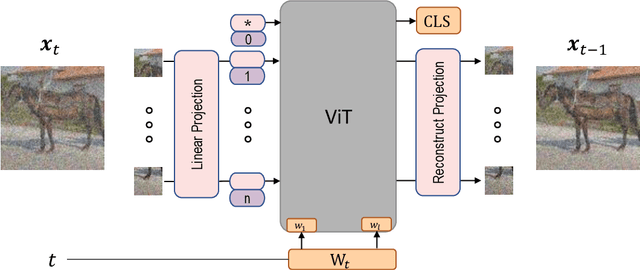
Diffusion Denoising Probability Models (DDPM) and Vision Transformer (ViT) have demonstrated significant progress in generative tasks and discriminative tasks, respectively, and thus far these models have largely been developed in their own domains. In this paper, we establish a direct connection between DDPM and ViT by integrating the ViT architecture into DDPM, and introduce a new generative model called Generative ViT (GenViT). The modeling flexibility of ViT enables us to further extend GenViT to hybrid discriminative-generative modeling, and introduce a Hybrid ViT (HybViT). Our work is among the first to explore a single ViT for image generation and classification jointly. We conduct a series of experiments to analyze the performance of proposed models and demonstrate their superiority over prior state-of-the-arts in both generative and discriminative tasks. Our code and pre-trained models can be found in https://github.com/sndnyang/Diffusion_ViT .
A Hierarchical N-Gram Framework for Zero-Shot Link Prediction
Apr 16, 2022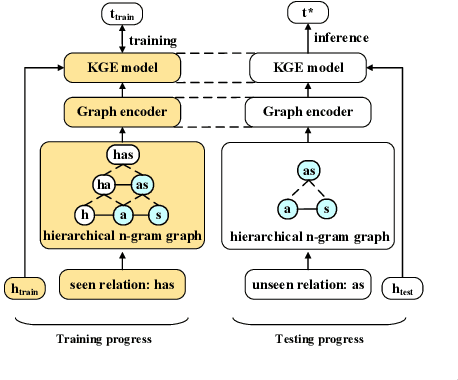
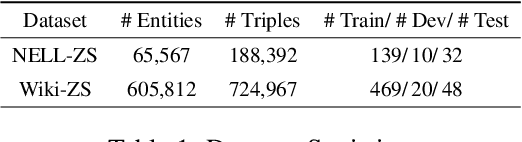
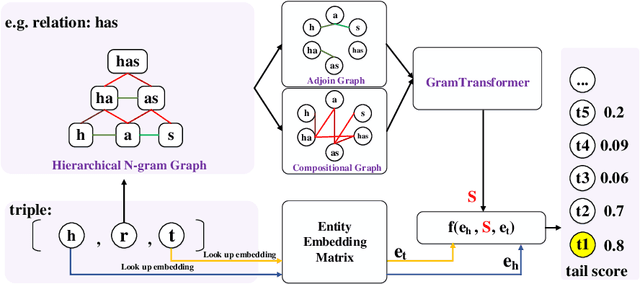
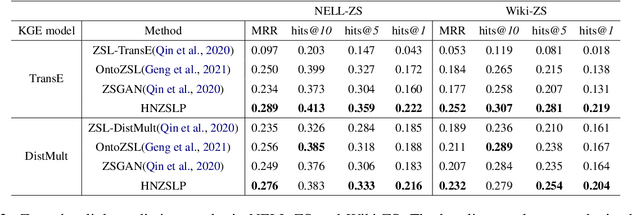
Due to the incompleteness of knowledge graphs (KGs), zero-shot link prediction (ZSLP) which aims to predict unobserved relations in KGs has attracted recent interest from researchers. A common solution is to use textual features of relations (e.g., surface name or textual descriptions) as auxiliary information to bridge the gap between seen and unseen relations. Current approaches learn an embedding for each word token in the text. These methods lack robustness as they suffer from the out-of-vocabulary (OOV) problem. Meanwhile, models built on character n-grams have the capability of generating expressive representations for OOV words. Thus, in this paper, we propose a Hierarchical N-Gram framework for Zero-Shot Link Prediction (HNZSLP), which considers the dependencies among character n-grams of the relation surface name for ZSLP. Our approach works by first constructing a hierarchical n-gram graph on the surface name to model the organizational structure of n-grams that leads to the surface name. A GramTransformer, based on the Transformer is then presented to model the hierarchical n-gram graph to construct the relation embedding for ZSLP. Experimental results show the proposed HNZSLP achieved state-of-the-art performance on two ZSLP datasets.
JEM++: Improved Techniques for Training JEM
Sep 21, 2021
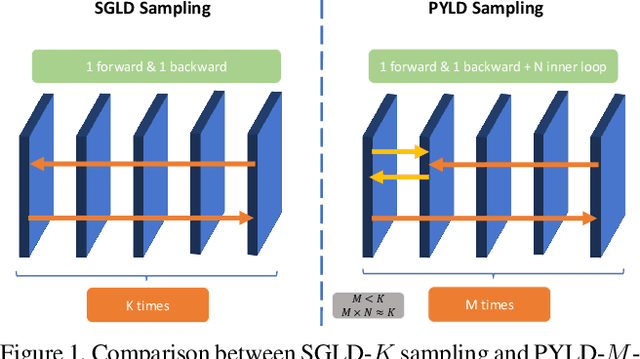

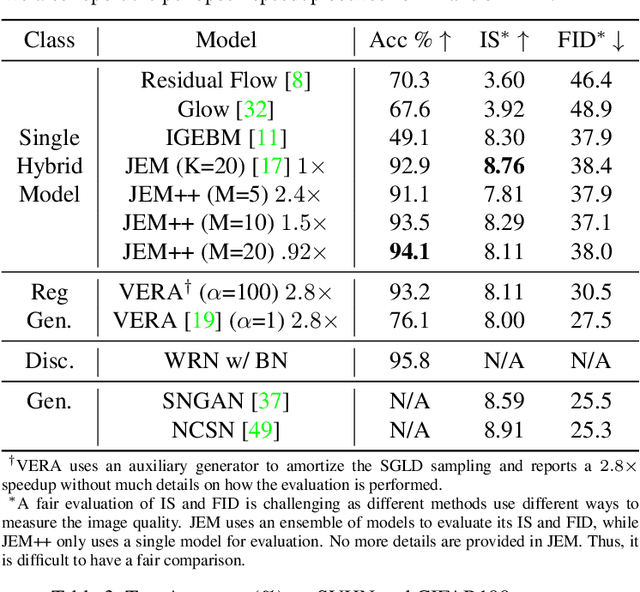
Joint Energy-based Model (JEM) is a recently proposed hybrid model that retains strong discriminative power of modern CNN classifiers, while generating samples rivaling the quality of GAN-based approaches. In this paper, we propose a variety of new training procedures and architecture features to improve JEM's accuracy, training stability, and speed altogether. 1) We propose a proximal SGLD to generate samples in the proximity of samples from the previous step, which improves the stability. 2) We further treat the approximate maximum likelihood learning of EBM as a multi-step differential game, and extend the YOPO framework to cut out redundant calculations during backpropagation, which accelerates the training substantially. 3) Rather than initializing SGLD chain from random noise, we introduce a new informative initialization that samples from a distribution estimated from training data. 4) This informative initialization allows us to enable batch normalization in JEM, which further releases the power of modern CNN architectures for hybrid modeling. Code: https://github.com/sndnyang/JEMPP
Improving Text-to-Image Synthesis Using Contrastive Learning
Jul 06, 2021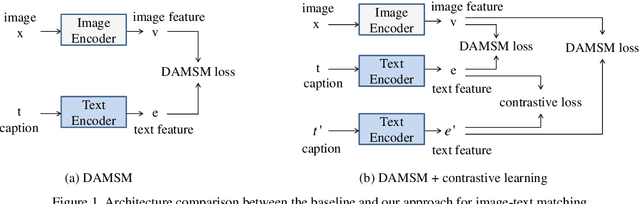
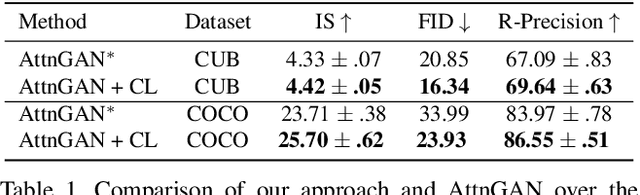
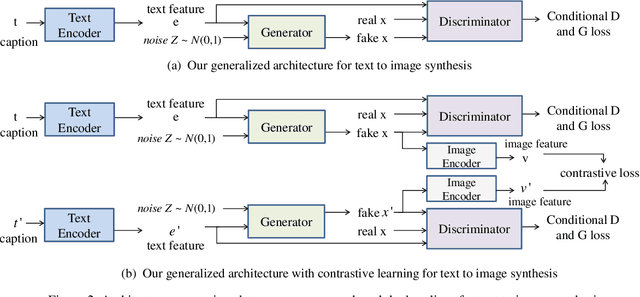

The goal of text-to-image synthesis is to generate a visually realistic image that matches a given text description. In practice, the captions annotated by humans for the same image have large variance in terms of contents and the choice of words. The linguistic discrepancy between the captions of the identical image leads to the synthetic images deviating from the ground truth. To address this issue, we propose a contrastive learning approach to improve the quality and enhance the semantic consistency of synthetic images. In the pre-training stage, we utilize the contrastive learning approach to learn the consistent textual representations for the captions corresponding to the same image. Furthermore, in the following stage of GAN training, we employ the contrastive learning method to enhance the consistency between the generated images from the captions related to the same image. We evaluate our approach over two popular text-to-image synthesis models, AttnGAN and DM-GAN, on datasets CUB and COCO, respectively. Experimental results have shown that our approach can effectively improve the quality of synthetic images in terms of three metrics: IS, FID and R-precision. Especially, on the challenging COCO dataset, our approach boosts the FID significantly by 29.60% over AttnGAn and by 21.96% over DM-GAN.
Generative Max-Mahalanobis Classifiers for Image Classification, Generation and More
Jan 01, 2021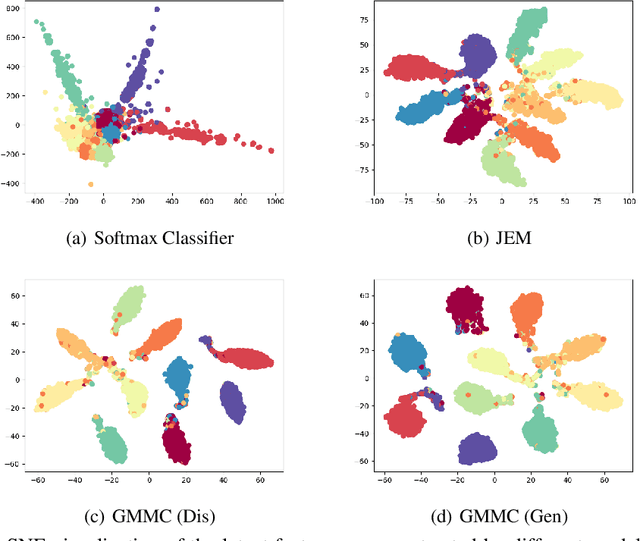
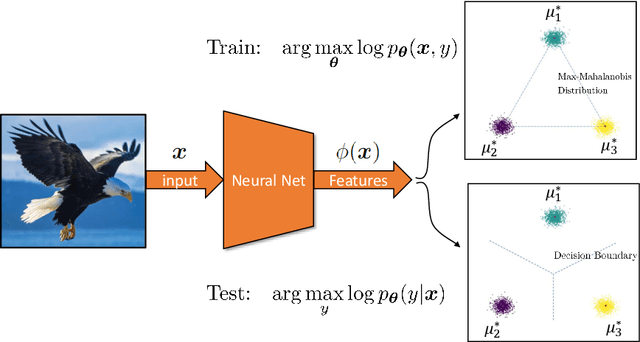

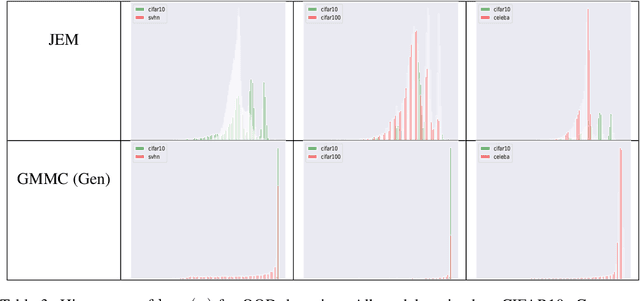
Joint Energy-based Model (JEM) of~\cite{jem} shows that a standard softmax classifier can be reinterpreted as an energy-based model (EBM) for the joint distribution $p(\boldsymbol{x}, y)$; the resulting model can be optimized with an energy-based training to improve calibration, robustness and out-of-distribution detection, while generating samples rivaling the quality of recent GAN-based approaches. However, the softmax classifier that JEM exploits is inherently discriminative and its latent feature space is not well formulated as probabilistic distributions, which may hinder its potential for image generation and incur training instability as observed in~\cite{jem}. We hypothesize that generative classifiers, such as Linear Discriminant Analysis (LDA), might be more suitable hybrid models for image generation since generative classifiers model the data generation process explicitly. This paper therefore investigates an LDA classifier for image classification and generation. In particular, the Max-Mahalanobis Classifier (MMC)~\cite{Pang2020Rethinking}, a special case of LDA, fits our goal very well since MMC formulates the latent feature space explicitly as the Max-Mahalanobis distribution~\cite{pang2018max}. We term our algorithm Generative MMC (GMMC), and show that it can be trained discriminatively, generatively or jointly for image classification and generation. Extensive experiments on multiple datasets (CIFAR10, CIFAR100 and SVHN) show that GMMC achieves state-of-the-art discriminative and generative performances, while outperforming JEM in calibration, adversarial robustness and out-of-distribution detection by a significant margin.