 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized Transport Alignment for Multimodal and Multiview E-commerce Representation Learning
Dec 19, 2025The rapid growth of e-commerce requires robust multimodal representations that capture diverse signals from user-generated listings. Existing vision-language models (VLMs) typically align titles with primary images, i.e., single-view, but overlook non-primary images and auxiliary textual views that provide critical semantics in open marketplaces such as Etsy or Poshmark. To this end, we propose a framework that unifies multimodal and multi-view learning through Factorized Transport, a lightweight approximation of optimal transport, designed for scalability and deployment efficiency. During training, the method emphasizes primary views while stochastically sampling auxiliary ones, reducing training cost from quadratic in the number of views to constant per item. At inference, all views are fused into a single cached embedding, preserving the efficiency of two-tower retrieval with no additional online overhead. On an industrial dataset of 1M product listings and 0.3M interactions, our approach delivers consistent improvements in cross-view and query-to-item retrieval, achieving up to +7.9% Recall@500 over strong multimodal baselines. Overall, our framework bridges scalability with optimal transport-based learning, making multi-view pretraining practical for large-scale e-commerce search.
SEQ+MD: Learning Multi-Task as a SEQuence with Multi-Distribution Data
Aug 23, 2024



In e-commerce, the order in which search results are displayed when a customer tries to find relevant listings can significantly impact their shopping experience and search efficiency. Tailored re-ranking system based on relevance and engagement signals in E-commerce has often shown improvement on sales and gross merchandise value (GMV). Designing algorithms for this purpose is even more challenging when the shops are not restricted to domestic buyers, but can sale globally to international buyers. Our solution needs to incorporate shopping preference and cultural traditions in different buyer markets. We propose the SEQ+MD framework, which integrates sequential learning for multi-task learning (MTL) and feature-generated region-mask for multi-distribution input. This approach leverages the sequential order within tasks and accounts for regional heterogeneity, enhancing performance on multi-source data. Evaluations on in-house data showed a strong increase on the high-value engagement including add-to-cart and purchase while keeping click performance neutral compared to state-of-the-art baseline models. Additionally, our multi-regional learning module is "plug-and-play" and can be easily adapted to enhance other MTL applications.
Fairness-aware Differentially Private Collaborative Filtering
Mar 16, 2023Recently, there has been an increasing adoption of differential privacy guided algorithms for privacy-preserving machine learning tasks. However, the use of such algorithms comes with trade-offs in terms of algorithmic fairness, which has been widely acknowledged. Specifically, we have empirically observed that the classical collaborative filtering method, trained by differentially private stochastic gradient descent (DP-SGD), results in a disparate impact on user groups with respect to different user engagement levels. This, in turn, causes the original unfair model to become even more biased against inactive users. To address the above issues, we propose \textbf{DP-Fair}, a two-stage framework for collaborative filtering based algorithms. Specifically, it combines differential privacy mechanisms with fairness constraints to protect user privacy while ensuring fair recommendations. The experimental results, based on Amazon datasets, and user history logs collected from Etsy, one of the largest e-commerce platforms, demonstrate that our proposed method exhibits superior performance in terms of both overall accuracy and user group fairness on both shallow and deep recommendation models compared to vanilla DP-SGD.
Your ViT is Secretly a Hybrid Discriminative-Generative Diffusion Model
Aug 16, 2022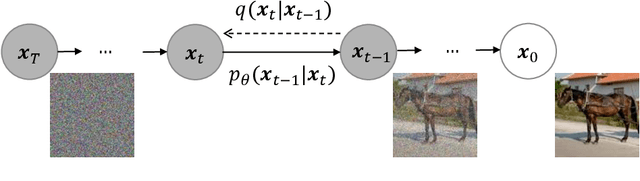
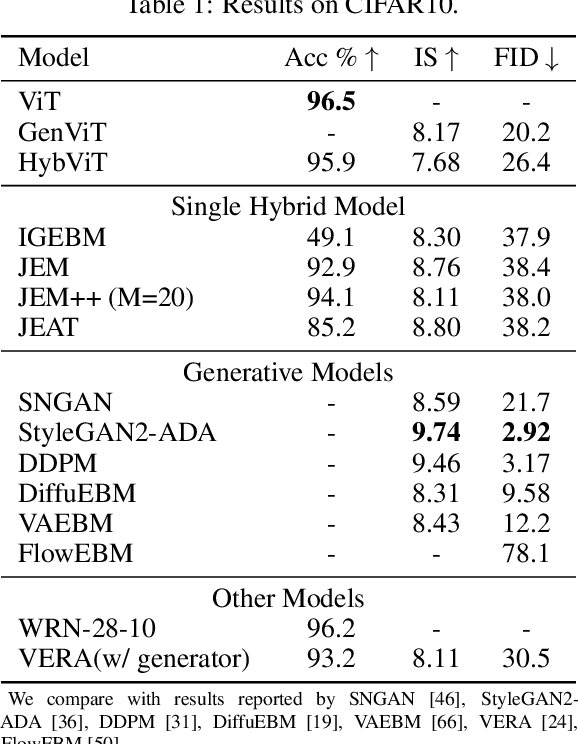
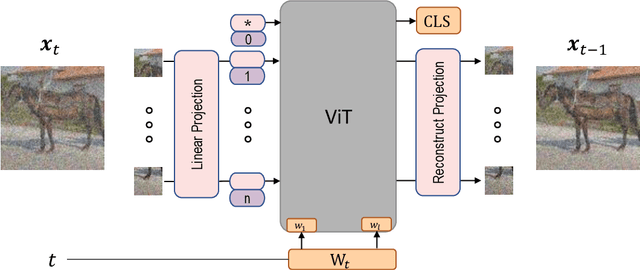
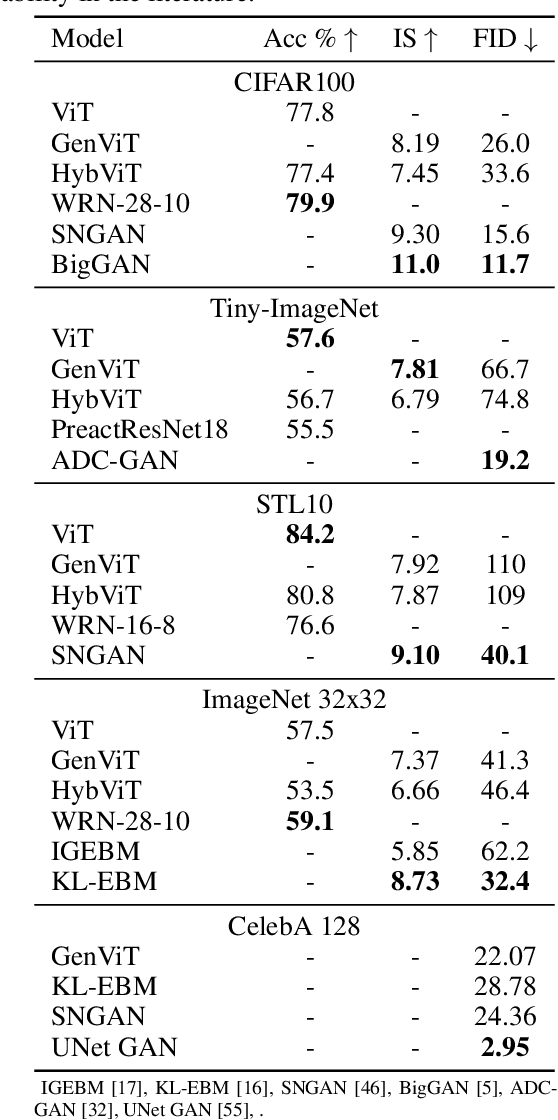
Diffusion Denoising Probability Models (DDPM) and Vision Transformer (ViT) have demonstrated significant progress in generative tasks and discriminative tasks, respectively, and thus far these models have largely been developed in their own domains. In this paper, we establish a direct connection between DDPM and ViT by integrating the ViT architecture into DDPM, and introduce a new generative model called Generative ViT (GenViT). The modeling flexibility of ViT enables us to further extend GenViT to hybrid discriminative-generative modeling, and introduce a Hybrid ViT (HybViT). Our work is among the first to explore a single ViT for image generation and classification jointly. We conduct a series of experiments to analyze the performance of proposed models and demonstrate their superiority over prior state-of-the-arts in both generative and discriminative tasks. Our code and pre-trained models can be found in https://github.com/sndnyang/Diffusion_ViT .
Toward Pareto Efficient Fairness-Utility Trade-off inRecommendation through Reinforcement Learning
Jan 01, 2022

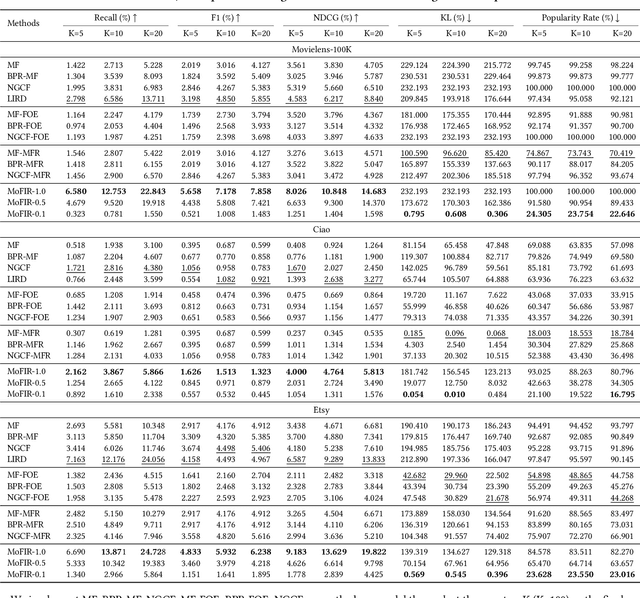
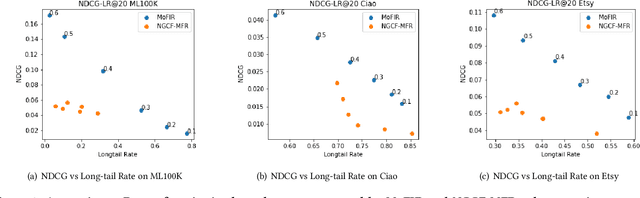
The issue of fairness in recommendation is becoming increasingly essential as Recommender Systems touch and influence more and more people in their daily lives. In fairness-aware recommendation, most of the existing algorithmic approaches mainly aim at solving a constrained optimization problem by imposing a constraint on the level of fairness while optimizing the main recommendation objective, e.g., CTR. While this alleviates the impact of unfair recommendations, the expected return of an approach may significantly compromise the recommendation accuracy due to the inherent trade-off between fairness and utility. This motivates us to deal with these conflicting objectives and explore the optimal trade-off between them in recommendation. One conspicuous approach is to seek a Pareto efficient solution to guarantee optimal compromises between utility and fairness. Moreover, considering the needs of real-world e-commerce platforms, it would be more desirable if we can generalize the whole Pareto Frontier, so that the decision-makers can specify any preference of one objective over another based on their current business needs. Therefore, in this work, we propose a fairness-aware recommendation framework using multi-objective reinforcement learning, called MoFIR, which is able to learn a single parametric representation for optimal recommendation policies over the space of all possible preferences. Specially, we modify traditional DDPG by introducing conditioned network into it, which conditions the networks directly on these preferences and outputs Q-value-vectors. Experiments on several real-world recommendation datasets verify the superiority of our framework on both fairness metrics and recommendation measures when compared with all other baselines. We also extract the approximate Pareto Frontier on real-world datasets generated by MoFIR and compare to state-of-the-art fairness methods.
Learning Item-Interaction Embeddings for User Recommendations
Dec 11, 2018
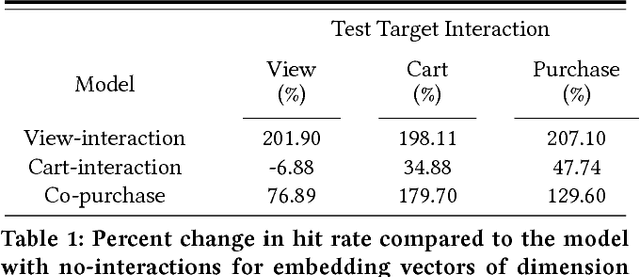
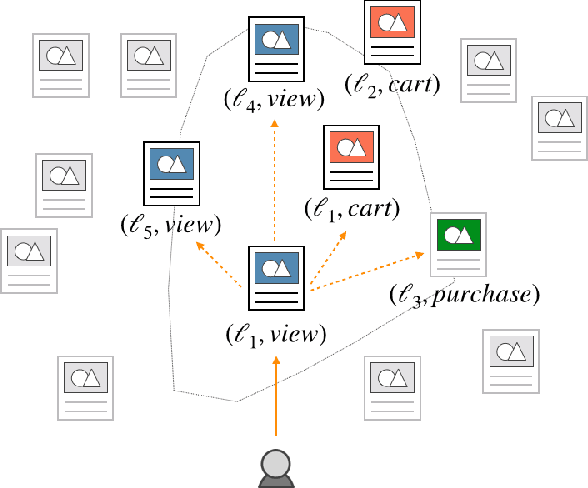
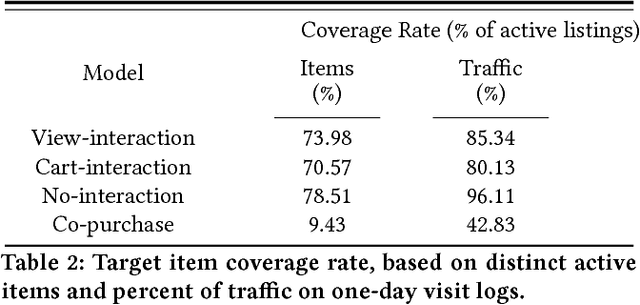
Industry-scale recommendation systems have become a cornerstone of the e-commerce shopping experience. For Etsy, an online marketplace with over 50 million handmade and vintage items, users come to rely on personalized recommendations to surface relevant items from its massive inventory. One hallmark of Etsy's shopping experience is the multitude of ways in which a user can interact with an item they are interested in: they can view it, favorite it, add it to a collection, add it to cart, purchase it, etc. We hypothesize that the different ways in which a user interacts with an item indicates different kinds of intent. Consequently, a user's recommendations should be based not only on the item from their past activity, but also the way in which they interacted with that item. In this paper, we propose a novel method for learning interaction-based item embeddings that encode the co-occurrence patterns of not only the item itself, but also the interaction type. The learned embeddings give us a convenient way of approximating the likelihood that one item-interaction pair would co-occur with another by way of a simple inner product. Because of its computational efficiency, our model lends itself naturally as a candidate set selection method, and we evaluate it as such in an industry-scale recommendation system that serves live traffic on Etsy.com. Our experiments reveal that taking interaction type into account shows promising results in improving the accuracy of modeling user shopping behavior.
Clustering via Content-Augmented Stochastic Blockmodels
May 25, 2015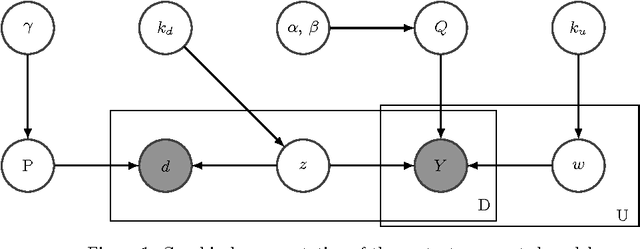

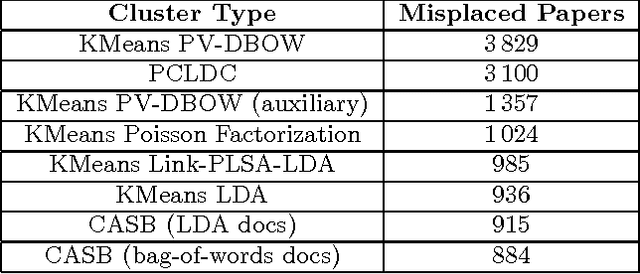

Much of the data being created on the web contains interactions between users and items. Stochastic blockmodels, and other methods for community detection and clustering of bipartite graphs, can infer latent user communities and latent item clusters from this interaction data. These methods, however, typically ignore the items' contents and the information they provide about item clusters, despite the tendency of items in the same latent cluster to share commonalities in content. We introduce content-augmented stochastic blockmodels (CASB), which use item content together with user-item interaction data to enhance the user communities and item clusters learned. Comparisons to several state-of-the-art benchmark methods, on datasets arising from scientists interacting with scientific articles, show that content-augmented stochastic blockmodels provide highly accurate clusters with respect to metrics representative of the underlying community structure.
A Markov Decision Process Analysis of the Cold Start Problem in Bayesian Information Filtering
Oct 29, 2014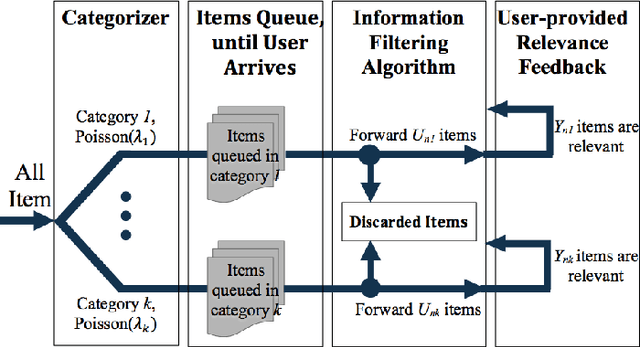


We consider the information filtering problem, in which we face a stream of items, and must decide which ones to forward to a user to maximize the number of relevant items shown, minus a penalty for each irrelevant item shown. Forwarding decisions are made separately in a personalized way for each user. We focus on the cold-start setting for this problem, in which we have limited historical data on the user's preferences, and must rely on feedback from forwarded articles to learn which the fraction of items relevant to the user in each of several item categories. Performing well in this setting requires trading exploration vs. exploitation, forwarding items that are likely to be irrelevant, to allow learning that will improve later performance. In a Bayesian setting, and using Markov decision processes, we show how the Bayes-optimal forwarding algorithm can be computed efficiently when the user will examine each forwarded article, and how an upper bound on the Bayes-optimal procedure and a heuristic index policy can be obtained for the setting when the user will examine only a limited number of forwarded items. We present results from simulation experiments using parameters estimated using historical data from arXiv.org.