 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Subgraph Matching with Neural Graph Representations and Reinforcement Learning
Mar 18, 2026Approximate subgraph matching (ASM) is a task that determines the approximate presence of a given query graph in a large target graph. Being an NP-hard problem, ASM is critical in graph analysis with a myriad of applications ranging from database systems and network science to biochemistry and privacy. Existing techniques often employ heuristic search strategies, which cannot fully utilize the graph information, leading to sub-optimal solutions. This paper proposes a Reinforcement Learning based Approximate Subgraph Matching (RL-ASM) algorithm that exploits graph transformers to effectively extract graph representations and RL-based policies for ASM. Our model is built upon the branch-and-bound algorithm that selects one pair of nodes from the two input graphs at a time for potential matches. Instead of using heuristics, we exploit a Graph Transformer architecture to extract feature representations that encode the full graph information. To enhance the training of the RL policy, we use supervised signals to guide our agent in an imitation learning stage. Subsequently, the policy is fine-tuned with the Proximal Policy Optimization (PPO) that optimizes the accumulative long-term rewards over episodes. Extensive experiments on both synthetic and real-world datasets demonstrate that our RL-ASM outperforms existing methods in terms of effectiveness and efficiency. Our source code is available at https://github.com/KaiyangLi1992/RL-ASM.
OpenGrok: Enhancing SNS Data Processing with Distilled Knowledge and Mask-like Mechanisms
Feb 11, 2025This report details Lumen Labs' novel approach to processing Social Networking Service (SNS) data. We leverage knowledge distillation, specifically a simple distillation method inspired by DeepSeek-R1's CoT acquisition, combined with prompt hacking, to extract valuable training data from the Grok model. This data is then used to fine-tune a Phi-3-mini model, augmented with a mask-like mechanism specifically designed for handling the nuances of SNS data. Our method demonstrates state-of-the-art (SOTA) performance on several SNS data processing tasks, outperforming existing models like Grok, Phi-3, and GPT-4. We provide a comprehensive analysis of our approach, including mathematical formulations, engineering details, ablation studies, and comparative evaluations.
Enhancing Large Language Model Efficiencyvia Symbolic Compression: A Formal Approach Towards Interpretability
Jan 30, 2025
Large language models (LLMs) face significant token efficiency bottlenecks in code generation and logical reasoning tasks, a challenge that directly impacts inference cost and model interpretability. This paper proposes a formal framework based on symbolic compression,integrating combinatory logic, information-theoretic optimal encoding, and context-aware inference techniques to achieve a step-change improvement in token efficiency while preserving semantic integrity. We establish a mathematical framework within a functional programming paradigm, derive the quantitative relationship between symbolic density and model interpretability, and propose a differentiable compression factor metric to evaluate encoding efficiency. Furthermore, we leverage parameter-efficient fine-tuning (PEFT) techniques to achieve a low-cost application of the GAEL language. Experimental results show that this method achieves a 78.3% token compression rate in code generation tasks while improving logical traceability by 62% through structural explicitness. This research provides new theoretical tools for efficient inference in LLMs and opens a symbolic path for modelinterpretability research.
Chinese Stock Prediction Based on a Multi-Modal Transformer Framework: Macro-Micro Information Fusion
Jan 28, 2025



This paper proposes an innovative Multi-Modal Transformer framework (MMF-Trans) designed to significantly improve the prediction accuracy of the Chinese stock market by integrating multi-source heterogeneous information including macroeconomy, micro-market, financial text, and event knowledge. The framework consists of four core modules: (1) A four-channel parallel encoder that processes technical indicators, financial text, macro data, and event knowledge graph respectively for independent feature extraction of multi-modal data; (2) A dynamic gated cross-modal fusion mechanism that adaptively learns the importance of different modalities through differentiable weight allocation for effective information integration; (3) A time-aligned mixed-frequency processing layer that uses an innovative position encoding method to effectively fuse data of different time frequencies and solves the time alignment problem of heterogeneous data; (4) A graph attention-based event impact quantification module that captures the dynamic impact of events on the market through event knowledge graph and quantifies the event impact coefficient. We introduce a hybrid-frequency Transformer and Event2Vec algorithm to effectively fuse data of different frequencies and quantify the event impact. Experimental results show that in the prediction task of CSI 300 constituent stocks, the root mean square error (RMSE) of the MMF-Trans framework is reduced by 23.7% compared to the baseline model, the event response prediction accuracy is improved by 41.2%, and the Sharpe ratio is improved by 32.6%.
UAV3D: A Large-scale 3D Perception Benchmark for Unmanned Aerial Vehicles
Oct 14, 2024

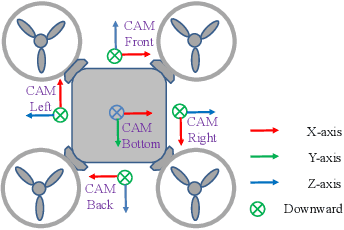

Unmanned Aerial Vehicles (UAVs), equipped with cameras, are employed in numerous applications, including aerial photography, surveillance, and agriculture. In these applications, robust object detection and tracking are essential for the effective deployment of UAVs. However, existing benchmarks for UAV applications are mainly designed for traditional 2D perception tasks, restricting the development of real-world applications that require a 3D understanding of the environment. Furthermore, despite recent advancements in single-UAV perception, limited views of a single UAV platform significantly constrain its perception capabilities over long distances or in occluded areas. To address these challenges, we introduce UAV3D, a benchmark designed to advance research in both 3D and collaborative 3D perception tasks with UAVs. UAV3D comprises 1,000 scenes, each of which has 20 frames with fully annotated 3D bounding boxes on vehicles. We provide the benchmark for four 3D perception tasks: single-UAV 3D object detection, single-UAV object tracking, collaborative-UAV 3D object detection, and collaborative-UAV object tracking. Our dataset and code are available at https://huiyegit.github.io/UAV3D_Benchmark/.
Unsqueeze [CLS] Bottleneck to Learn Rich Representations
Jul 26, 2024Distillation-based self-supervised learning typically leads to more compressed representations due to its radical clustering process and the implementation of a sharper target distribution. To overcome this limitation and preserve more information from input, we introduce UDI, conceptualized as Unsqueezed Distillation-based self-supervised learning (SSL). UDI enriches the learned representation by encouraging multimodal prediction distilled from a consolidated profile of local predictions that are derived via stratified sampling. Our evaluations show that UDI not only promotes semantically meaningful representations at instance level, delivering superior or competitive results to state-of-the-art SSL methods in image classification, but also effectively preserves the nuisance of input, which yields significant improvement in dense prediction tasks, including object detection and segmentation. Additionally, UDI performs competitively in low-shot image classification, improving the scalability of joint-embedding pipelines. Various visualizations and ablation studies are presented to further elucidate the mechanisms behind UDI. Our source code is available at https://github.com/ISL-CV/udi.
VB-LoRA: Extreme Parameter Efficient Fine-Tuning with Vector Banks
May 27, 2024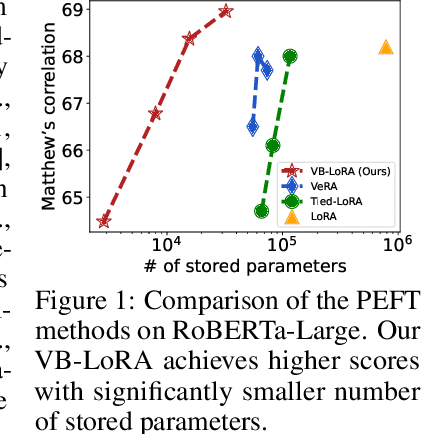
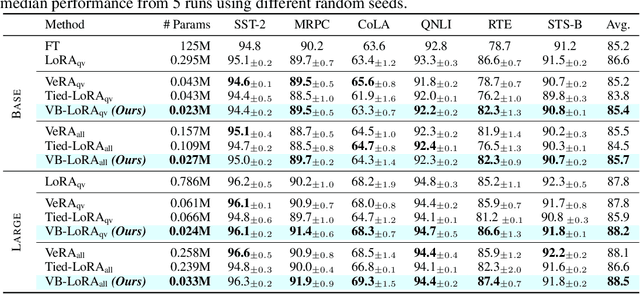
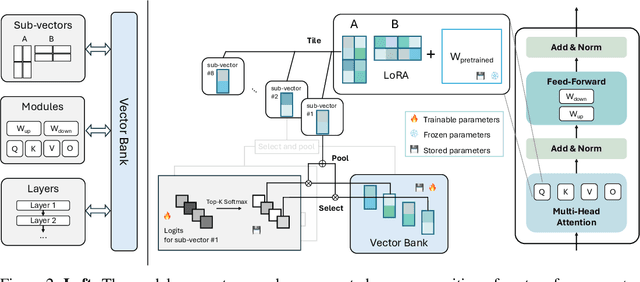
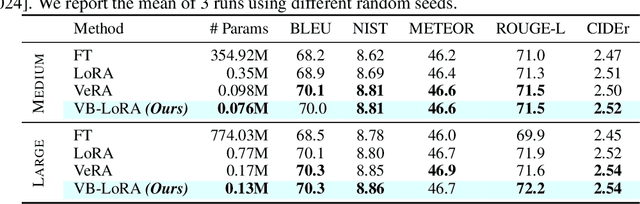
As the adoption of large language models increases and the need for per-user or per-task model customization grows, the parameter-efficient fine-tuning (PEFT) methods, such as low-rank adaptation (LoRA) and its variants, incur substantial storage and transmission costs. To further reduce stored parameters, we introduce a "divide-and-share" paradigm that breaks the barriers of low-rank decomposition across matrix dimensions, modules and layers by sharing parameters globally via a vector bank. As an instantiation of the paradigm to LoRA, our proposed VB-LoRA composites all the low-rank matrices of LoRA from a shared vector bank with a differentiable top-$k$ admixture module. VB-LoRA achieves extreme parameter efficiency while maintaining comparable or better performance compared to state-of-the-art PEFT methods. Extensive experiments demonstrate the effectiveness of VB-LoRA on natural language understanding, natural language generation, and instruction tuning tasks. When fine-tuning the Llama2-13B model, VB-LoRA only uses 0.4% of LoRA's stored parameters, yet achieves superior results. Our source code is available at https://github.com/leo-yangli/VB-LoRA.
A Hybrid Generative and Discriminative PointNet on Unordered Point Sets
Apr 19, 2024



As point cloud provides a natural and flexible representation usable in myriad applications (e.g., robotics and self-driving cars), the ability to synthesize point clouds for analysis becomes crucial. Recently, Xie et al. propose a generative model for unordered point sets in the form of an energy-based model (EBM). Despite the model achieving an impressive performance for point cloud generation, one separate model needs to be trained for each category to capture the complex point set distributions. Besides, their method is unable to classify point clouds directly and requires additional fine-tuning for classification. One interesting question is: Can we train a single network for a hybrid generative and discriminative model of point clouds? A similar question has recently been answered in the affirmative for images, introducing the framework of Joint Energy-based Model (JEM), which achieves high performance in image classification and generation simultaneously. This paper proposes GDPNet, the first hybrid Generative and Discriminative PointNet that extends JEM for point cloud classification and generation. Our GDPNet retains strong discriminative power of modern PointNet classifiers, while generating point cloud samples rivaling state-of-the-art generative approaches.
MatchXML: An Efficient Text-label Matching Framework for Extreme Multi-label Text Classification
Aug 25, 2023



The eXtreme Multi-label text Classification(XMC) refers to training a classifier that assigns a text sample with relevant labels from an extremely large-scale label set (e.g., millions of labels). We propose MatchXML, an efficient text-label matching framework for XMC. We observe that the label embeddings generated from the sparse Term Frequency-Inverse Document Frequency(TF-IDF) features have several limitations. We thus propose label2vec to effectively train the semantic dense label embeddings by the Skip-gram model. The dense label embeddings are then used to build a Hierarchical Label Tree by clustering. In fine-tuning the pre-trained encoder Transformer, we formulate the multi-label text classification as a text-label matching problem in a bipartite graph. We then extract the dense text representations from the fine-tuned Transformer. Besides the fine-tuned dense text embeddings, we also extract the static dense sentence embeddings from a pre-trained Sentence Transformer. Finally, a linear ranker is trained by utilizing the sparse TF-IDF features, the fine-tuned dense text representations and static dense sentence features. Experimental results demonstrate that MatchXML achieves state-of-the-art accuracy on five out of six datasets. As for the speed, MatchXML outperforms the competing methods on all the six datasets. Our source code is publicly available at https://github.com/huiyegit/MatchXML.
FLSL: Feature-level Self-supervised Learning
Jun 09, 2023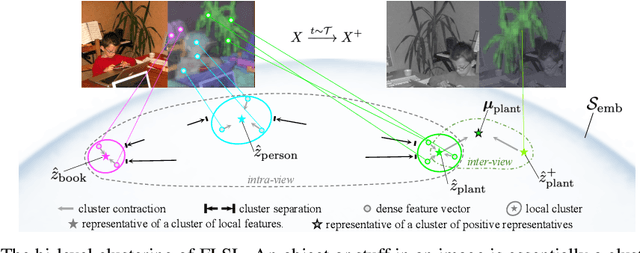
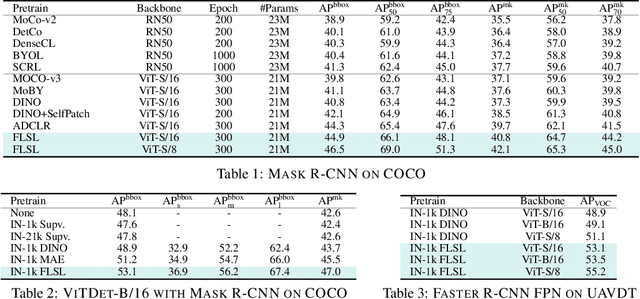
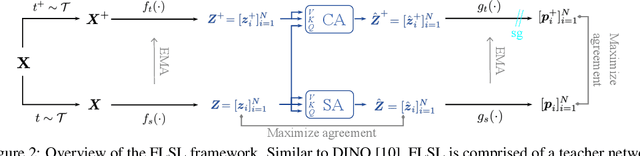
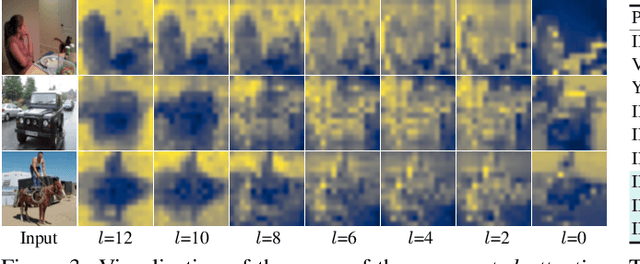
Current self-supervised learning (SSL) methods (e.g., SimCLR, DINO, VICReg, MOCOv3) target primarily on representations at instance level and do not generalize well to dense prediction tasks, such as object detection and segmentation. Towards aligning SSL with dense predictions, this paper demonstrates for the first time the underlying mean-shift clustering process of Vision Transformers (ViT), which aligns well with natural image semantics (e.g., a world of objects and stuffs). By employing transformer for joint embedding and clustering, we propose a two-level feature clustering SSL method, coined Feature-Level Self-supervised Learning (FLSL). We present the formal definition of the FLSL problem and construct the objectives from the mean-shift and k-means perspectives. We show that FLSL promotes remarkable semantic cluster representations and learns an embedding scheme amenable to intra-view and inter-view feature clustering. Experiments show that FLSL yields significant improvements in dense prediction tasks, achieving 44.9 (+2.8)% AP and 46.5% AP in object detection, as well as 40.8 (+2.3)% AP and 42.1% AP in instance segmentation on MS-COCO, using Mask R-CNN with ViT-S/16 and ViT-S/8 as backbone, respectively. FLSL consistently outperforms existing SSL methods across additional benchmarks, including UAV object detection on UAVDT, and video instance segmentation on DAVIS 2017. We conclude by presenting visualization and various ablation studies to better 20 understand the success of FLSL.