 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Video Segmentation
Jun 17, 2026While video segmentation has advanced rapidly on short clips and closed-set benchmarks, open-world video segmentation remains largely unexplored. The challenge is twofold: (1) existing methods are not designed to support object discovery and identity maintenance in long videos of dynamic ego-motion, and (2) existing evaluation protocols rely on a rigid 1:1 matching that unfairly penalizes semantically valid predictions with mismatched granularity. To address both gaps, we introduce Savvy, a practical and strong system for zero-shot open-world long-horizon video segmentation. Savvy combines hierarchical mask discovery, deferred admission, and track consolidation to support persistent object discovery, safe track promotion, and stable long-range identity maintenance. We further propose OGA, a granularity-aware evaluation suite for open-world video segmentation. Built on a Granularity-Agnostic (GA) matching protocol, OGA relaxes conventional 1:1 matching to an n:1 mapping, but still enforces temporal rigor by detecting support discontinuities through sever points and scoring each reference object through its dominant coherent fragment. This prevents fragmented or flickering support from being over-rewarded while enabling GA-adapted metrics and structural diagnostics: identity persistence (IP), and identity concentration (IC). On VIPSeg, we show that standard 1:1 evaluation substantially underestimates open-world methods, whereas GA evaluation recovers much of their suppressed performance. On the more realistic long-horizon benchmarks: ScanNet and HM3D, Savvy consistently outperforms strong baselines across both classical and proposed metrics, including STQ, VPQ$_\infty$, IP and IC. Together, these results establish a practical benchmark and a strong baseline for open-world long-horizon video segmentation.
Bayesian Model Merging
May 13, 2026Model merging aims to combine multiple task-specific expert models into a single model without joint retraining, offering a practical alternative to multi-task learning when data access or computational budget is limited. Existing methods, however, face two key limitations: (1) they overlook the valuable inductive bias of strong anchor models and estimate the merged weights from scratch, and (2) they rely on a shared hyperparameter setting across different modules of the network, lacking a global optimization strategy. This paper introduces Bayesian Model Merging (BMM), a plug-and-play bi-level optimization framework, where the inner level formulates the model merging as an activation-based Bayesian regression under a strong prior induced by an anchor model, yielding an efficient closed-form solution; and the outer level leverages a Bayesian optimization procedure to search module-specific hyperparameters globally based on a small validation set. Furthermore, we reveal a key alignment between activation statistics and task vectors, enabling us to derive a data-free variant of BMM that estimates the Gram matrix for regression without any auxiliary data. Across extensive benchmarks, including up to 20-task merging in vision and 5-task merging in language, BMM consistently outperforms all plug-and-play anchor baselines (e.g., TA, WUDI-Merging, and TSV). In particular, on the ViT-L/14 benchmark for 8-task merging, a single merged model reaches 95.1, closely matching the average performance of eight task-specific experts (95.8).
Low-Rank Adaptation for Critic Learning in Off-Policy Reinforcement Learning
Apr 21, 2026Scaling critic capacity is a promising direction for enhancing off-policy reinforcement learning (RL). However, larger critics are prone to overfitting and unstable in replay-buffer-based bootstrap training. This paper leverages Low-Rank Adaptation (LoRA) as a structural-sparsity regularizer for off-policy critics. Our approach freezes randomly initialized base matrices and solely optimizes low-rank adapters, thereby constraining critic updates to a low-dimensional subspace. Built on top of SimbaV2, we further develop a LoRA formulation, compatible with SimbaV2, that preserves its hyperspherical normalization geometry under frozen-backbone training. We evaluate our method with SAC and FastTD3 on DeepMind Control locomotion and IsaacLab robotics benchmarks. LoRA consistently achieves lower critic loss during training and stronger policy performance. Extensive experiments demonstrate that adaptive low-rank updates provide a simple, scalable, and effective structural regularization for critic learning in off-policy RL.
LiloDriver: A Lifelong Learning Framework for Closed-loop Motion Planning in Long-tail Autonomous Driving Scenarios
May 22, 2025Recent advances in autonomous driving research towards motion planners that are robust, safe, and adaptive. However, existing rule-based and data-driven planners lack adaptability to long-tail scenarios, while knowledge-driven methods offer strong reasoning but face challenges in representation, control, and real-world evaluation. To address these challenges, we present LiloDriver, a lifelong learning framework for closed-loop motion planning in long-tail autonomous driving scenarios. By integrating large language models (LLMs) with a memory-augmented planner generation system, LiloDriver continuously adapts to new scenarios without retraining. It features a four-stage architecture including perception, scene encoding, memory-based strategy refinement, and LLM-guided reasoning. Evaluated on the nuPlan benchmark, LiloDriver achieves superior performance in both common and rare driving scenarios, outperforming static rule-based and learning-based planners. Our results highlight the effectiveness of combining structured memory and LLM reasoning to enable scalable, human-like motion planning in real-world autonomous driving. Our code is available at https://github.com/Hyan-Yao/LiloDriver.
Unsqueeze [CLS] Bottleneck to Learn Rich Representations
Jul 26, 2024Distillation-based self-supervised learning typically leads to more compressed representations due to its radical clustering process and the implementation of a sharper target distribution. To overcome this limitation and preserve more information from input, we introduce UDI, conceptualized as Unsqueezed Distillation-based self-supervised learning (SSL). UDI enriches the learned representation by encouraging multimodal prediction distilled from a consolidated profile of local predictions that are derived via stratified sampling. Our evaluations show that UDI not only promotes semantically meaningful representations at instance level, delivering superior or competitive results to state-of-the-art SSL methods in image classification, but also effectively preserves the nuisance of input, which yields significant improvement in dense prediction tasks, including object detection and segmentation. Additionally, UDI performs competitively in low-shot image classification, improving the scalability of joint-embedding pipelines. Various visualizations and ablation studies are presented to further elucidate the mechanisms behind UDI. Our source code is available at https://github.com/ISL-CV/udi.
FLSL: Feature-level Self-supervised Learning
Jun 09, 2023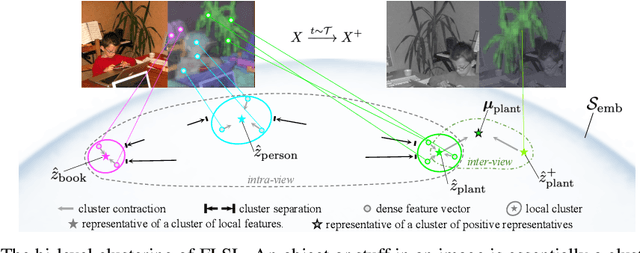
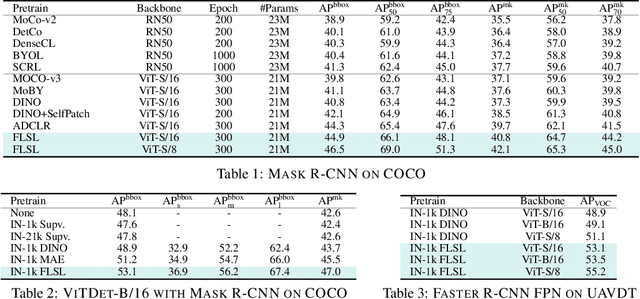
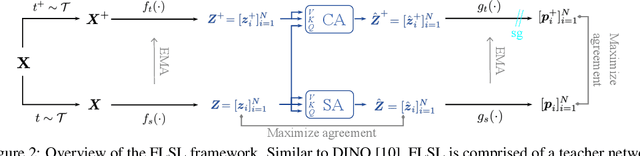
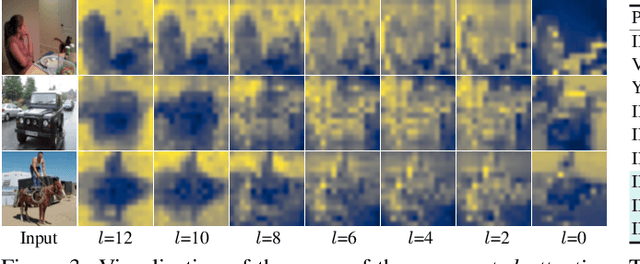
Current self-supervised learning (SSL) methods (e.g., SimCLR, DINO, VICReg, MOCOv3) target primarily on representations at instance level and do not generalize well to dense prediction tasks, such as object detection and segmentation. Towards aligning SSL with dense predictions, this paper demonstrates for the first time the underlying mean-shift clustering process of Vision Transformers (ViT), which aligns well with natural image semantics (e.g., a world of objects and stuffs). By employing transformer for joint embedding and clustering, we propose a two-level feature clustering SSL method, coined Feature-Level Self-supervised Learning (FLSL). We present the formal definition of the FLSL problem and construct the objectives from the mean-shift and k-means perspectives. We show that FLSL promotes remarkable semantic cluster representations and learns an embedding scheme amenable to intra-view and inter-view feature clustering. Experiments show that FLSL yields significant improvements in dense prediction tasks, achieving 44.9 (+2.8)% AP and 46.5% AP in object detection, as well as 40.8 (+2.3)% AP and 42.1% AP in instance segmentation on MS-COCO, using Mask R-CNN with ViT-S/16 and ViT-S/8 as backbone, respectively. FLSL consistently outperforms existing SSL methods across additional benchmarks, including UAV object detection on UAVDT, and video instance segmentation on DAVIS 2017. We conclude by presenting visualization and various ablation studies to better 20 understand the success of FLSL.
Towards Bridging the Performance Gaps of Joint Energy-based Models
Sep 16, 2022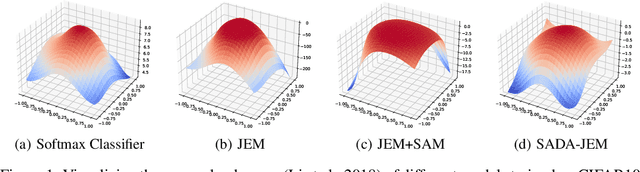

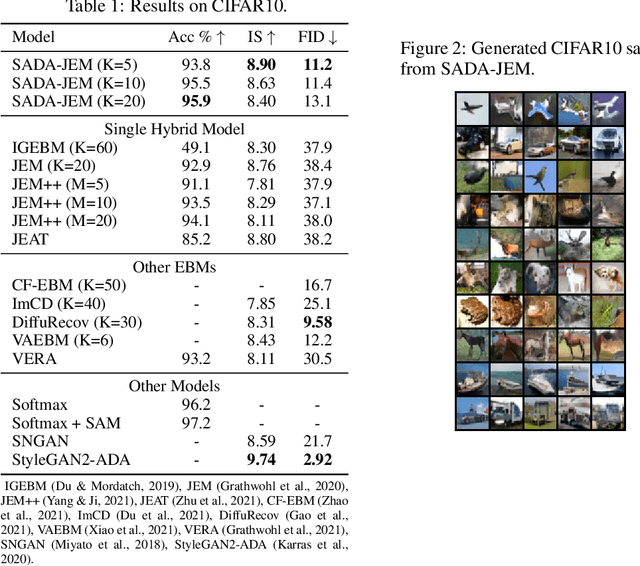
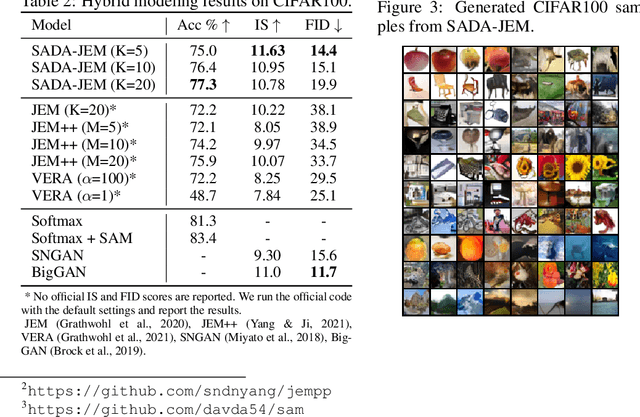
Can we train a hybrid discriminative-generative model within a single network? This question has recently been answered in the affirmative, introducing the field of Joint Energy-based Model (JEM), which achieves high classification accuracy and image generation quality simultaneously. Despite recent advances, there remain two performance gaps: the accuracy gap to the standard softmax classifier, and the generation quality gap to state-of-the-art generative models. In this paper, we introduce a variety of training techniques to bridge the accuracy gap and the generation quality gap of JEM. 1) We incorporate a recently proposed sharpness-aware minimization (SAM) framework to train JEM, which promotes the energy landscape smoothness and the generalizability of JEM. 2) We exclude data augmentation from the maximum likelihood estimate pipeline of JEM, and mitigate the negative impact of data augmentation to image generation quality. Extensive experiments on multiple datasets demonstrate that our SADA-JEM achieves state-of-the-art performances and outperforms JEM in image classification, image generation, calibration, out-of-distribution detection and adversarial robustness by a notable margin.
ChiTransformer:Towards Reliable Stereo from Cues
Mar 29, 2022
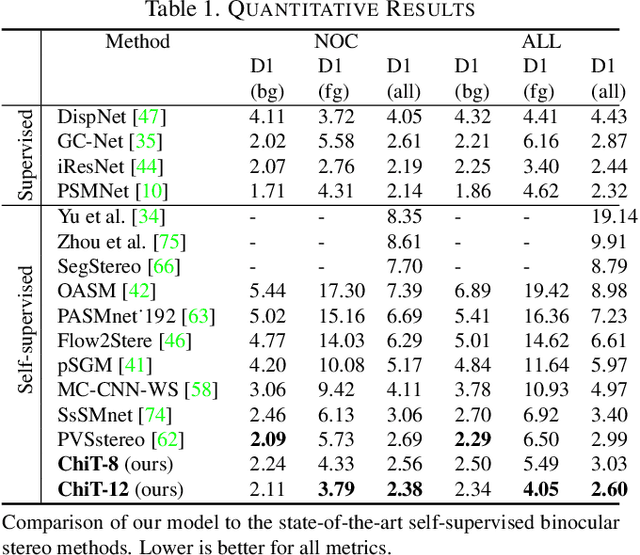
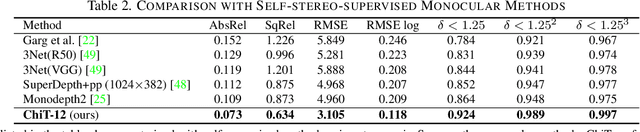

Current stereo matching techniques are challenged by restricted searching space, occluded regions and sheer size. While single image depth estimation is spared from these challenges and can achieve satisfactory results with the extracted monocular cues, the lack of stereoscopic relationship renders the monocular prediction less reliable on its own, especially in highly dynamic or cluttered environments. To address these issues in both scenarios, we present an optic-chiasm-inspired self-supervised binocular depth estimation method, wherein a vision transformer (ViT) with gated positional cross-attention (GPCA) layers is designed to enable feature-sensitive pattern retrieval between views while retaining the extensive context information aggregated through self-attentions. Monocular cues from a single view are thereafter conditionally rectified by a blending layer with the retrieved pattern pairs. This crossover design is biologically analogous to the optic-chasma structure in the human visual system and hence the name, ChiTransformer. Our experiments show that this architecture yields substantial improvements over state-of-the-art self-supervised stereo approaches by 11%, and can be used on both rectilinear and non-rectilinear (e.g., fisheye) images.
RoadMap: A Light-Weight Semantic Map for Visual Localization towards Autonomous Driving
Jun 04, 2021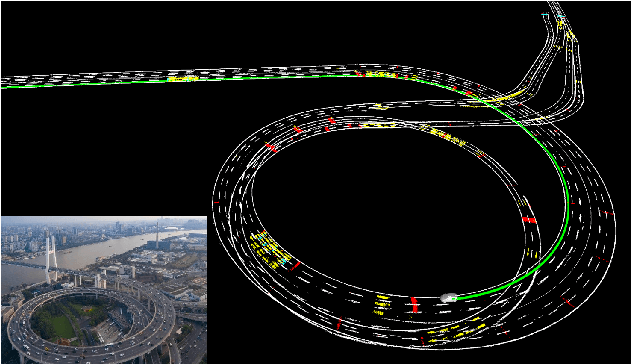
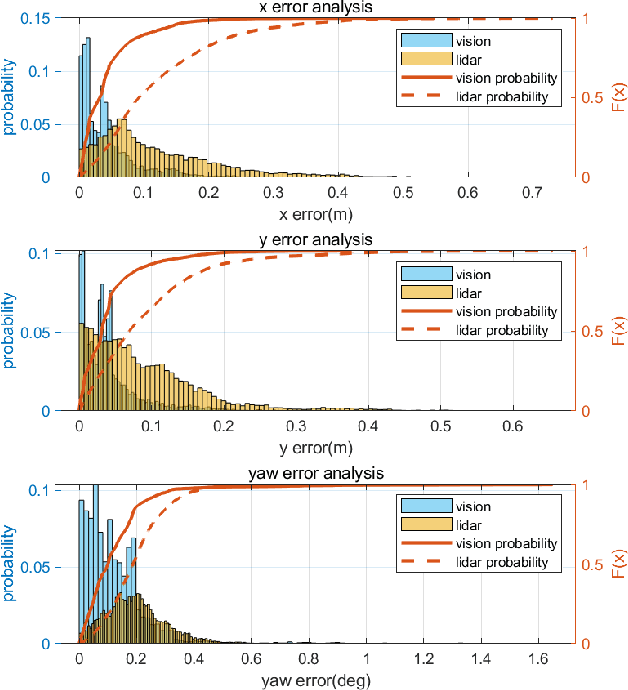
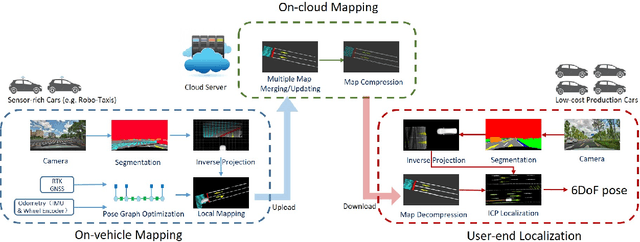
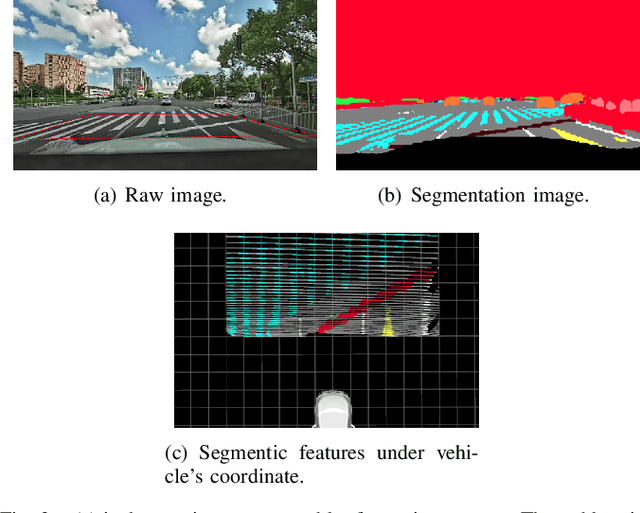
Accurate localization is of crucial importance for autonomous driving tasks. Nowadays, we have seen a lot of sensor-rich vehicles (e.g. Robo-taxi) driving on the street autonomously, which rely on high-accurate sensors (e.g. Lidar and RTK GPS) and high-resolution map. However, low-cost production cars cannot afford such high expenses on sensors and maps. How to reduce costs? How do sensor-rich vehicles benefit low-cost cars? In this paper, we proposed a light-weight localization solution, which relies on low-cost cameras and compact visual semantic maps. The map is easily produced and updated by sensor-rich vehicles in a crowd-sourced way. Specifically, the map consists of several semantic elements, such as lane line, crosswalk, ground sign, and stop line on the road surface. We introduce the whole framework of on-vehicle mapping, on-cloud maintenance, and user-end localization. The map data is collected and preprocessed on vehicles. Then, the crowd-sourced data is uploaded to a cloud server. The mass data from multiple vehicles are merged on the cloud so that the semantic map is updated in time. Finally, the semantic map is compressed and distributed to production cars, which use this map for localization. We validate the performance of the proposed map in real-world experiments and compare it against other algorithms. The average size of the semantic map is $36$ kb/km. We highlight that this framework is a reliable and practical localization solution for autonomous driving.
AVP-SLAM: Semantic Visual Mapping and Localization for Autonomous Vehicles in the Parking Lot
Jul 08, 2020
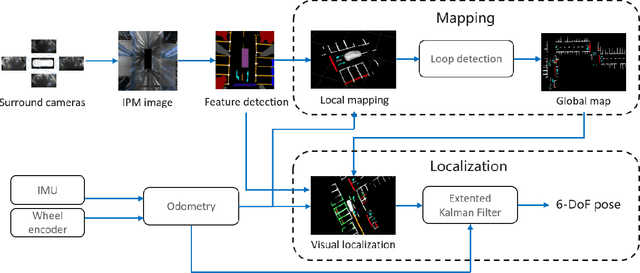


Autonomous valet parking is a specific application for autonomous vehicles. In this task, vehicles need to navigate in narrow, crowded and GPS-denied parking lots. Accurate localization ability is of great importance. Traditional visual-based methods suffer from tracking lost due to texture-less regions, repeated structures, and appearance changes. In this paper, we exploit robust semantic features to build the map and localize vehicles in parking lots. Semantic features contain guide signs, parking lines, speed bumps, etc, which typically appear in parking lots. Compared with traditional features, these semantic features are long-term stable and robust to the perspective and illumination change. We adopt four surround-view cameras to increase the perception range. Assisting by an IMU (Inertial Measurement Unit) and wheel encoders, the proposed system generates a global visual semantic map. This map is further used to localize vehicles at the centimeter level. We analyze the accuracy and recall of our system and compare it against other methods in real experiments. Furthermore, we demonstrate the practicability of the proposed system by the autonomous parking application.