 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRNES: Enabling Security and Privacy-aware Experience Sharing in Multiagent Robotic and Autonomous Systems
Aug 02, 2023



Although experience sharing (ES) accelerates multiagent reinforcement learning (MARL) in an advisor-advisee framework, attempts to apply ES to decentralized multiagent systems have so far relied on trusted environments and overlooked the possibility of adversarial manipulation and inference. Nevertheless, in a real-world setting, some Byzantine attackers, disguised as advisors, may provide false advice to the advisee and catastrophically degrade the overall learning performance. Also, an inference attacker, disguised as an advisee, may conduct several queries to infer the advisors' private information and make the entire ES process questionable in terms of privacy leakage. To address and tackle these issues, we propose a novel MARL framework (BRNES) that heuristically selects a dynamic neighbor zone for each advisee at each learning step and adopts a weighted experience aggregation technique to reduce Byzantine attack impact. Furthermore, to keep the agent's private information safe from adversarial inference attacks, we leverage the local differential privacy (LDP)-induced noise during the ES process. Our experiments show that our framework outperforms the state-of-the-art in terms of the steps to goal, obtained reward, and time to goal metrics. Particularly, our evaluation shows that the proposed framework is 8.32x faster than the current non-private frameworks and 1.41x faster than the private frameworks in an adversarial setting.
FLSL: Feature-level Self-supervised Learning
Jun 09, 2023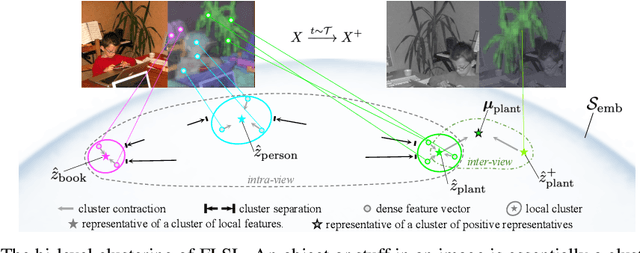
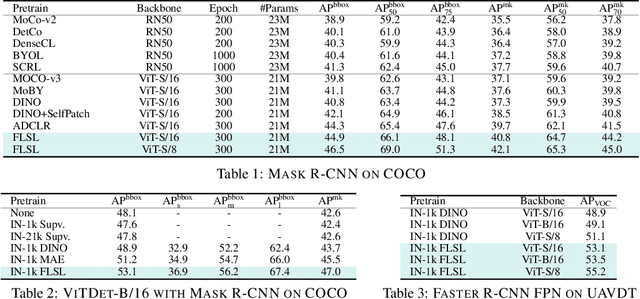
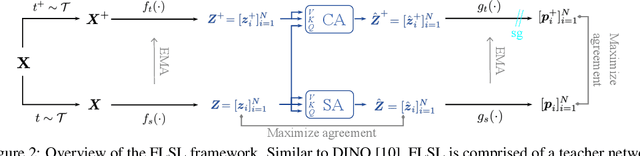
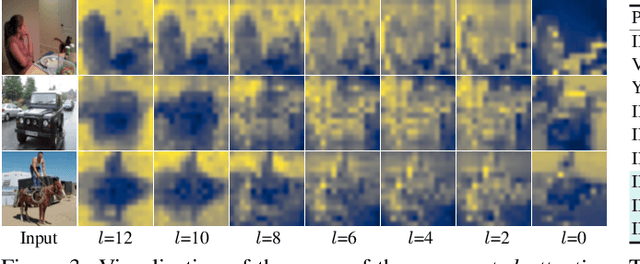
Current self-supervised learning (SSL) methods (e.g., SimCLR, DINO, VICReg, MOCOv3) target primarily on representations at instance level and do not generalize well to dense prediction tasks, such as object detection and segmentation. Towards aligning SSL with dense predictions, this paper demonstrates for the first time the underlying mean-shift clustering process of Vision Transformers (ViT), which aligns well with natural image semantics (e.g., a world of objects and stuffs). By employing transformer for joint embedding and clustering, we propose a two-level feature clustering SSL method, coined Feature-Level Self-supervised Learning (FLSL). We present the formal definition of the FLSL problem and construct the objectives from the mean-shift and k-means perspectives. We show that FLSL promotes remarkable semantic cluster representations and learns an embedding scheme amenable to intra-view and inter-view feature clustering. Experiments show that FLSL yields significant improvements in dense prediction tasks, achieving 44.9 (+2.8)% AP and 46.5% AP in object detection, as well as 40.8 (+2.3)% AP and 42.1% AP in instance segmentation on MS-COCO, using Mask R-CNN with ViT-S/16 and ViT-S/8 as backbone, respectively. FLSL consistently outperforms existing SSL methods across additional benchmarks, including UAV object detection on UAVDT, and video instance segmentation on DAVIS 2017. We conclude by presenting visualization and various ablation studies to better 20 understand the success of FLSL.