 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamVLA: Breaking the Reason-Act Cycle via Completion-State Gating
Feb 01, 2026Long-horizon robotic manipulation requires bridging the gap between high-level planning (System 2) and low-level control (System 1). Current Vision-Language-Action (VLA) models often entangle these processes, performing redundant multimodal reasoning at every timestep, which leads to high latency and goal instability. To address this, we present StreamVLA, a dual-system architecture that unifies textual task decomposition, visual goal imagination, and continuous action generation within a single parameter-efficient backbone. We introduce a "Lock-and-Gated" mechanism to intelligently modulate computation: only when a sub-task transition is detected, the model triggers slow thinking to generate a textual instruction and imagines the specific visual completion state, rather than generic future frames. Crucially, this completion state serves as a time-invariant goal anchor, making the policy robust to execution speed variations. During steady execution, these high-level intents are locked to condition a Flow Matching action head, allowing the model to bypass expensive autoregressive decoding for 72% of timesteps. This hierarchical abstraction ensures sub-goal focus while significantly reducing inference latency. Extensive evaluations demonstrate that StreamVLA achieves state-of-the-art performance, with a 98.5% success rate on the LIBERO benchmark and robust recovery in real-world interference scenarios, achieving a 48% reduction in latency compared to full-reasoning baselines.
RoadMap: A Light-Weight Semantic Map for Visual Localization towards Autonomous Driving
Jun 04, 2021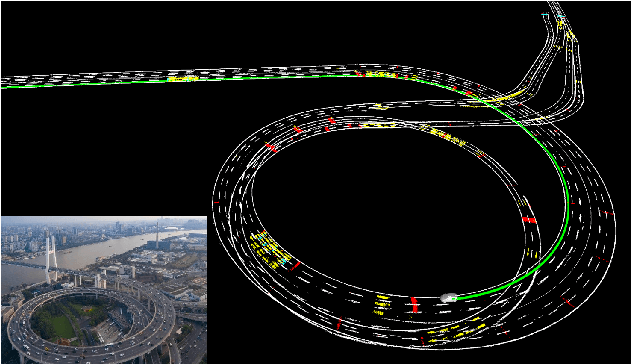
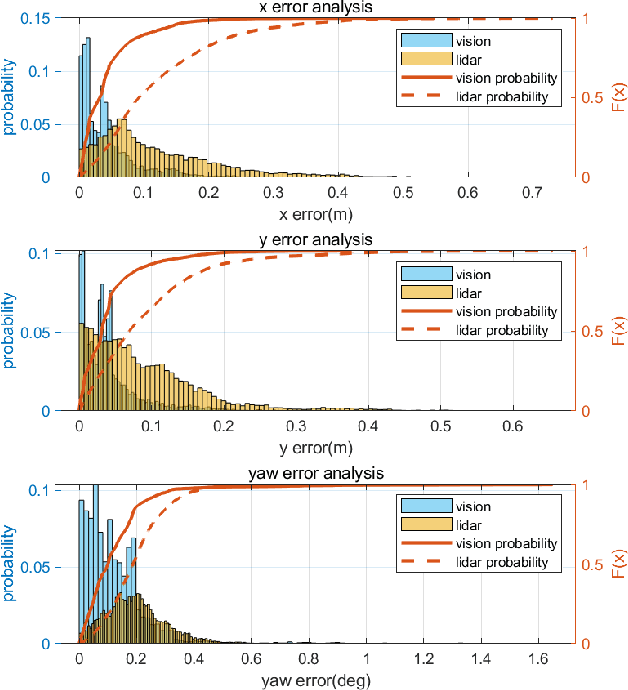
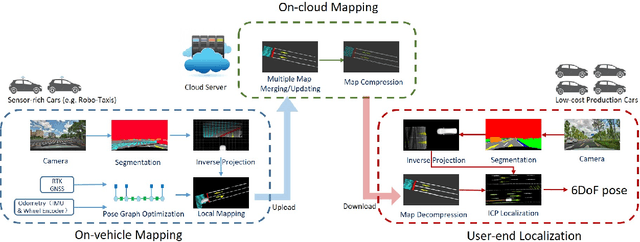
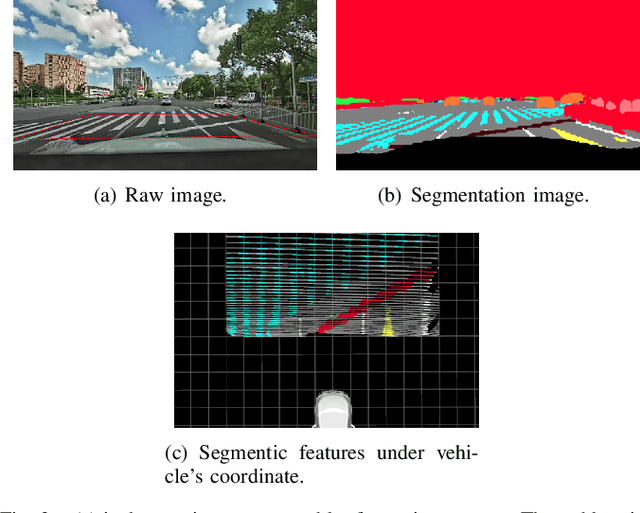
Accurate localization is of crucial importance for autonomous driving tasks. Nowadays, we have seen a lot of sensor-rich vehicles (e.g. Robo-taxi) driving on the street autonomously, which rely on high-accurate sensors (e.g. Lidar and RTK GPS) and high-resolution map. However, low-cost production cars cannot afford such high expenses on sensors and maps. How to reduce costs? How do sensor-rich vehicles benefit low-cost cars? In this paper, we proposed a light-weight localization solution, which relies on low-cost cameras and compact visual semantic maps. The map is easily produced and updated by sensor-rich vehicles in a crowd-sourced way. Specifically, the map consists of several semantic elements, such as lane line, crosswalk, ground sign, and stop line on the road surface. We introduce the whole framework of on-vehicle mapping, on-cloud maintenance, and user-end localization. The map data is collected and preprocessed on vehicles. Then, the crowd-sourced data is uploaded to a cloud server. The mass data from multiple vehicles are merged on the cloud so that the semantic map is updated in time. Finally, the semantic map is compressed and distributed to production cars, which use this map for localization. We validate the performance of the proposed map in real-world experiments and compare it against other algorithms. The average size of the semantic map is $36$ kb/km. We highlight that this framework is a reliable and practical localization solution for autonomous driving.
AVP-SLAM: Semantic Visual Mapping and Localization for Autonomous Vehicles in the Parking Lot
Jul 08, 2020
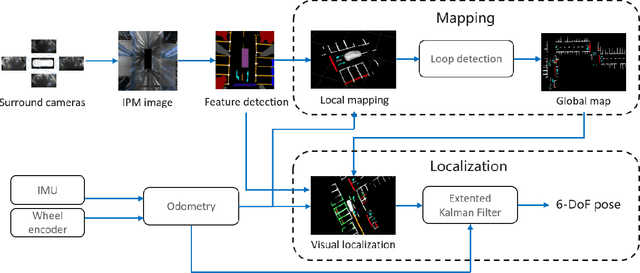


Autonomous valet parking is a specific application for autonomous vehicles. In this task, vehicles need to navigate in narrow, crowded and GPS-denied parking lots. Accurate localization ability is of great importance. Traditional visual-based methods suffer from tracking lost due to texture-less regions, repeated structures, and appearance changes. In this paper, we exploit robust semantic features to build the map and localize vehicles in parking lots. Semantic features contain guide signs, parking lines, speed bumps, etc, which typically appear in parking lots. Compared with traditional features, these semantic features are long-term stable and robust to the perspective and illumination change. We adopt four surround-view cameras to increase the perception range. Assisting by an IMU (Inertial Measurement Unit) and wheel encoders, the proposed system generates a global visual semantic map. This map is further used to localize vehicles at the centimeter level. We analyze the accuracy and recall of our system and compare it against other methods in real experiments. Furthermore, we demonstrate the practicability of the proposed system by the autonomous parking application.