 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Guided k-Guard Sampling for Long-Horizon Autoregressive Video Generation
Jan 27, 2026Autoregressive (AR) architectures have achieved significant successes in LLMs, inspiring explorations for video generation. In LLMs, top-p/top-k sampling strategies work exceptionally well: language tokens have high semantic density and low redundancy, so a fixed size of token candidates already strikes a balance between semantic accuracy and generation diversity. In contrast, video tokens have low semantic density and high spatio-temporal redundancy. This mismatch makes static top-k/top-p strategies ineffective for video decoders: they either introduce unnecessary randomness for low-uncertainty regions (static backgrounds) or get stuck in early errors for high-uncertainty regions (foreground objects). Prediction errors will accumulate as more frames are generated and eventually severely degrade long-horizon quality. To address this, we propose Entropy-Guided k-Guard (ENkG) sampling, a simple yet effective strategy that adapts sampling to token-wise dispersion, quantified by the entropy of each token's predicted distribution. ENkG uses adaptive token candidate sizes: for low-entropy regions, it employs fewer candidates to suppress redundant noise and preserve structural integrity; for high-entropy regions, it uses more candidates to mitigate error compounding. ENkG is model-agnostic, training-free, and adds negligible overhead. Experiments demonstrate consistent improvements in perceptual quality and structural stability compared to static top-k/top-p strategies.
CogToM: A Comprehensive Theory of Mind Benchmark inspired by Human Cognition for Large Language Models
Jan 22, 2026Whether Large Language Models (LLMs) truly possess human-like Theory of Mind (ToM) capabilities has garnered increasing attention. However, existing benchmarks remain largely restricted to narrow paradigms like false belief tasks, failing to capture the full spectrum of human cognitive mechanisms. We introduce CogToM, a comprehensive, theoretically grounded benchmark comprising over 8000 bilingual instances across 46 paradigms, validated by 49 human annotator.A systematic evaluation of 22 representative models, including frontier models like GPT-5.1 and Qwen3-Max, reveals significant performance heterogeneities and highlights persistent bottlenecks in specific dimensions. Further analysis based on human cognitive patterns suggests potential divergences between LLM and human cognitive structures. CogToM offers a robust instrument and perspective for investigating the evolving cognitive boundaries of LLMs.
ClearAIR: A Human-Visual-Perception-Inspired All-in-One Image Restoration
Jan 06, 2026All-in-One Image Restoration (AiOIR) has advanced significantly, offering promising solutions for complex real-world degradations. However, most existing approaches rely heavily on degradation-specific representations, often resulting in oversmoothing and artifacts. To address this, we propose ClearAIR, a novel AiOIR framework inspired by Human Visual Perception (HVP) and designed with a hierarchical, coarse-to-fine restoration strategy. First, leveraging the global priority of early HVP, we employ a Multimodal Large Language Model (MLLM)-based Image Quality Assessment (IQA) model for overall evaluation. Unlike conventional IQA, our method integrates cross-modal understanding to more accurately characterize complex, composite degradations. Building upon this overall assessment, we then introduce a region awareness and task recognition pipeline. A semantic cross-attention, leveraging semantic guidance unit, first produces coarse semantic prompts. Guided by this regional context, a degradation-aware module implicitly captures region-specific degradation characteristics, enabling more precise local restoration. Finally, to recover fine details, we propose an internal clue reuse mechanism. It operates in a self-supervised manner to mine and leverage the intrinsic information of the image itself, substantially enhancing detail restoration. Experimental results show that ClearAIR achieves superior performance across diverse synthetic and real-world datasets.
Towards Reliable Evaluation of Adversarial Robustness for Spiking Neural Networks
Dec 27, 2025Spiking Neural Networks (SNNs) utilize spike-based activations to mimic the brain's energy-efficient information processing. However, the binary and discontinuous nature of spike activations causes vanishing gradients, making adversarial robustness evaluation via gradient descent unreliable. While improved surrogate gradient methods have been proposed, their effectiveness under strong adversarial attacks remains unclear. We propose a more reliable framework for evaluating SNN adversarial robustness. We theoretically analyze the degree of gradient vanishing in surrogate gradients and introduce the Adaptive Sharpness Surrogate Gradient (ASSG), which adaptively evolves the shape of the surrogate function according to the input distribution during attack iterations, thereby enhancing gradient accuracy while mitigating gradient vanishing. In addition, we design an adversarial attack with adaptive step size under the $L_\infty$ constraint-Stable Adaptive Projected Gradient Descent (SA-PGD), achieving faster and more stable convergence under imprecise gradients. Extensive experiments show that our approach substantially increases attack success rates across diverse adversarial training schemes, SNN architectures and neuron models, providing a more generalized and reliable evaluation of SNN adversarial robustness. The experimental results further reveal that the robustness of current SNNs has been significantly overestimated and highlighting the need for more dependable adversarial training methods.
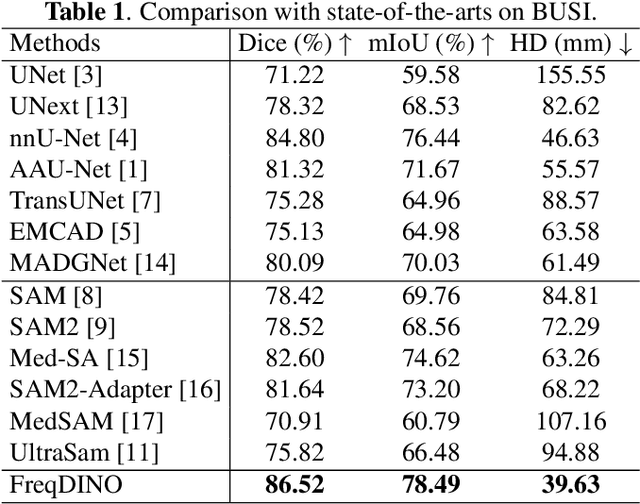
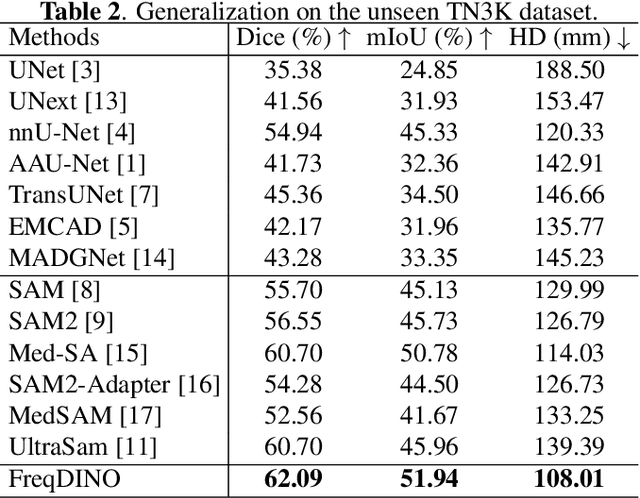
FreqDINO: Frequency-Guided Adaptation for Generalized Boundary-Aware Ultrasound Image Segmentation
Dec 12, 2025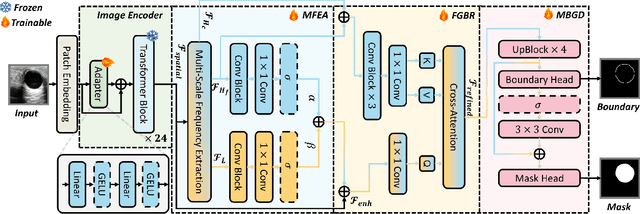
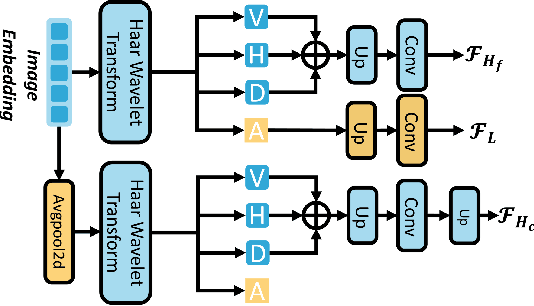
Ultrasound image segmentation is pivotal for clinical diagnosis, yet challenged by speckle noise and imaging artifacts. Recently, DINOv3 has shown remarkable promise in medical image segmentation with its powerful representation capabilities. However, DINOv3, pre-trained on natural images, lacks sensitivity to ultrasound-specific boundary degradation. To address this limitation, we propose FreqDINO, a frequency-guided segmentation framework that enhances boundary perception and structural consistency. Specifically, we devise a Multi-scale Frequency Extraction and Alignment (MFEA) strategy to separate low-frequency structures and multi-scale high-frequency boundary details, and align them via learnable attention. We also introduce a Frequency-Guided Boundary Refinement (FGBR) module that extracts boundary prototypes from high-frequency components and refines spatial features. Furthermore, we design a Multi-task Boundary-Guided Decoder (MBGD) to ensure spatial coherence between boundary and semantic predictions. Extensive experiments demonstrate that FreqDINO surpasses state-of-the-art methods with superior achieves remarkable generalization capability. The code is at https://github.com/MingLang-FD/FreqDINO.
Generative AI for Analysts
Dec 12, 2025We study how generative artificial intelligence (AI) transforms the work of financial analysts. Using the 2023 launch of FactSet's AI platform as a natural experiment, we find that adoption produces markedly richer and more comprehensive reports -- featuring 40% more distinct information sources, 34% broader topical coverage, and 25% greater use of advanced analytical methods -- while also improving timeliness. However, forecast errors rise by 59% as AI-assisted reports convey a more balanced mix of positive and negative information that is harder to synthesize, particularly for analysts facing heavier cognitive demands. Placebo tests using other data vendors confirm that these effects are unique to FactSet's AI integration. Overall, our findings reveal both the productivity gains and cognitive limits of generative AI in financial information production.
Enhanced Information Security via Wave-Field Selectivity and Structured Wavefront Manipulation
Dec 11, 2025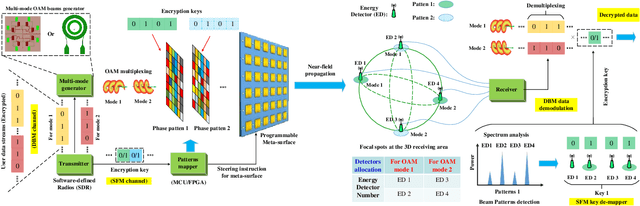
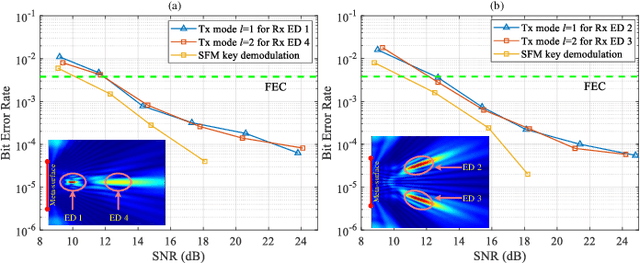
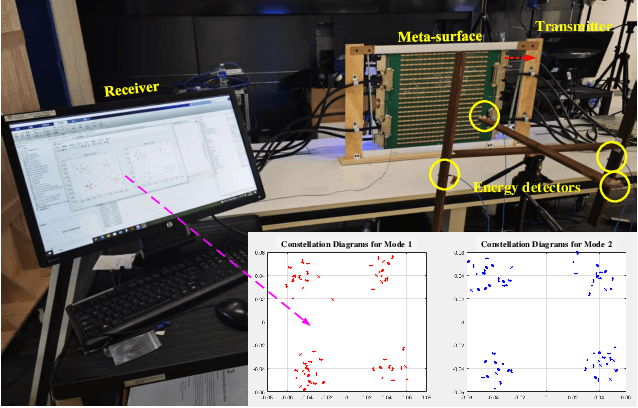
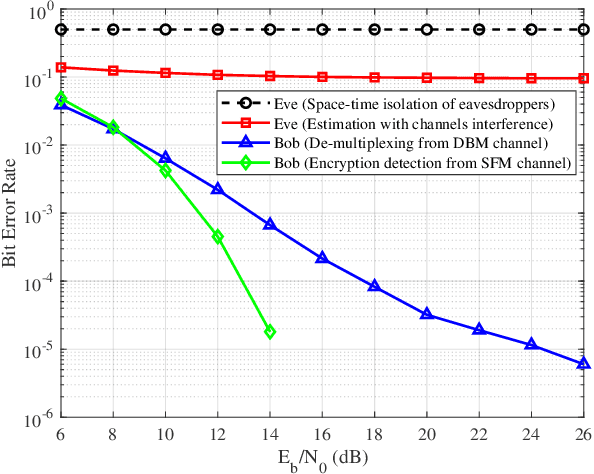
In this paper, we propose a novel secure wireless transmission architecture that enables the co-existence of spatial field modulation (SFM) and digital bandpass modulation (DBM), utilizing multi-mode vortex waves and programmable meta-surfaces (PMS). Distinct from conventional joint modulation schemes, our approach establishes two logically independent transmission channels--SFM and DBM--thereby eliminating the need for joint signal design or time synchronization. Specifically, the orthogonality of vortex wave modes is exploited to construct a high-capacity multi-mode DBM channel, in which each mode carries modulated symbols independently. As the composite waveform passes through the PMS, energy from different vortex modes is spatially focused onto distinct positions, dynamically determined by the PMS configuration. This spatial mapping forms a unique lookup table that encodes additional information in the electro-magnetic (EM) field distribution, effectively enabling a second, concurrent SFM channel. To enhance physical-layer security, the DBM channel transmits encrypted symbols transformed via dynamic symbol-domain mapping, while the corresponding mapping relations--or key information--are carried by the SFM channel. This lightweight dual-channel encryption strategy provides strong confidentiality without requiring complex joint decoding. To validate the feasibility of the proposed architecture, we design and implement a proof-of-concept prototype system, and conduct experimental demonstrations under real-world wireless communication conditions. The experimental results confirm the effectiveness of the co-existent DBM-SFM design in achieving reliable and secure transmission. The proposed architecture offers a scalable, low-complexity, and secure transmission solution for future IoT networks, especially in scenarios demanding both spectral efficiency and physical-layer confidentiality.
InfiniteVL: Synergizing Linear and Sparse Attention for Highly-Efficient, Unlimited-Input Vision-Language Models
Dec 09, 2025Window attention and linear attention represent two principal strategies for mitigating the quadratic complexity and ever-growing KV cache in Vision-Language Models (VLMs). However, we observe that window-based VLMs suffer performance degradation when sequence length exceeds the window size, while linear attention underperforms on information-intensive tasks such as OCR and document understanding. To overcome these limitations, we propose InfiniteVL, a linear-complexity VLM architecture that synergizes sliding window attention (SWA) with Gated DeltaNet. For achieving competitive multimodal performance under constrained resources, we design a three-stage training strategy comprising distillation pretraining, instruction tuning, and long-sequence SFT. Remarkably, using less than 2\% of the training data required by leading VLMs, InfiniteVL not only substantially outperforms previous linear-complexity VLMs but also matches the performance of leading Transformer-based VLMs, while demonstrating effective long-term memory retention. Compared to similar-sized Transformer-based VLMs accelerated by FlashAttention-2, InfiniteVL achieves over 3.6\times inference speedup while maintaining constant latency and memory footprint. In streaming video understanding scenarios, it sustains a stable 24 FPS real-time prefill speed while preserving long-term memory cache. Code and models are available at https://github.com/hustvl/InfiniteVL.
DiffusionDriveV2: Reinforcement Learning-Constrained Truncated Diffusion Modeling in End-to-End Autonomous Driving
Dec 08, 2025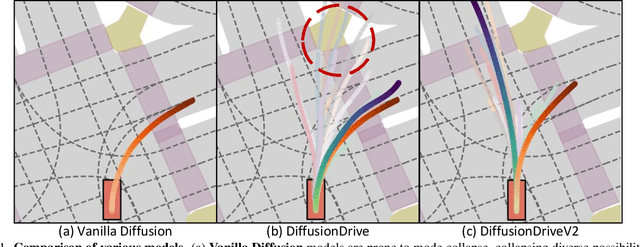
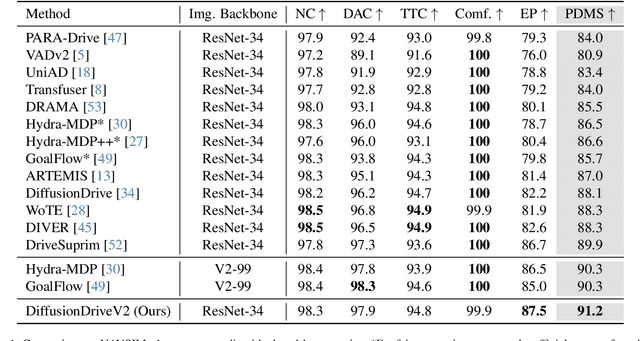
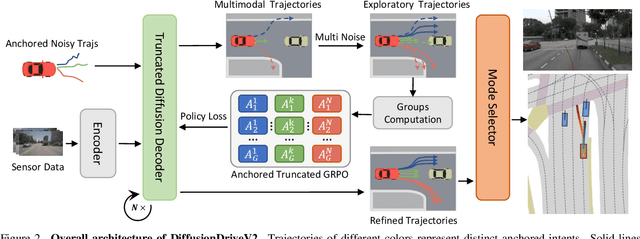
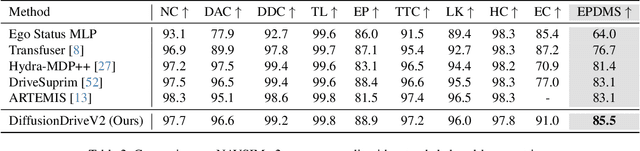
Generative diffusion models for end-to-end autonomous driving often suffer from mode collapse, tending to generate conservative and homogeneous behaviors. While DiffusionDrive employs predefined anchors representing different driving intentions to partition the action space and generate diverse trajectories, its reliance on imitation learning lacks sufficient constraints, resulting in a dilemma between diversity and consistent high quality. In this work, we propose DiffusionDriveV2, which leverages reinforcement learning to both constrain low-quality modes and explore for superior trajectories. This significantly enhances the overall output quality while preserving the inherent multimodality of its core Gaussian Mixture Model. First, we use scale-adaptive multiplicative noise, ideal for trajectory planning, to promote broad exploration. Second, we employ intra-anchor GRPO to manage advantage estimation among samples generated from a single anchor, and inter-anchor truncated GRPO to incorporate a global perspective across different anchors, preventing improper advantage comparisons between distinct intentions (e.g., turning vs. going straight), which can lead to further mode collapse. DiffusionDriveV2 achieves 91.2 PDMS on the NAVSIM v1 dataset and 85.5 EPDMS on the NAVSIM v2 dataset in closed-loop evaluation with an aligned ResNet-34 backbone, setting a new record. Further experiments validate that our approach resolves the dilemma between diversity and consistent high quality for truncated diffusion models, achieving the best trade-off. Code and model will be available at https://github.com/hustvl/DiffusionDriveV2
Sample Complexity of Agnostic Multiclass Classification: Natarajan Dimension Strikes Back
Nov 16, 2025The fundamental theorem of statistical learning states that binary PAC learning is governed by a single parameter -- the Vapnik-Chervonenkis (VC) dimension -- which determines both learnability and sample complexity. Extending this to multiclass classification has long been challenging, since Natarajan's work in the late 80s proposing the Natarajan dimension (Nat) as a natural analogue of VC. Daniely and Shalev-Shwartz (2014) introduced the DS dimension, later shown by Brukhim et al. (2022) to characterize multiclass learnability. Brukhim et al. also showed that Nat and DS can diverge arbitrarily, suggesting that multiclass learning is governed by DS rather than Nat. We show that agnostic multiclass PAC sample complexity is in fact governed by two distinct dimensions. Specifically, we prove nearly tight agnostic sample complexity bounds that, up to log factors, take the form $\frac{DS^{1.5}}ε + \frac{Nat}{ε^2}$ where $ε$ is the excess risk. This bound is tight up to a $\sqrt{DS}$ factor in the first term, nearly matching known $Nat/ε^2$ and $DS/ε$ lower bounds. The first term reflects the DS-controlled regime, while the second shows that the Natarajan dimension still dictates asymptotic behavior for small $ε$. Thus, unlike binary or online classification -- where a single dimension (VC or Littlestone) controls both phenomena -- multiclass learning inherently involves two structural parameters. Our technical approach departs from traditional agnostic learning methods based on uniform convergence or reductions to realizable cases. A key ingredient is a novel online procedure based on a self-adaptive multiplicative-weights algorithm performing a label-space reduction, which may be of independent interest.