 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
Senna-2: Aligning VLM and End-to-End Driving Policy for Consistent Decision Making and Planning
Mar 11, 2026Vision-language models (VLMs) enhance the planning capability of end-to-end (E2E) driving policy by leveraging high-level semantic reasoning. However, existing approaches often overlook the dual-system consistency between VLM's high-level decision and E2E's low-level planning. As a result, the generated trajectories may misalign with the intended driving decisions, leading to weakened top-down guidance and decision-following ability of the system. To address this issue, we propose Senna-2, an advanced VLM-E2E driving policy that explicitly aligns the two systems for consistent decision-making and planning. Our method follows a consistency-oriented three-stage training paradigm. In the first stage, we conduct driving pre-training to achieve preliminary decision-making and planning, with a decision adapter transmitting VLM decisions to E2E policy in the form of implicit embeddings. In the second stage, we align the VLM and the E2E policy in an open-loop setting. In the third stage, we perform closed-loop alignment via bottom-up Hierarchical Reinforcement Learning in 3DGS environments to reinforce the safety and efficiency. Extensive experiments demonstrate that Senna-2 achieves superior dual-system consistency (19.3% F1 score improvement) and significantly enhances driving safety in both open-loop (5.7% FDE reduction) and closed-loop settings (30.6% AF-CR reduction).
DiffusionDriveV2: Reinforcement Learning-Constrained Truncated Diffusion Modeling in End-to-End Autonomous Driving
Dec 08, 2025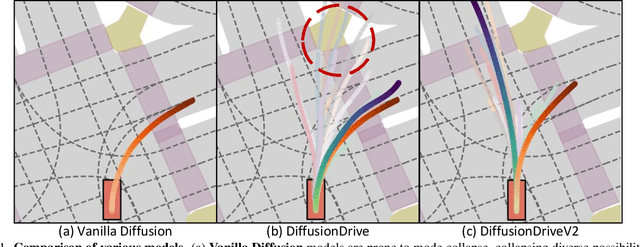
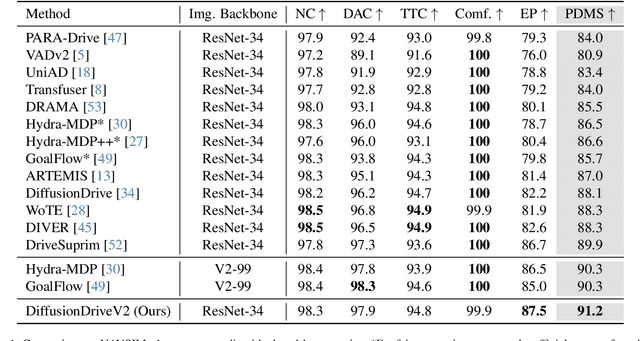
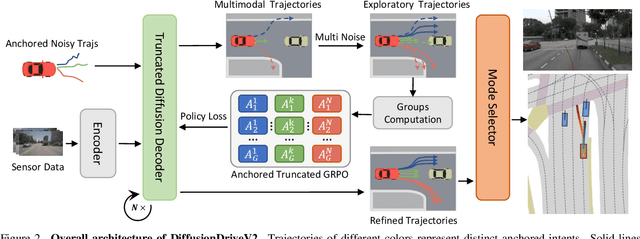
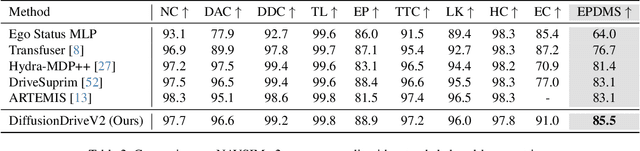
Generative diffusion models for end-to-end autonomous driving often suffer from mode collapse, tending to generate conservative and homogeneous behaviors. While DiffusionDrive employs predefined anchors representing different driving intentions to partition the action space and generate diverse trajectories, its reliance on imitation learning lacks sufficient constraints, resulting in a dilemma between diversity and consistent high quality. In this work, we propose DiffusionDriveV2, which leverages reinforcement learning to both constrain low-quality modes and explore for superior trajectories. This significantly enhances the overall output quality while preserving the inherent multimodality of its core Gaussian Mixture Model. First, we use scale-adaptive multiplicative noise, ideal for trajectory planning, to promote broad exploration. Second, we employ intra-anchor GRPO to manage advantage estimation among samples generated from a single anchor, and inter-anchor truncated GRPO to incorporate a global perspective across different anchors, preventing improper advantage comparisons between distinct intentions (e.g., turning vs. going straight), which can lead to further mode collapse. DiffusionDriveV2 achieves 91.2 PDMS on the NAVSIM v1 dataset and 85.5 EPDMS on the NAVSIM v2 dataset in closed-loop evaluation with an aligned ResNet-34 backbone, setting a new record. Further experiments validate that our approach resolves the dilemma between diversity and consistent high quality for truncated diffusion models, achieving the best trade-off. Code and model will be available at https://github.com/hustvl/DiffusionDriveV2
OmniMamba: Efficient and Unified Multimodal Understanding and Generation via State Space Models
Mar 11, 2025Recent advancements in unified multimodal understanding and visual generation (or multimodal generation) models have been hindered by their quadratic computational complexity and dependence on large-scale training data. We present OmniMamba, the first linear-architecture-based multimodal generation model that generates both text and images through a unified next-token prediction paradigm. The model fully leverages Mamba-2's high computational and memory efficiency, extending its capabilities from text generation to multimodal generation. To address the data inefficiency of existing unified models, we propose two key innovations: (1) decoupled vocabularies to guide modality-specific generation, and (2) task-specific LoRA for parameter-efficient adaptation. Furthermore, we introduce a decoupled two-stage training strategy to mitigate data imbalance between two tasks. Equipped with these techniques, OmniMamba achieves competitive performance with JanusFlow while surpassing Show-o across benchmarks, despite being trained on merely 2M image-text pairs, which is 1,000 times fewer than Show-o. Notably, OmniMamba stands out with outstanding inference efficiency, achieving up to a 119.2 times speedup and 63% GPU memory reduction for long-sequence generation compared to Transformer-based counterparts. Code and models are released at https://github.com/hustvl/OmniMamba
MIM4D: Masked Modeling with Multi-View Video for Autonomous Driving Representation Learning
Mar 13, 2024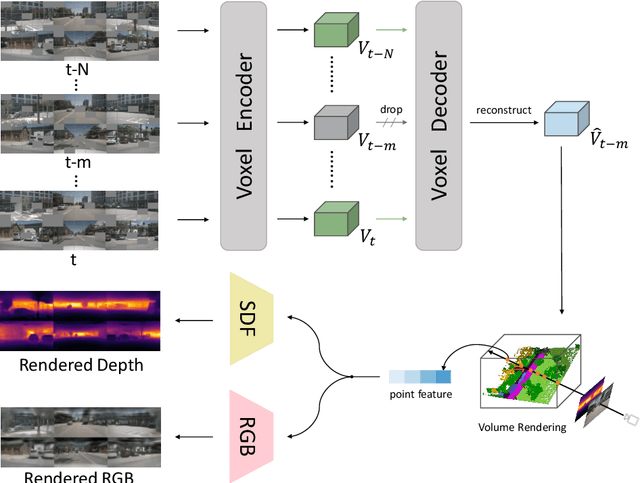



Learning robust and scalable visual representations from massive multi-view video data remains a challenge in computer vision and autonomous driving. Existing pre-training methods either rely on expensive supervised learning with 3D annotations, limiting the scalability, or focus on single-frame or monocular inputs, neglecting the temporal information. We propose MIM4D, a novel pre-training paradigm based on dual masked image modeling (MIM). MIM4D leverages both spatial and temporal relations by training on masked multi-view video inputs. It constructs pseudo-3D features using continuous scene flow and projects them onto 2D plane for supervision. To address the lack of dense 3D supervision, MIM4D reconstruct pixels by employing 3D volumetric differentiable rendering to learn geometric representations. We demonstrate that MIM4D achieves state-of-the-art performance on the nuScenes dataset for visual representation learning in autonomous driving. It significantly improves existing methods on multiple downstream tasks, including BEV segmentation (8.7% IoU), 3D object detection (3.5% mAP), and HD map construction (1.4% mAP). Our work offers a new choice for learning representation at scale in autonomous driving. Code and models are released at https://github.com/hustvl/MIM4D
Circuit as Set of Points
Oct 26, 2023



As the size of circuit designs continues to grow rapidly, artificial intelligence technologies are being extensively used in Electronic Design Automation (EDA) to assist with circuit design. Placement and routing are the most time-consuming parts of the physical design process, and how to quickly evaluate the placement has become a hot research topic. Prior works either transformed circuit designs into images using hand-crafted methods and then used Convolutional Neural Networks (CNN) to extract features, which are limited by the quality of the hand-crafted methods and could not achieve end-to-end training, or treated the circuit design as a graph structure and used Graph Neural Networks (GNN) to extract features, which require time-consuming preprocessing. In our work, we propose a novel perspective for circuit design by treating circuit components as point clouds and using Transformer-based point cloud perception methods to extract features from the circuit. This approach enables direct feature extraction from raw data without any preprocessing, allows for end-to-end training, and results in high performance. Experimental results show that our method achieves state-of-the-art performance in congestion prediction tasks on both the CircuitNet and ISPD2015 datasets, as well as in design rule check (DRC) violation prediction tasks on the CircuitNet dataset. Our method establishes a bridge between the relatively mature point cloud perception methods and the fast-developing EDA algorithms, enabling us to leverage more collective intelligence to solve this task. To facilitate the research of open EDA design, source codes and pre-trained models are released at https://github.com/hustvl/circuitformer.