 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDriveVLA: Unifying Understanding, Perception, and Action Planning for Autonomous Driving
Apr 02, 2026Vision-Language-Action (VLA) models have recently emerged in autonomous driving, with the promise of leveraging rich world knowledge to improve the cognitive capabilities of driving systems. However, adapting such models for driving tasks currently faces a critical dilemma between spatial perception and semantic reasoning. Consequently, existing VLA systems are forced into suboptimal compromises: directly adopting 2D Vision-Language Models yields limited spatial perception, whereas enhancing them with 3D spatial representations often impairs the native reasoning capacity of VLMs. We argue that this dilemma largely stems from the coupled optimization of spatial perception and semantic reasoning within shared model parameters. To overcome this, we propose UniDriveVLA, a Unified Driving Vision-Language-Action model based on Mixture-of-Transformers that addresses the perception-reasoning conflict via expert decoupling. Specifically, it comprises three experts for driving understanding, scene perception, and action planning, which are coordinated through masked joint attention. In addition, we combine a sparse perception paradigm with a three-stage progressive training strategy to improve spatial perception while maintaining semantic reasoning capability. Extensive experiments show that UniDriveVLA achieves state-of-the-art performance in open-loop evaluation on nuScenes and closed-loop evaluation on Bench2Drive. Moreover, it demonstrates strong performance across a broad range of perception, prediction, and understanding tasks, including 3D detection, online mapping, motion forecasting, and driving-oriented VQA, highlighting its broad applicability as a unified model for autonomous driving. Code and model have been released at https://github.com/xiaomi-research/unidrivevla
Mixture-of-Depths Attention
Mar 16, 2026Scaling depth is a key driver for large language models (LLMs). Yet, as LLMs become deeper, they often suffer from signal degradation: informative features formed in shallow layers are gradually diluted by repeated residual updates, making them harder to recover in deeper layers. We introduce mixture-of-depths attention (MoDA), a mechanism that allows each attention head to attend to sequence KV pairs at the current layer and depth KV pairs from preceding layers. We further describe a hardware-efficient algorithm for MoDA that resolves non-contiguous memory-access patterns, achieving 97.3% of FlashAttention-2's efficiency at a sequence length of 64K. Experiments on 1.5B-parameter models demonstrate that MoDA consistently outperforms strong baselines. Notably, it improves average perplexity by 0.2 across 10 validation benchmarks and increases average performance by 2.11% on 10 downstream tasks, with a negligible 3.7% FLOPs computational overhead. We also find that combining MoDA with post-norm yields better performance than using it with pre-norm. These results suggest that MoDA is a promising primitive for depth scaling. Code is released at https://github.com/hustvl/MoDA .
DiffusionVL: Translating Any Autoregressive Models into Diffusion Vision Language Models
Dec 24, 2025In recent multimodal research, the diffusion paradigm has emerged as a promising alternative to the autoregressive paradigm (AR), owing to its unique decoding advantages. However, due to the capability limitations of the base diffusion language model, the performance of the diffusion vision language model (dVLM) still lags significantly behind that of mainstream models. This leads to a simple yet fundamental question: Is it possible to construct dVLMs based on existing powerful AR models? In response, we propose DiffusionVL, a dVLM family that could be translated from any powerful AR models. Through simple fine-tuning, we successfully adapt AR pre-trained models into the diffusion paradigm. This approach yields two key observations: (1) The paradigm shift from AR-based multimodal models to diffusion is remarkably effective. (2) Direct conversion of an AR language model to a dVLM is also feasible, achieving performance competitive with LLaVA-style visual-instruction-tuning. Further, we introduce a block-decoding design into dVLMs that supports arbitrary-length generation and KV cache reuse, achieving a significant inference speedup. We conduct a large number of experiments. Despite training with less than 5% of the data required by prior methods, DiffusionVL achieves a comprehensive performance improvement-a 34.4% gain on the MMMU-Pro (vision) bench and 37.5% gain on the MME (Cog.) bench-alongside a 2x inference speedup. The model and code are released at https://github.com/hustvl/DiffusionVL.
InfiniteVL: Synergizing Linear and Sparse Attention for Highly-Efficient, Unlimited-Input Vision-Language Models
Dec 09, 2025Window attention and linear attention represent two principal strategies for mitigating the quadratic complexity and ever-growing KV cache in Vision-Language Models (VLMs). However, we observe that window-based VLMs suffer performance degradation when sequence length exceeds the window size, while linear attention underperforms on information-intensive tasks such as OCR and document understanding. To overcome these limitations, we propose InfiniteVL, a linear-complexity VLM architecture that synergizes sliding window attention (SWA) with Gated DeltaNet. For achieving competitive multimodal performance under constrained resources, we design a three-stage training strategy comprising distillation pretraining, instruction tuning, and long-sequence SFT. Remarkably, using less than 2\% of the training data required by leading VLMs, InfiniteVL not only substantially outperforms previous linear-complexity VLMs but also matches the performance of leading Transformer-based VLMs, while demonstrating effective long-term memory retention. Compared to similar-sized Transformer-based VLMs accelerated by FlashAttention-2, InfiniteVL achieves over 3.6\times inference speedup while maintaining constant latency and memory footprint. In streaming video understanding scenarios, it sustains a stable 24 FPS real-time prefill speed while preserving long-term memory cache. Code and models are available at https://github.com/hustvl/InfiniteVL.
DiffusionDriveV2: Reinforcement Learning-Constrained Truncated Diffusion Modeling in End-to-End Autonomous Driving
Dec 08, 2025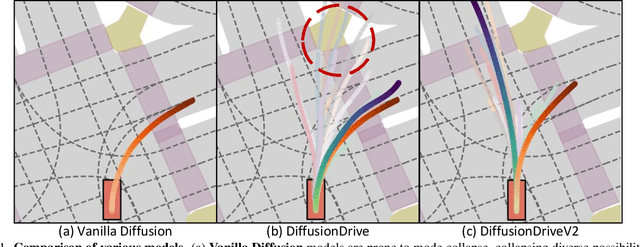
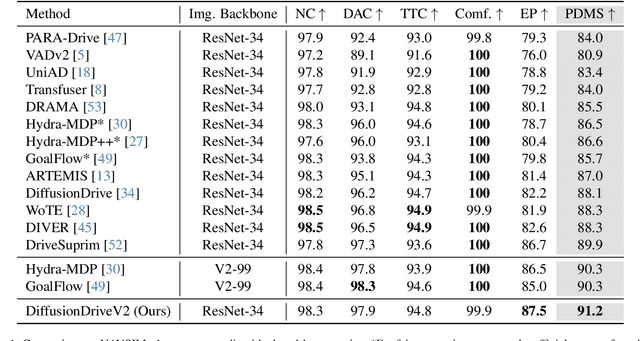
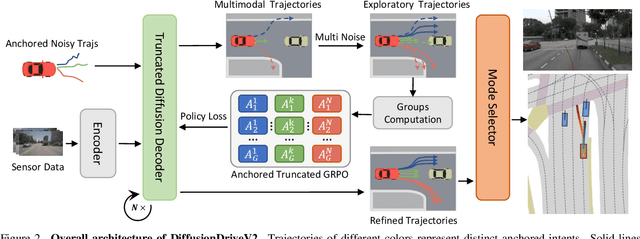
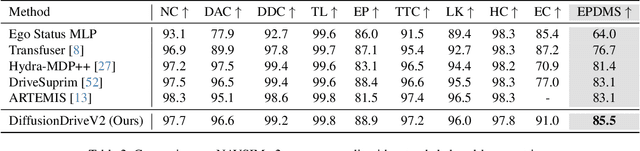
Generative diffusion models for end-to-end autonomous driving often suffer from mode collapse, tending to generate conservative and homogeneous behaviors. While DiffusionDrive employs predefined anchors representing different driving intentions to partition the action space and generate diverse trajectories, its reliance on imitation learning lacks sufficient constraints, resulting in a dilemma between diversity and consistent high quality. In this work, we propose DiffusionDriveV2, which leverages reinforcement learning to both constrain low-quality modes and explore for superior trajectories. This significantly enhances the overall output quality while preserving the inherent multimodality of its core Gaussian Mixture Model. First, we use scale-adaptive multiplicative noise, ideal for trajectory planning, to promote broad exploration. Second, we employ intra-anchor GRPO to manage advantage estimation among samples generated from a single anchor, and inter-anchor truncated GRPO to incorporate a global perspective across different anchors, preventing improper advantage comparisons between distinct intentions (e.g., turning vs. going straight), which can lead to further mode collapse. DiffusionDriveV2 achieves 91.2 PDMS on the NAVSIM v1 dataset and 85.5 EPDMS on the NAVSIM v2 dataset in closed-loop evaluation with an aligned ResNet-34 backbone, setting a new record. Further experiments validate that our approach resolves the dilemma between diversity and consistent high quality for truncated diffusion models, achieving the best trade-off. Code and model will be available at https://github.com/hustvl/DiffusionDriveV2
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
MaTVLM: Hybrid Mamba-Transformer for Efficient Vision-Language Modeling
Mar 17, 2025With the advancement of RNN models with linear complexity, the quadratic complexity challenge of transformers has the potential to be overcome. Notably, the emerging Mamba-2 has demonstrated competitive performance, bridging the gap between RNN models and transformers. However, due to sequential processing and vanishing gradients, RNN models struggle to capture long-range dependencies, limiting contextual understanding. This results in slow convergence, high resource demands, and poor performance on downstream understanding and complex reasoning tasks. In this work, we present a hybrid model MaTVLM by substituting a portion of the transformer decoder layers in a pre-trained VLM with Mamba-2 layers. Leveraging the inherent relationship between attention and Mamba-2, we initialize Mamba-2 with corresponding attention weights to accelerate convergence. Subsequently, we employ a single-stage distillation process, using the pre-trained VLM as the teacher model to transfer knowledge to the MaTVLM, further enhancing convergence speed and performance. Furthermore, we investigate the impact of differential distillation loss within our training framework. We evaluate the MaTVLM on multiple benchmarks, demonstrating competitive performance against the teacher model and existing VLMs while surpassing both Mamba-based VLMs and models of comparable parameter scales. Remarkably, the MaTVLM achieves up to 3.6x faster inference than the teacher model while reducing GPU memory consumption by 27.5%, all without compromising performance. Code and models are released at http://github.com/hustvl/MaTVLM.
OmniMamba: Efficient and Unified Multimodal Understanding and Generation via State Space Models
Mar 11, 2025Recent advancements in unified multimodal understanding and visual generation (or multimodal generation) models have been hindered by their quadratic computational complexity and dependence on large-scale training data. We present OmniMamba, the first linear-architecture-based multimodal generation model that generates both text and images through a unified next-token prediction paradigm. The model fully leverages Mamba-2's high computational and memory efficiency, extending its capabilities from text generation to multimodal generation. To address the data inefficiency of existing unified models, we propose two key innovations: (1) decoupled vocabularies to guide modality-specific generation, and (2) task-specific LoRA for parameter-efficient adaptation. Furthermore, we introduce a decoupled two-stage training strategy to mitigate data imbalance between two tasks. Equipped with these techniques, OmniMamba achieves competitive performance with JanusFlow while surpassing Show-o across benchmarks, despite being trained on merely 2M image-text pairs, which is 1,000 times fewer than Show-o. Notably, OmniMamba stands out with outstanding inference efficiency, achieving up to a 119.2 times speedup and 63% GPU memory reduction for long-sequence generation compared to Transformer-based counterparts. Code and models are released at https://github.com/hustvl/OmniMamba
RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning
Feb 18, 2025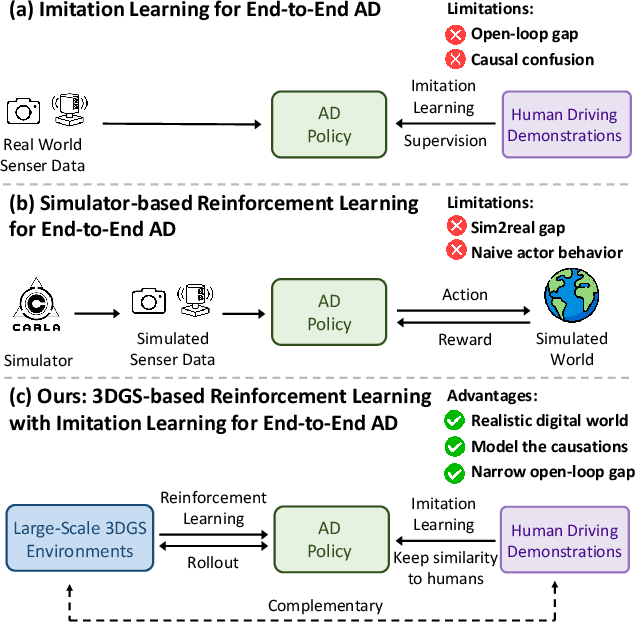
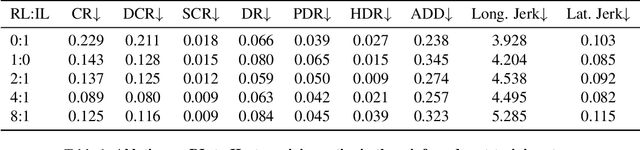
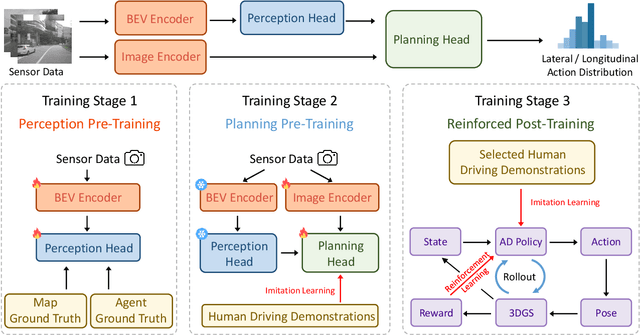
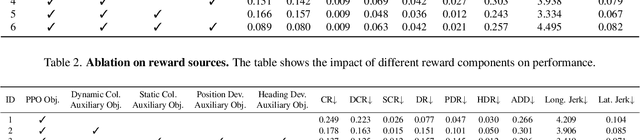
Existing end-to-end autonomous driving (AD) algorithms typically follow the Imitation Learning (IL) paradigm, which faces challenges such as causal confusion and the open-loop gap. In this work, we establish a 3DGS-based closed-loop Reinforcement Learning (RL) training paradigm. By leveraging 3DGS techniques, we construct a photorealistic digital replica of the real physical world, enabling the AD policy to extensively explore the state space and learn to handle out-of-distribution scenarios through large-scale trial and error. To enhance safety, we design specialized rewards that guide the policy to effectively respond to safety-critical events and understand real-world causal relationships. For better alignment with human driving behavior, IL is incorporated into RL training as a regularization term. We introduce a closed-loop evaluation benchmark consisting of diverse, previously unseen 3DGS environments. Compared to IL-based methods, RAD achieves stronger performance in most closed-loop metrics, especially 3x lower collision rate. Abundant closed-loop results are presented at https://hgao-cv.github.io/RAD.
Multimodal Mamba: Decoder-only Multimodal State Space Model via Quadratic to Linear Distillation
Feb 18, 2025Recent Multimodal Large Language Models (MLLMs) have achieved remarkable performance but face deployment challenges due to their quadratic computational complexity, growing Key-Value cache requirements, and reliance on separate vision encoders. We propose mmMamba, a framework for developing linear-complexity native multimodal state space models through progressive distillation from existing MLLMs using moderate academic computational resources. Our approach enables the direct conversion of trained decoder-only MLLMs to linear-complexity architectures without requiring pre-trained RNN-based LLM or vision encoders. We propose an seeding strategy to carve Mamba from trained Transformer and a three-stage distillation recipe, which can effectively transfer the knowledge from Transformer to Mamba while preserving multimodal capabilities. Our method also supports flexible hybrid architectures that combine Transformer and Mamba layers for customizable efficiency-performance trade-offs. Distilled from the Transformer-based decoder-only HoVLE, mmMamba-linear achieves competitive performance against existing linear and quadratic-complexity VLMs, while mmMamba-hybrid further improves performance significantly, approaching HoVLE's capabilities. At 103K tokens, mmMamba-linear demonstrates 20.6$\times$ speedup and 75.8% GPU memory reduction compared to HoVLE, while mmMamba-hybrid achieves 13.5$\times$ speedup and 60.2% memory savings. Code and models are released at https://github.com/hustvl/mmMamba