 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-Perfect Depth with Semantics-Prompted Diffusion Transformers
Oct 08, 2025

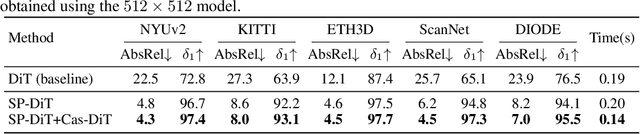
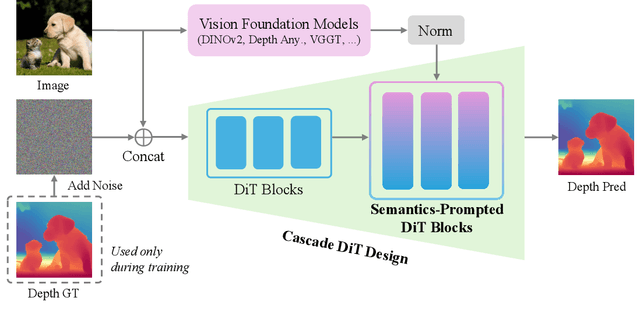
This paper presents Pixel-Perfect Depth, a monocular depth estimation model based on pixel-space diffusion generation that produces high-quality, flying-pixel-free point clouds from estimated depth maps. Current generative depth estimation models fine-tune Stable Diffusion and achieve impressive performance. However, they require a VAE to compress depth maps into latent space, which inevitably introduces \textit{flying pixels} at edges and details. Our model addresses this challenge by directly performing diffusion generation in the pixel space, avoiding VAE-induced artifacts. To overcome the high complexity associated with pixel-space generation, we introduce two novel designs: 1) Semantics-Prompted Diffusion Transformers (SP-DiT), which incorporate semantic representations from vision foundation models into DiT to prompt the diffusion process, thereby preserving global semantic consistency while enhancing fine-grained visual details; and 2) Cascade DiT Design that progressively increases the number of tokens to further enhance efficiency and accuracy. Our model achieves the best performance among all published generative models across five benchmarks, and significantly outperforms all other models in edge-aware point cloud evaluation.
Multimodal Prototype Alignment for Semi-supervised Pathology Image Segmentation
Aug 27, 2025Pathological image segmentation faces numerous challenges, particularly due to ambiguous semantic boundaries and the high cost of pixel-level annotations. Although recent semi-supervised methods based on consistency regularization (e.g., UniMatch) have made notable progress, they mainly rely on perturbation-based consistency within the image modality, making it difficult to capture high-level semantic priors, especially in structurally complex pathology images. To address these limitations, we propose MPAMatch - a novel segmentation framework that performs pixel-level contrastive learning under a multimodal prototype-guided supervision paradigm. The core innovation of MPAMatch lies in the dual contrastive learning scheme between image prototypes and pixel labels, and between text prototypes and pixel labels, providing supervision at both structural and semantic levels. This coarse-to-fine supervisory strategy not only enhances the discriminative capability on unlabeled samples but also introduces the text prototype supervision into segmentation for the first time, significantly improving semantic boundary modeling. In addition, we reconstruct the classic segmentation architecture (TransUNet) by replacing its ViT backbone with a pathology-pretrained foundation model (Uni), enabling more effective extraction of pathology-relevant features. Extensive experiments on GLAS, EBHI-SEG-GLAND, EBHI-SEG-CANCER, and KPI show MPAMatch's superiority over state-of-the-art methods, validating its dual advantages in structural and semantic modeling.
TransLight: Image-Guided Customized Lighting Control with Generative Decoupling
Aug 20, 2025Most existing illumination-editing approaches fail to simultaneously provide customized control of light effects and preserve content integrity. This makes them less effective for practical lighting stylization requirements, especially in the challenging task of transferring complex light effects from a reference image to a user-specified target image. To address this problem, we propose TransLight, a novel framework that enables high-fidelity and high-freedom transfer of light effects. Extracting the light effect from the reference image is the most critical and challenging step in our method. The difficulty lies in the complex geometric structure features embedded in light effects that are highly coupled with content in real-world scenarios. To achieve this, we first present Generative Decoupling, where two fine-tuned diffusion models are used to accurately separate image content and light effects, generating a newly curated, million-scale dataset of image-content-light triplets. Then, we employ IC-Light as the generative model and train our model with our triplets, injecting the reference lighting image as an additional conditioning signal. The resulting TransLight model enables customized and natural transfer of diverse light effects. Notably, by thoroughly disentangling light effects from reference images, our generative decoupling strategy endows TransLight with highly flexible illumination control. Experimental results establish TransLight as the first method to successfully transfer light effects across disparate images, delivering more customized illumination control than existing techniques and charting new directions for research in illumination harmonization and editing.
LENS: Learning to Segment Anything with Unified Reinforced Reasoning
Aug 19, 2025Text-prompted image segmentation enables fine-grained visual understanding and is critical for applications such as human-computer interaction and robotics. However, existing supervised fine-tuning methods typically ignore explicit chain-of-thought (CoT) reasoning at test time, which limits their ability to generalize to unseen prompts and domains. To address this issue, we introduce LENS, a scalable reinforcement-learning framework that jointly optimizes the reasoning process and segmentation in an end-to-end manner. We propose unified reinforcement-learning rewards that span sentence-, box-, and segment-level cues, encouraging the model to generate informative CoT rationales while refining mask quality. Using a publicly available 3-billion-parameter vision-language model, i.e., Qwen2.5-VL-3B-Instruct, LENS achieves an average cIoU of 81.2% on the RefCOCO, RefCOCO+, and RefCOCOg benchmarks, outperforming the strong fine-tuned method, i.e., GLaMM, by up to 5.6%. These results demonstrate that RL-driven CoT reasoning serves as a robust prior for text-prompted segmentation and offers a practical path toward more generalizable Segment Anything models. Code is available at https://github.com/hustvl/LENS.
Deformable Attention Graph Representation Learning for Histopathology Whole Slide Image Analysis
Aug 07, 2025Accurate classification of Whole Slide Images (WSIs) and Regions of Interest (ROIs) is a fundamental challenge in computational pathology. While mainstream approaches often adopt Multiple Instance Learning (MIL), they struggle to capture the spatial dependencies among tissue structures. Graph Neural Networks (GNNs) have emerged as a solution to model inter-instance relationships, yet most rely on static graph topologies and overlook the physical spatial positions of tissue patches. Moreover, conventional attention mechanisms lack specificity, limiting their ability to focus on structurally relevant regions. In this work, we propose a novel GNN framework with deformable attention for pathology image analysis. We construct a dynamic weighted directed graph based on patch features, where each node aggregates contextual information from its neighbors via attention-weighted edges. Specifically, we incorporate learnable spatial offsets informed by the real coordinates of each patch, enabling the model to adaptively attend to morphologically relevant regions across the slide. This design significantly enhances the contextual field while preserving spatial specificity. Our framework achieves state-of-the-art performance on four benchmark datasets (TCGA-COAD, BRACS, gastric intestinal metaplasia grading, and intestinal ROI classification), demonstrating the power of deformable attention in capturing complex spatial structures in WSIs and ROIs.
Subspecialty-Specific Foundation Model for Intelligent Gastrointestinal Pathology
May 28, 2025Gastrointestinal (GI) diseases represent a clinically significant burden, necessitating precise diagnostic approaches to optimize patient outcomes. Conventional histopathological diagnosis, heavily reliant on the subjective interpretation of pathologists, suffers from limited reproducibility and diagnostic variability. To overcome these limitations and address the lack of pathology-specific foundation models for GI diseases, we develop Digepath, a specialized foundation model for GI pathology. Our framework introduces a dual-phase iterative optimization strategy combining pretraining with fine-screening, specifically designed to address the detection of sparsely distributed lesion areas in whole-slide images. Digepath is pretrained on more than 353 million image patches from over 200,000 hematoxylin and eosin-stained slides of GI diseases. It attains state-of-the-art performance on 33 out of 34 tasks related to GI pathology, including pathological diagnosis, molecular prediction, gene mutation prediction, and prognosis evaluation, particularly in diagnostically ambiguous cases and resolution-agnostic tissue classification.We further translate the intelligent screening module for early GI cancer and achieve near-perfect 99.6% sensitivity across 9 independent medical institutions nationwide. The outstanding performance of Digepath highlights its potential to bridge critical gaps in histopathological practice. This work not only advances AI-driven precision pathology for GI diseases but also establishes a transferable paradigm for other pathology subspecialties.
GroundingSuite: Measuring Complex Multi-Granular Pixel Grounding
Mar 13, 2025Pixel grounding, encompassing tasks such as Referring Expression Segmentation (RES), has garnered considerable attention due to its immense potential for bridging the gap between vision and language modalities. However, advancements in this domain are currently constrained by limitations inherent in existing datasets, including limited object categories, insufficient textual diversity, and a scarcity of high-quality annotations. To mitigate these limitations, we introduce GroundingSuite, which comprises: (1) an automated data annotation framework leveraging multiple Vision-Language Model (VLM) agents; (2) a large-scale training dataset encompassing 9.56 million diverse referring expressions and their corresponding segmentations; and (3) a meticulously curated evaluation benchmark consisting of 3,800 images. The GroundingSuite training dataset facilitates substantial performance improvements, enabling models trained on it to achieve state-of-the-art results. Specifically, a cIoU of 68.9 on gRefCOCO and a gIoU of 55.3 on RefCOCOm. Moreover, the GroundingSuite annotation framework demonstrates superior efficiency compared to the current leading data annotation method, i.e., $4.5 \times$ faster than the GLaMM.
Multimodal Distillation-Driven Ensemble Learning for Long-Tailed Histopathology Whole Slide Images Analysis
Mar 02, 2025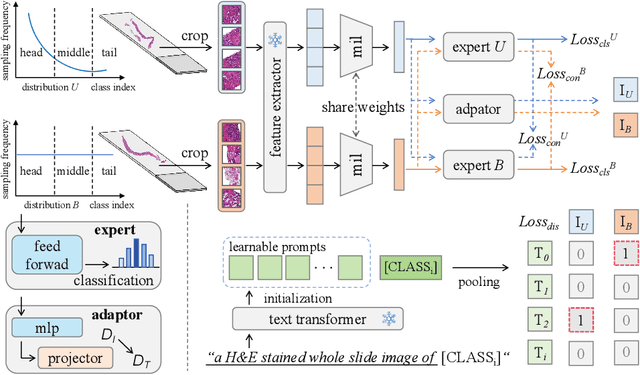


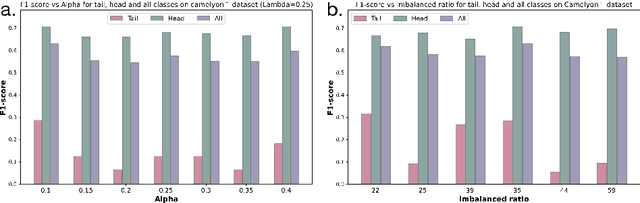
Multiple Instance Learning (MIL) plays a significant role in computational pathology, enabling weakly supervised analysis of Whole Slide Image (WSI) datasets. The field of WSI analysis is confronted with a severe long-tailed distribution problem, which significantly impacts the performance of classifiers. Long-tailed distributions lead to class imbalance, where some classes have sparse samples while others are abundant, making it difficult for classifiers to accurately identify minority class samples. To address this issue, we propose an ensemble learning method based on MIL, which employs expert decoders with shared aggregators and consistency constraints to learn diverse distributions and reduce the impact of class imbalance on classifier performance. Moreover, we introduce a multimodal distillation framework that leverages text encoders pre-trained on pathology-text pairs to distill knowledge and guide the MIL aggregator in capturing stronger semantic features relevant to class information. To ensure flexibility, we use learnable prompts to guide the distillation process of the pre-trained text encoder, avoiding limitations imposed by specific prompts. Our method, MDE-MIL, integrates multiple expert branches focusing on specific data distributions to address long-tailed issues. Consistency control ensures generalization across classes. Multimodal distillation enhances feature extraction. Experiments on Camelyon+-LT and PANDA-LT datasets show it outperforms state-of-the-art methods.
Dynamic Hypergraph Representation for Bone Metastasis Cancer Analysis
Jan 28, 2025Bone metastasis analysis is a significant challenge in pathology and plays a critical role in determining patient quality of life and treatment strategies. The microenvironment and specific tissue structures are essential for pathologists to predict the primary bone cancer origins and primary bone cancer subtyping. By digitizing bone tissue sections into whole slide images (WSIs) and leveraging deep learning to model slide embeddings, this analysis can be enhanced. However, tumor metastasis involves complex multivariate interactions with diverse bone tissue structures, which traditional WSI analysis methods such as multiple instance learning (MIL) fail to capture. Moreover, graph neural networks (GNNs), limited to modeling pairwise relationships, are hard to represent high-order biological associations. To address these challenges, we propose a dynamic hypergraph neural network (DyHG) that overcomes the edge construction limitations of traditional graph representations by connecting multiple nodes via hyperedges. A low-rank strategy is used to reduce the complexity of parameters in learning hypergraph structures, while a Gumbel-Softmax-based sampling strategy optimizes the patch distribution across hyperedges. An MIL aggregator is then used to derive a graph-level embedding for comprehensive WSI analysis. To evaluate the effectiveness of DyHG, we construct two large-scale datasets for primary bone cancer origins and subtyping classification based on real-world bone metastasis scenarios. Extensive experiments demonstrate that DyHG significantly outperforms state-of-the-art (SOTA) baselines, showcasing its ability to model complex biological interactions and improve the accuracy of bone metastasis analysis.
MergeUp-augmented Semi-Weakly Supervised Learning for WSI Classification
Aug 23, 2024



Recent advancements in computational pathology and artificial intelligence have significantly improved whole slide image (WSI) classification. However, the gigapixel resolution of WSIs and the scarcity of manual annotations present substantial challenges. Multiple instance learning (MIL) is a promising weakly supervised learning approach for WSI classification. Recently research revealed employing pseudo bag augmentation can encourage models to learn various data, thus bolstering models' performance. While directly inheriting the parents' labels can introduce more noise by mislabeling in training. To address this issue, we translate the WSI classification task from weakly supervised learning to semi-weakly supervised learning, termed SWS-MIL, where adaptive pseudo bag augmentation (AdaPse) is employed to assign labeled and unlabeled data based on a threshold strategy. Using the "student-teacher" pattern, we introduce a feature augmentation technique, MergeUp, which merges bags with low-priority bags to enhance inter-category information, increasing training data diversity. Experimental results on the CAMELYON-16, BRACS, and TCGA-LUNG datasets demonstrate the superiority of our method over existing state-of-the-art approaches, affirming its efficacy in WSI classification.