 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransLight: Image-Guided Customized Lighting Control with Generative Decoupling
Aug 20, 2025Most existing illumination-editing approaches fail to simultaneously provide customized control of light effects and preserve content integrity. This makes them less effective for practical lighting stylization requirements, especially in the challenging task of transferring complex light effects from a reference image to a user-specified target image. To address this problem, we propose TransLight, a novel framework that enables high-fidelity and high-freedom transfer of light effects. Extracting the light effect from the reference image is the most critical and challenging step in our method. The difficulty lies in the complex geometric structure features embedded in light effects that are highly coupled with content in real-world scenarios. To achieve this, we first present Generative Decoupling, where two fine-tuned diffusion models are used to accurately separate image content and light effects, generating a newly curated, million-scale dataset of image-content-light triplets. Then, we employ IC-Light as the generative model and train our model with our triplets, injecting the reference lighting image as an additional conditioning signal. The resulting TransLight model enables customized and natural transfer of diverse light effects. Notably, by thoroughly disentangling light effects from reference images, our generative decoupling strategy endows TransLight with highly flexible illumination control. Experimental results establish TransLight as the first method to successfully transfer light effects across disparate images, delivering more customized illumination control than existing techniques and charting new directions for research in illumination harmonization and editing.
LENS: Learning to Segment Anything with Unified Reinforced Reasoning
Aug 19, 2025Text-prompted image segmentation enables fine-grained visual understanding and is critical for applications such as human-computer interaction and robotics. However, existing supervised fine-tuning methods typically ignore explicit chain-of-thought (CoT) reasoning at test time, which limits their ability to generalize to unseen prompts and domains. To address this issue, we introduce LENS, a scalable reinforcement-learning framework that jointly optimizes the reasoning process and segmentation in an end-to-end manner. We propose unified reinforcement-learning rewards that span sentence-, box-, and segment-level cues, encouraging the model to generate informative CoT rationales while refining mask quality. Using a publicly available 3-billion-parameter vision-language model, i.e., Qwen2.5-VL-3B-Instruct, LENS achieves an average cIoU of 81.2% on the RefCOCO, RefCOCO+, and RefCOCOg benchmarks, outperforming the strong fine-tuned method, i.e., GLaMM, by up to 5.6%. These results demonstrate that RL-driven CoT reasoning serves as a robust prior for text-prompted segmentation and offers a practical path toward more generalizable Segment Anything models. Code is available at https://github.com/hustvl/LENS.
GroundingSuite: Measuring Complex Multi-Granular Pixel Grounding
Mar 13, 2025Pixel grounding, encompassing tasks such as Referring Expression Segmentation (RES), has garnered considerable attention due to its immense potential for bridging the gap between vision and language modalities. However, advancements in this domain are currently constrained by limitations inherent in existing datasets, including limited object categories, insufficient textual diversity, and a scarcity of high-quality annotations. To mitigate these limitations, we introduce GroundingSuite, which comprises: (1) an automated data annotation framework leveraging multiple Vision-Language Model (VLM) agents; (2) a large-scale training dataset encompassing 9.56 million diverse referring expressions and their corresponding segmentations; and (3) a meticulously curated evaluation benchmark consisting of 3,800 images. The GroundingSuite training dataset facilitates substantial performance improvements, enabling models trained on it to achieve state-of-the-art results. Specifically, a cIoU of 68.9 on gRefCOCO and a gIoU of 55.3 on RefCOCOm. Moreover, the GroundingSuite annotation framework demonstrates superior efficiency compared to the current leading data annotation method, i.e., $4.5 \times$ faster than the GLaMM.
ControlAR: Controllable Image Generation with Autoregressive Models
Oct 03, 2024



Autoregressive (AR) models have reformulated image generation as next-token prediction, demonstrating remarkable potential and emerging as strong competitors to diffusion models. However, control-to-image generation, akin to ControlNet, remains largely unexplored within AR models. Although a natural approach, inspired by advancements in Large Language Models, is to tokenize control images into tokens and prefill them into the autoregressive model before decoding image tokens, it still falls short in generation quality compared to ControlNet and suffers from inefficiency. To this end, we introduce ControlAR, an efficient and effective framework for integrating spatial controls into autoregressive image generation models. Firstly, we explore control encoding for AR models and propose a lightweight control encoder to transform spatial inputs (e.g., canny edges or depth maps) into control tokens. Then ControlAR exploits the conditional decoding method to generate the next image token conditioned on the per-token fusion between control and image tokens, similar to positional encodings. Compared to prefilling tokens, using conditional decoding significantly strengthens the control capability of AR models but also maintains the model's efficiency. Furthermore, the proposed ControlAR surprisingly empowers AR models with arbitrary-resolution image generation via conditional decoding and specific controls. Extensive experiments can demonstrate the controllability of the proposed ControlAR for the autoregressive control-to-image generation across diverse inputs, including edges, depths, and segmentation masks. Furthermore, both quantitative and qualitative results indicate that ControlAR surpasses previous state-of-the-art controllable diffusion models, e.g., ControlNet++. Code, models, and demo will soon be available at https://github.com/hustvl/ControlAR.
EVF-SAM: Early Vision-Language Fusion for Text-Prompted Segment Anything Model
Jun 28, 2024



Segment Anything Model (SAM) has attracted widespread attention for its superior interactive segmentation capabilities with visual prompts while lacking further exploration of text prompts. In this paper, we empirically investigate what text prompt encoders (e.g., CLIP or LLM) are good for adapting SAM for referring expression segmentation and introduce the Early Vision-language Fusion-based SAM (EVF-SAM). EVF-SAM is a simple yet effective referring segmentation method which exploits multimodal prompts (i.e., image and text) and comprises a pre-trained vision-language model to generate referring prompts and a SAM model for segmentation. Surprisingly, we observe that: (1) multimodal prompts and (2) vision-language models with early fusion (e.g., BEIT-3) are beneficial for prompting SAM for accurate referring segmentation. Our experiments show that the proposed EVF-SAM based on BEIT-3 can obtain state-of-the-art performance on RefCOCO/+/g for referring expression segmentation and demonstrate the superiority of prompting SAM with early vision-language fusion. In addition, the proposed EVF-SAM with 1.32B parameters achieves remarkably higher performance while reducing nearly 82% of parameters compared to previous SAM methods based on large multimodal models.
Weakly-supervised Instance Segmentation via Class-agnostic Learning with Salient Images
Apr 04, 2021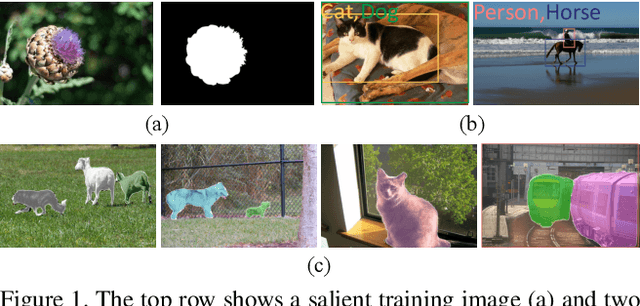
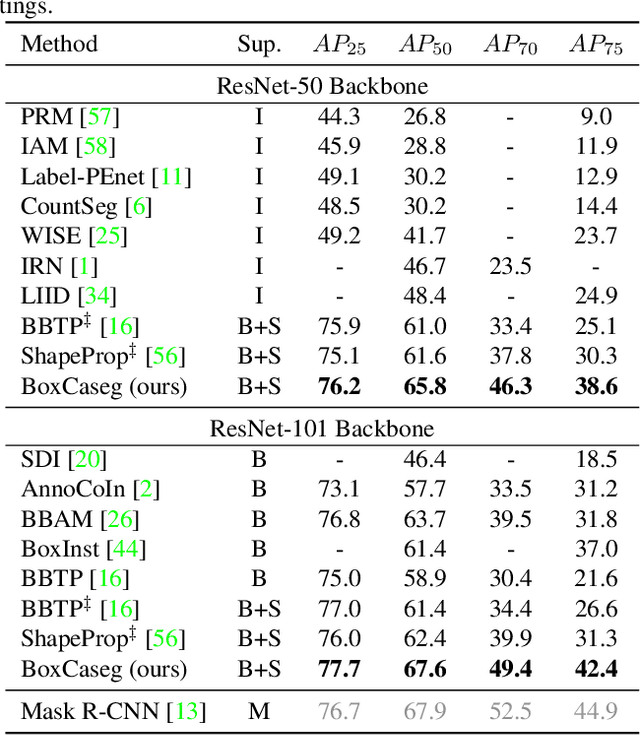
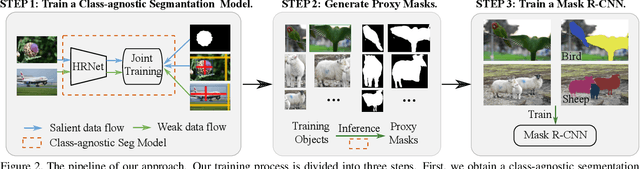

Humans have a strong class-agnostic object segmentation ability and can outline boundaries of unknown objects precisely, which motivates us to propose a box-supervised class-agnostic object segmentation (BoxCaseg) based solution for weakly-supervised instance segmentation. The BoxCaseg model is jointly trained using box-supervised images and salient images in a multi-task learning manner. The fine-annotated salient images provide class-agnostic and precise object localization guidance for box-supervised images. The object masks predicted by a pretrained BoxCaseg model are refined via a novel merged and dropped strategy as proxy ground truth to train a Mask R-CNN for weakly-supervised instance segmentation. Only using $7991$ salient images, the weakly-supervised Mask R-CNN is on par with fully-supervised Mask R-CNN on PASCAL VOC and significantly outperforms previous state-of-the-art box-supervised instance segmentation methods on COCO. The source code, pretrained models and datasets are available at \url{https://github.com/hustvl/BoxCaseg}.